

Классификация объектов на две или более категории — важная задача в машинном обучении. Способов классификации множество; в этой статье расскажем про простой, но эффективный — метод опорных векторов (SVM, Support Vector Machine).

Что такое метод опорных векторов и как SVM классифицирует данные
Метод опорных векторов был разработан советским и американским математиком Владимиром Вапником и его коллегами. В статье «Support Vector Networks», опубликованной в 1995 году, описаны основные концепции SVM и раскрыта их эффективность в задачах классификации данных.
Метод опорных векторов — это алгоритм машинного обучения, применяемый для задач линейной и нелинейной классификации, регрессии и обнаружения аномальных данных. С помощью этого метода можно классифицировать текст, изображения, обнаружить спам, идентифицировать почерк, анализировать экспрессии генов, распознавать лица, делать прогнозы и так далее. SVM адаптируется и эффективен в различных приложениях, поскольку может управлять многомерными данными и нелинейными отношениями.
Чтобы понять, как работает алгоритм, представим, что у нас есть набор точек на бумаге и эти точки принадлежат двум разным группам. Например, это картинки с кошками и собаками. SVM помогает нарисовать линию (или, в более сложных случаях, плоскость или гиперплоскость), которая максимально четко разделяет эти две группы точек. В случае с животными алгоритм, используя характеристики — размер ушей, форма хвоста и т. д., — разделит изображения так, что все кошки окажутся с одной стороны, а все собаки — с другой.
В работе с данным методом используются основные термины:
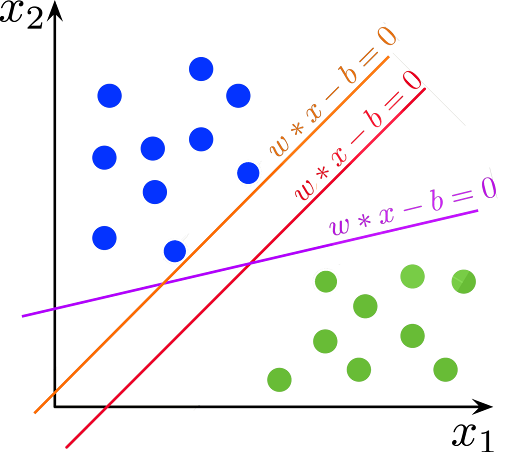
- Гиперплоскость — граница, которая используется для разделения точек данных разных классов в пространстве признаков. В случае линейных классификаций это будет линейное уравнение, то есть wx+b = 0.
- Опорные векторы — ближайшие точки данных к гиперплоскости, которые играют решающую роль при выборе гиперплоскости и зазора.
- Зазор — расстояние между опорными векторами и гиперплоскостью. Основная цель алгоритма SVM — максимизировать этот зазор. Более широкий зазор указывает на лучшую способность классификации.
- Ядро — математическая функция, которая используется в SVM для отображения исходных точек входных данных в более высокоразмерное пространство признаков, где гиперплоскость можно легко найти, даже если точки данных не являются линейно разделимыми в исходном пространстве.
Первый шаг при работе с методом опорных векторов — это сбор и подготовка данных. На этом этапе нужно выбрать объекты, которые будут использоваться для представления данных. Также здесь можно масштабировать или преобразовать данные, чтобы гарантировать, что все объекты находятся в одном масштабе.
Далее требуется обучение модели. SVM получает обучающий набор данных, где каждый объект уже помечен правильной категорией. Алгоритм пытается найти гиперплоскость, которая максимально отделяет точки одного класса от точек другого класса. Для этого он находит гиперплоскость с наибольшим запасом или расстоянием между точками двух классов.
После обучения модели ее можно использовать для работы с новыми данными. Чтобы сделать прогноз, новая точка данных преобразуется в то же пространство признаков, что и обучающие данные, а затем метка класса определяется на основе того, на какой стороне гиперплоскости находится точка.
Типы SVM
Трюк с ядром
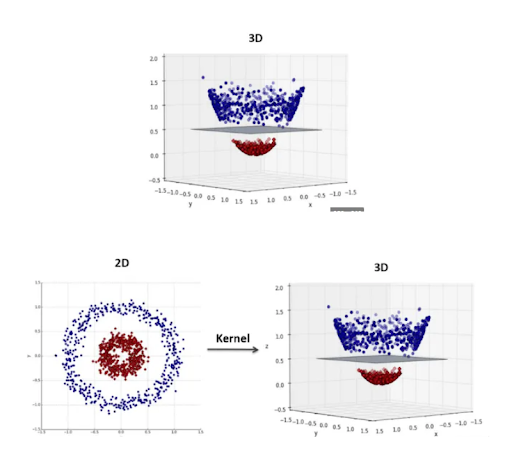
Иногда данные так расположены, что нельзя провести прямую линию, которая бы четко разделила их на две группы. Например, если точки расположены в виде окружности, то прямая линия не сможет их разделить на внутренние и внешние.
В этом случае SVM может использовать нелинейные функции для преобразования данных в более высокоразмерное пространство. Визуально это выглядит так, как будто двумерная окружность вытягивается в трёхмерное пространство и превращается в цилиндр. В таком виде плоскость может легко разделить точки внутри цилиндра и снаружи.
Это называется «трюк с ядром».
Ядра позволяют SVM быть более гибким и мощным инструментом для классификации сложных наборов данных. Их типы:
- линейное ядро — используется, когда данные можно разделить прямой линией;
- полиномиальное ядро — позволяет разделять данные с помощью кривых линий. Полиномы разных степеней создают разные формы кривых;
- радиальное базисное ядро (RBF) — одно из самых популярных ядер, которое хорошо работает в большинстве случаев. Оно позволяет разделять данные с помощью окружностей или сфер;
- сигмоидальное ядро — используется в нейронных сетях и также может применяться в SVM для определенных типов данных.

Преимущества SVM
Использование SVM в машинном обучении и классификации данных может значительно повысить точность и надежность модели, что делает ее ценным инструментом для множества различных приложений.
Одним из основных преимуществ SVM является способность находить гиперплоскость, которая максимально разделяет разные классы данных. Это обеспечивает очень точную классификацию и особенно полезно при работе со сложными данными.
Кроме того, SVM может обрабатывать данные с большим количеством шума и выбросов, что делает его устойчивым к сбоям. Он также имеет возможность обрабатывать несбалансированные наборы данных, что часто встречается во многих реальных задачах классификации.
Главное преимущество SVM — простота понимания, реализации и использования. На практике использование этого метода не требует углубленных знаний об оптимизации. Достаточно загрузить библиотеку Python, подготовить обучающие данные, подать их в функцию обучения и вызвать функцию предсказания для классификации новых объектов.
Области применения SVM
Метод опорных векторов используется в различных областях нашей жизни, где необходимо классифицировать данные.
Здравоохранение:
- Диагностика заболеваний: помогает классифицировать медицинские данные для диагностики заболеваний — рак, диабет, сердечно-сосудистые заболевания и другие.
- Анализ изображений: обработка и анализ медицинских изображений (МРТ, КТ) для выявления аномалий.
Финансовый сектор:
- Кредитный скоринг: оценка кредитоспособности клиентов на основе их финансовых данных.
- Обнаружение мошенничества: выявление подозрительных транзакций и мошенничества в банковских операциях.
Информационные технологии:
- Обработка естественного языка (NLP): классификация текстов, распознавание спама, анализ тональности.
- Распознавание изображений и видео.
Биоинформатика:
- Анализ геномных данных: классификация последовательностей ДНК и РНК, выявление генов, связанных с определенными заболеваниями.
- Прогнозирование структуры белков: моделирование и предсказание структуры белков на основе их аминокислотных последовательностей.
Розничная торговля:
- Анализ потребительского поведения: сегментация клиентов, предсказание предпочтений и покупательской активности.
- Рекомендательные системы: рекомендации товаров и услуг на основе истории покупок и предпочтений пользователей.
Маркетинг и реклама:
- Таргетинг: определение целевой аудитории для рекламы на основе демографических и поведенческих данных.
- Анализ эффективности рекламных кампаний: оценка воздействия и конверсии рекламных акций.
Компетенции для работы с методом опорных векторов
С SVM в своей работе сталкиваются дата-сайентисты, специалисты по машинному обучению, аналитики, научные сотрудники, программные инженеры, статистики, биоинформатики.
Для использования данного метода необходимы следующие навыки и знания:
- знание языков программирования — Python, R — и использование библиотек для машинного обучения (например, scikit-learn);
- хорошее понимание математических основ, включая линейную алгебру, оптимизацию и теорию вероятностей;
- знание алгоритмов машинного обучения и опыта их применения;
- навыки предварительной обработки, визуализации и анализа данных.
