


Если вы когда-нибудь сталкивались с «болотом данных» (data swamp), где ваши данные лежат в хаотичных папках, а любой сбой в процессе записи превращает вашу красивую таблицу в тыкву, то эта статья для вас. Расскажем об инструменте, который тихо, но уверенно меняет подходы к работе с большими данными, — Apache Iceberg.
Многие, особенно новички в ML, думают в первую очередь о моделях, алгоритмах и метриках. И это правильно! Но суровая правда в том, что качество вашей модели не может быть выше качества ваших данных. Чтобы данные были качественными, ими нужно эффективно управлять.
Представьте, что вы строите небоскреб (вашу ML-модель). Вы можете использовать самые лучшие материалы и нанять гениальных архитекторов, но если фундамент (ваши данные) трескается и проседает, все здание обречено. Apache Iceberg — это технология, которая помогает залить прочный и надежный фундамент для ваших данных в озере данных (Data Lake).
Что такое Apache Iceberg и зачем он нужен?
Начнем с простой аналогии. Представьте себе огромную библиотеку. В ней миллионы книг.

Старый подход (а-ля Hive FileSystem). У вас нет каталога. Книги (файлы с данными, например, в формате Parquet) просто расставлены по полкам (папкам в S3 или HDFS). Чтобы найти все книги по теме «Машинное обучение», вам нужно обойти всю библиотеку, заглянуть на каждую полку и прочитать название каждой книги. Это безумно долго и дорого. А если в процессе расстановки новых книг библиотекарь уронит стопку и уйдет на обед, у вас останется беспорядок и вы не будете знать, какие книги уже на полках, а какие — нет.
Новый подход (Apache Iceberg). У вас появляется подробный цифровой каталог. Этот каталог и есть Iceberg. Он не хранит сами книги, но он точно знает, где какая лежит. Он знает ее историю (когда ее добавили), ее версию (издание 1998 или 2022 года) и ее характеристики (жанр, автор). Теперь, чтобы найти все книги по «машинному обучению», вы делаете один быстрый запрос к каталогу, и он выдает вам точный список полок и мест. А если библиотекарь добавляет новые книги, он сначала регистрирует всю операцию в каталоге, и, только если все прошло успешно, операция считается завершенной. Никакого беспорядка.
Если переводить на технический язык:
Apache Iceberg — это открытый формат таблиц для огромных аналитических наборов данных.
Ключевые слова здесь — «формат таблиц». Iceberg — это не система хранения, не база данных и не движок для обработки запросов. Это спецификация, умный metadata-слой (тот самый «каталог»), который находится поверх ваших файлов данных (Parquet, ORC, Avro) в вашем озере данных.
Зачем нужен Apache Iceberg?
Он обеспечивает главные показатели качества традиционных озер данных:
- Надежность. Стандартные операции записи в HDFS или S3 не являются атомарными. Если ваш Spark-джоб, который записывает данные, упадет на 90% выполнения, вы получите «грязные» данные: часть файлов записана, часть нет. Iceberg вводит ACID-транзакции (Atomicity, Consistency, Isolation, Durability), гарантируя, что любая операция либо завершается полностью, либо не оставляет после себя никаких следов.
- Производительность. Когда у вас таблица из сотен тысяч файлов, простое получение списка этих файлов для чтения может занять минуты. Iceberg хранит список файлов и их статистику в компактных метаданных, что позволяет движкам (вроде Spark или Trino) очень быстро понять, какие именно файлы нужно читать, отсекая 99% ненужных.
- Корректность. Два разных процесса, одновременно читающие и пишущие в одну и ту же таблицу, могут видеть разное состояние данных. Iceberg обеспечивает строгую изоляцию и консистентность, так что все пользователи видят согласованную картину.
Проще говоря, Iceberg приносит надежность и удобство традиционных баз данных в мир масштабируемых и дешевых озер данных.
Основные возможности и функционал Apache Iceberg
Давайте посмотрим на «суперсилы» Iceberg, которые делают его таким популярным.
Schema Evolution (Эволюция схемы)
Это одна из самых болезненных тем в мире Big Data. Представьте, что у вас есть таблица с данными о пользователях и вам нужно добавить новый столбец registration_source. В мире Hive это часто означало бы полную перезапись всей гигантской таблицы, что долго и дорого.
Iceberg решает эту проблему элегантно: все изменения схемы (добавление, удаление, переименование столбца, изменение типа) просто регистрируются в файлах метаданных. Iceberg присваивает каждому столбцу уникальный ID и отслеживает изменения по нему. Старые данные остаются нетронутыми со старой схемой, а новые пишутся уже с новой. При чтении Iceberg на лету совмещает эти схемы. Никаких переписываний всей таблицы!
Time Travel (Путешествия во времени) и Version Rollback (Откат версий)
Каждое изменение в таблице Iceberg (вставка, обновление, удаление) создает новый «снимок» (snapshot) состояния таблицы. Iceberg хранит историю этих снимков. Что это дает?
- Воспроизводимость ML-экспериментов. Вы можете запустить обучение модели на данных, которые были в таблице ровно в 14:00 в прошлый вторник. Это гарантирует, что вы тренируетесь на абсолютно тех же данных, что и в предыдущий раз.
- Простая отладка. Внезапно упали метрики качества модели? Вы можете легко посмотреть, какие именно данные были добавлены в таблицу между вчерашним и сегодняшним днем, и найти причину.
- Быстрый откат к предыдущей версии. Вы загрузили в таблицу «битые» данные по ошибке? Одной командой вы можете откатить таблицу к состоянию до этой загрузки, как будто ее никогда и не было.
Hidden Partitioning (Скрытое партиционирование)
В Hive партиционирование (разделение данных на части для ускорения запросов) было жестко привязано к структуре папок. Например, …/event_date=2023-12-25/…. Это означало, что:
- Пользователь должен был знать, как именно таблица партиционирована, чтобы написать эффективный запрос.
- Если вы хотели изменить способ партиционирования (например, с ежедневного на ежемесячный), вам снова приходилось переписывать всю таблицу.
Iceberg отделяет логическое представление от физического. Вы просто пишете запрос WHERE event_timestamp > ‘2023-12-25 10:00:00’, а Iceberg сам понимает, что данные физически разделены по дням, и преобразует ваш запрос так, чтобы прочитать только нужные партиции. Вы можете даже изменить схему партиционирования в будущем, и старые данные останутся лежать как лежали, а новые будут записываться по-новому. Для пользователя, который пишет SQL-запрос, ничего не изменится!

Архитектура в двух словах
Чтобы было нагляднее, давайте посмотрим на структуру таблицы Iceberg.

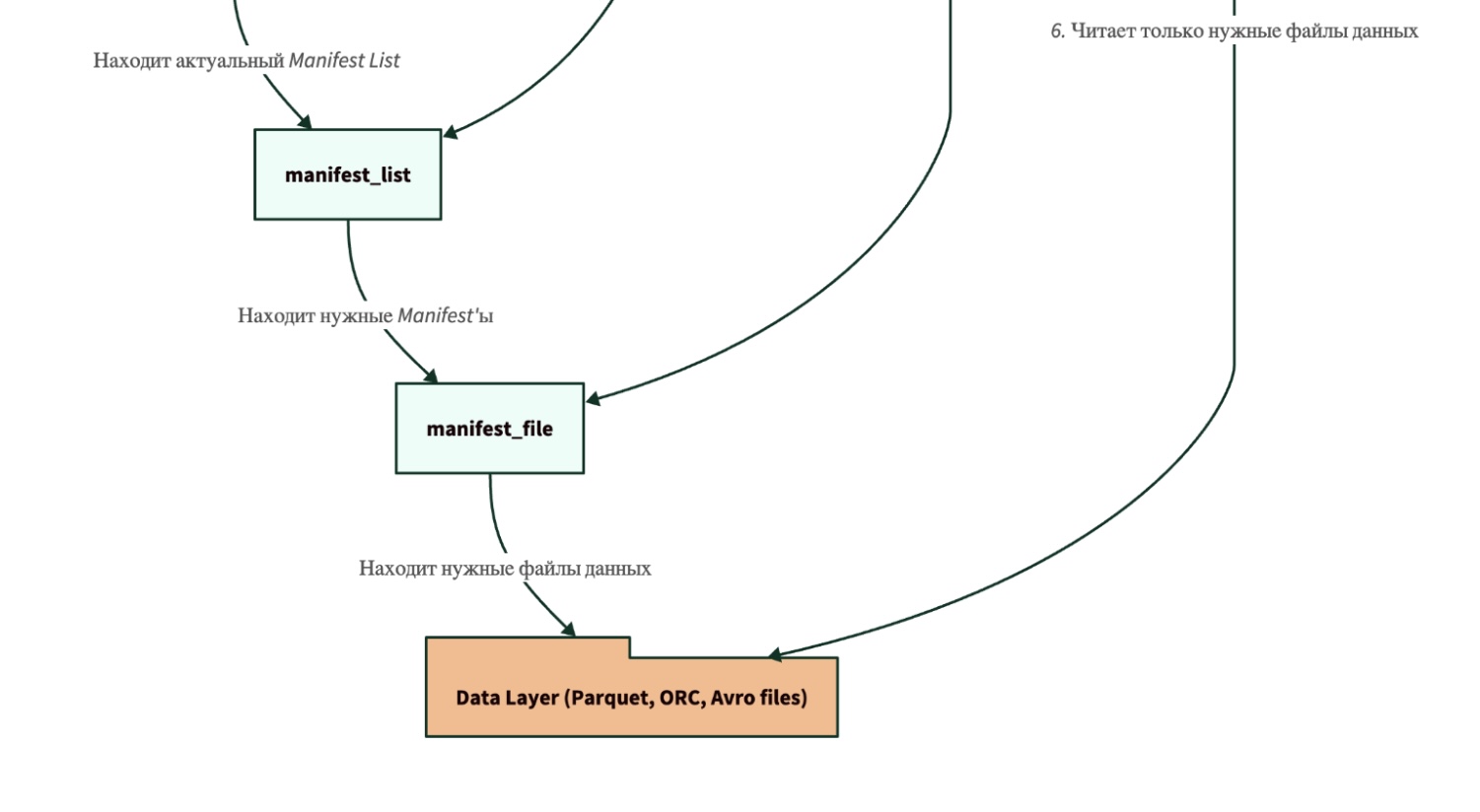
Как это работает при чтении:
- Движок (например, Spark) обращается к Каталогу, чтобы найти путь к последнему файлу метаданных metadata.json.
- В metadata.json он находит ссылку на текущий Manifest List.
- Manifest List содержит ссылки на файлы-Манифесты. На этом этапе уже можно отсечь ненужные файлы по статистике партиций.
- Каждый Манифест содержит список уже конкретных файлов с данными (например, Parquet) и их детальную статистику (минимальные/максимальные значения в столбцах). Это позволяет движку отсечь еще больше файлов, которые точно не содержат нужных данных.
- И только после всех этих фильтраций движок идет и читает те немногие файлы данных, которые действительно нужны для выполнения запроса.
Преимущества и недостатки Apache Iceberg
Как и у любой технологии, у Iceberg есть свои сильные и слабые стороны.
Преимущества:
- Надежность и корректность. ACID-транзакции — это game-changer для озер данных. Больше никаких «грязных» чтений и поврежденных таблиц из-за сбоев.
- Высокая производительность запросов. За счет умного хранения метаданных и отсечения ненужных файлов (file pruning) запросы к Iceberg-таблицам выполняются значительно быстрее.
- Гибкость и простота обслуживания. Эволюция схемы и скрытое партиционирование избавляют инженеров от головной боли и дорогостоящих операций по переписыванию таблиц.
- Воспроизводимость. Функция Time Travel — это просто подарок для ML-инженеров, которым важна повторяемость экспериментов.
- Открытость и независимость. Iceberg — это открытый стандарт под эгидой Apache. Он не привязан к одному движку. Вы можете писать данные с помощью Spark, а читать с помощью Trino, Flink или Dremio, и все будет работать.
Недостатки:
- Дополнительная сложность. Iceberg — это еще один слой в вашем стеке. Вам нужно настроить и поддерживать каталог (например, AWS Glue, Project Nessie или просто Hive Metastore).
- Проблема маленьких файлов. Частые небольшие записи (например, стриминг) могут порождать много маленьких файлов данных и метаданных. Это снижает производительность чтения. Проблему нужно решать с помощью регулярных операций «уплотнения» (compaction), что требует дополнительной настройки.
- Порог вхождения. Для команды, привыкшей к простому «закинул файлы в папку», переход на Iceberg потребует изучения новых концепций и подходов.
Сравнение Apache Iceberg с другими решениями
Самое классическое сравнение — это Iceberg vs. Hive. По сути, Iceberg был создан, чтобы решить проблемы Hive.
| Характеристика | Hive (на файловой системе) | Apache Iceberg | Комментарий |
| Единица управления | Директория (папка) | Таблица | Hive думает о данных как о наборе папок. Iceberg — как о полноценной таблице. |
| Метаданные | Хранятся централизованно в Hive Metastore (HMS) | Хранятся вместе с данными в виде файлов. HMS/Каталог хранит лишь ссылку на последнюю версию. | Подход Iceberg более масштабируемый и децентрализованный. |
| Атомарность операций | Нет. Операции на уровне файловой системы не атомарны. | Да (ACID). Атомарность достигается заменой указателя на новый файл метаданных. | Ключевое преимущество Iceberg в надежности. |
| Эволюция схемы | Очень ограничена и рискованна. Часто требует перезаписи данных. | Полная поддержка (добавление, удаление, переименование, изменение типа) без перезаписи. | Iceberg обеспечивает гибкость. |
| Партиционирование | Физическое (структура папок). dt=2023-12-25 | Логическое (скрытое). Пользователь не зависит от физической структуры. | Запросы в Iceberg проще писать и они не ломаются при смене структуры. |
| Производительность листинга | Медленно. Требуется операция LIST на файловой системе, что дорого для облачных хранилищ. | Быстро. Вся информация о файлах хранится в компактных файлах-манифестах. | Iceberg значительно быстрее находит нужные для запроса файлы. |
| Путешествия во времени | Нет встроенной поддержки. | Да, нативная поддержка через снимки (snapshots). | Iceberg идеально подходит для задач, требующих воспроизводимости. |
Аналогия для ML: Представьте, что вы готовите датасет.
- Hive — это как если бы вы сохраняли каждую версию датасета в новую папку: dataset_v1, dataset_v2, dataset_v2_fixed. Это быстро приводит к хаосу.
- Iceberg — это как система контроля версий Git. У вас всегда есть одна «таблица», но вы можете в любой момент переключиться на любой коммит (snapshot) из прошлого, посмотреть разницу и, если нужно, откатиться.
Коротко об Apache Iceberg
Так стоит ли игра свеч? Однозначно да.
Apache Iceberg — это не просто очередная модная технология. Это фундаментальный сдвиг в том, как мы должны работать с данными в озерах данных. Он берет лучшее из двух миров: масштабируемость и низкую стоимость озер данных и надежность, производительность и удобство традиционных хранилищ данных.
Для специалиста по машинному обучению Iceberg решает сразу несколько критически важных задач:
- Гарантирует качество и консистентность данных, на которых вы обучаете модели.
- Обеспечивает 100% воспроизводимость экспериментов благодаря Time Travel.
- Упрощает инженерию данных, позволяя вам больше фокусироваться на моделях, а не на борьбе с «болотом данных».
Переход на Iceberg может потребовать начальных усилий, но долгосрочные выгоды в виде надежности, скорости и простоты управления данными окупают их с лихвой. Это технология, которая превращает ваше «болото данных» в структурированный, надежный и быстрый Data Lakehouse. И если вы планируете серьезно заниматься ML на больших данных, познакомиться с Iceberg вам просто необходимо.