Одна из главных точка роста для искусственного интеллекта — научиться воспринимать человеческие эмоции. Часто текстовые нейросети могут понимать некоторые сообщения слишком буквально или не считывать контекст высказывания.
Бизнес заинтересован в том, чтобы чат-боты и модели, которые анализируют отзывы клиентов, воспринимали не только факты, но и настроение сообщений. В таком случае компании могли бы полностью автоматизировать клиентскую поддержку и повысить качество общения с чат-ботами.
Такие технологии уже в разработке, над похожим сервисом работали студенты Skillfactory и МФТИ на хакатоне с компанией «Наносемантика». Рассказываем, что у них получилось.

Бриф и начало работы
На хакатоне студенты Skillfactory получили от компании «Наносемантика» задание: разработать модель машинного обучения, способную анализировать текстовые расшифровки голосовых сообщений и классифицировать обнаруженные в них эмоции.
Студенты получили датасет — таблицу с перечнем высказываний, извлеченных из реальных голосовых сообщений, и присвоенной им эмоциональной окраской: недовольство, зависть, сочувствие, радость, злость, печаль, интерес или нейтральный тон. Предполагалось, что модель будет получать на вход текст, анализировать его и отдавать один из наиболее вероятных классов эмоций. В результате работы модель смогла бы определять настроение говорящего.
Разработка проекта
В отличие от голосового сообщения, текст лишен интонационных характеристик. Современные модели машинного обучения способны компенсировать этот недостаток за счет глубокого анализа структуры текста и контекста слов. Именно эти нюансы студенты должны были заложить в архитектуру модели. Поэтому решили обучить несколько алгоритмов и экспериментально выявить наиболее эффективный.
Представив и обсудив процесс разработки модели, студенты выделили ключевые этапы работы:
- Сбор и анализ данных для классификации.
- Предварительная обработка текста (очистка, лемматизация, токенизация и т. д.).
- Обучение нескольких моделей для сравнения их производительности.
- Визуализация и интерпретация результатов.
Сбор и анализ данных
От качества, полноты и обширности данных напрямую зависит эффективность будущей модели: чем более разнообразные и качественно размеченные тексты используют, тем точнее будет работа модели.
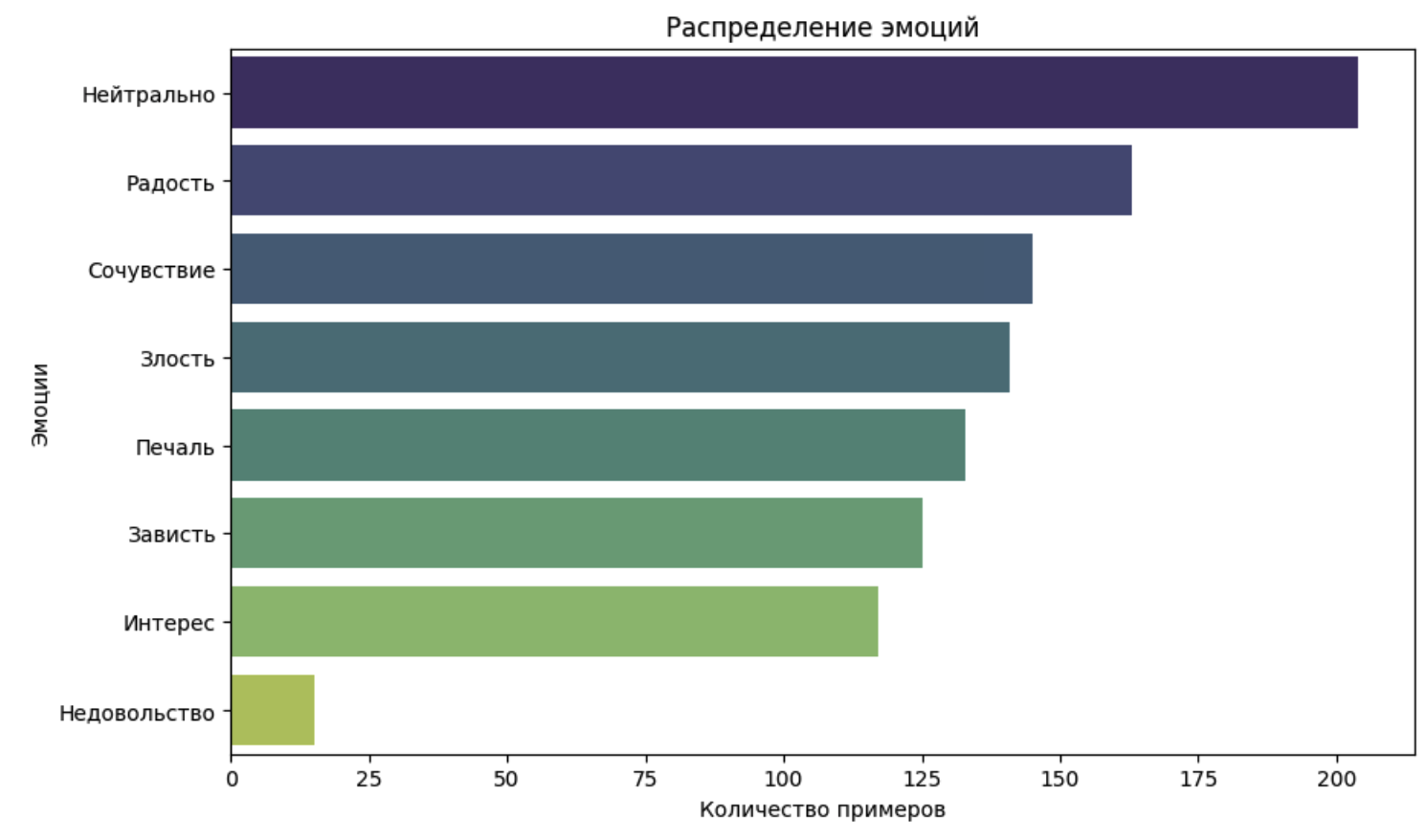
Компания «Наносемантика» дала команде предварительно структурированный датасет, 1043 текстовые расшифровки оригинальных голосовых сообщений. Данные предварительно разделили на несколько классов эмоций: радость, злость, печаль, интерес и нейтральный тон. Однако для эффективного обучения моделей важно было учесть баланс данных, поскольку некоторые эмоции могут встречаться реже, чем другие. Сильный перекос в выборке мог бы привести к тому, что модель хуже предсказывала бы определенные классы эмоций.
Чтобы избежать этого, команда проанализировала распределение классов, определила возможные пробелы в данных. В ходе анализа выяснилось, что эмоций по типу «Недовольство» всего 15 на всю выборку. Команда определила, что этого может быть недостаточно для хорошего обучения модели. Разумнее всего было объединить этот класс эмоций со «Злостью». Остальные результаты шли по нисходящей, начиная от эмоций «Нейтрально», с небольшим разрывом между собой.
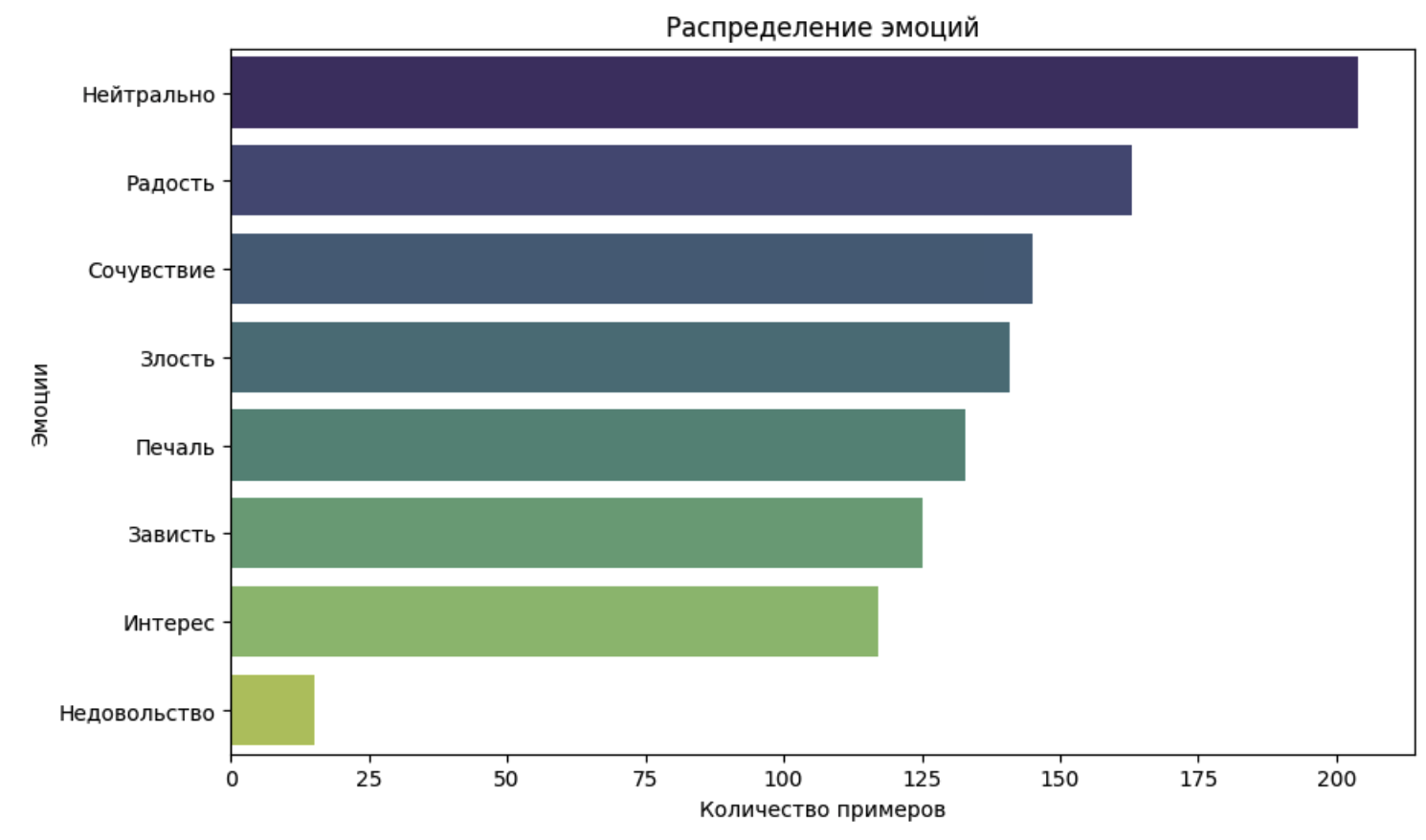
Этот подход позволил сбалансировать обучающую выборку и повысить точность модели.

Предварительная обработка данных
Перед обучением модели данные прошли несколько этапов обработки.
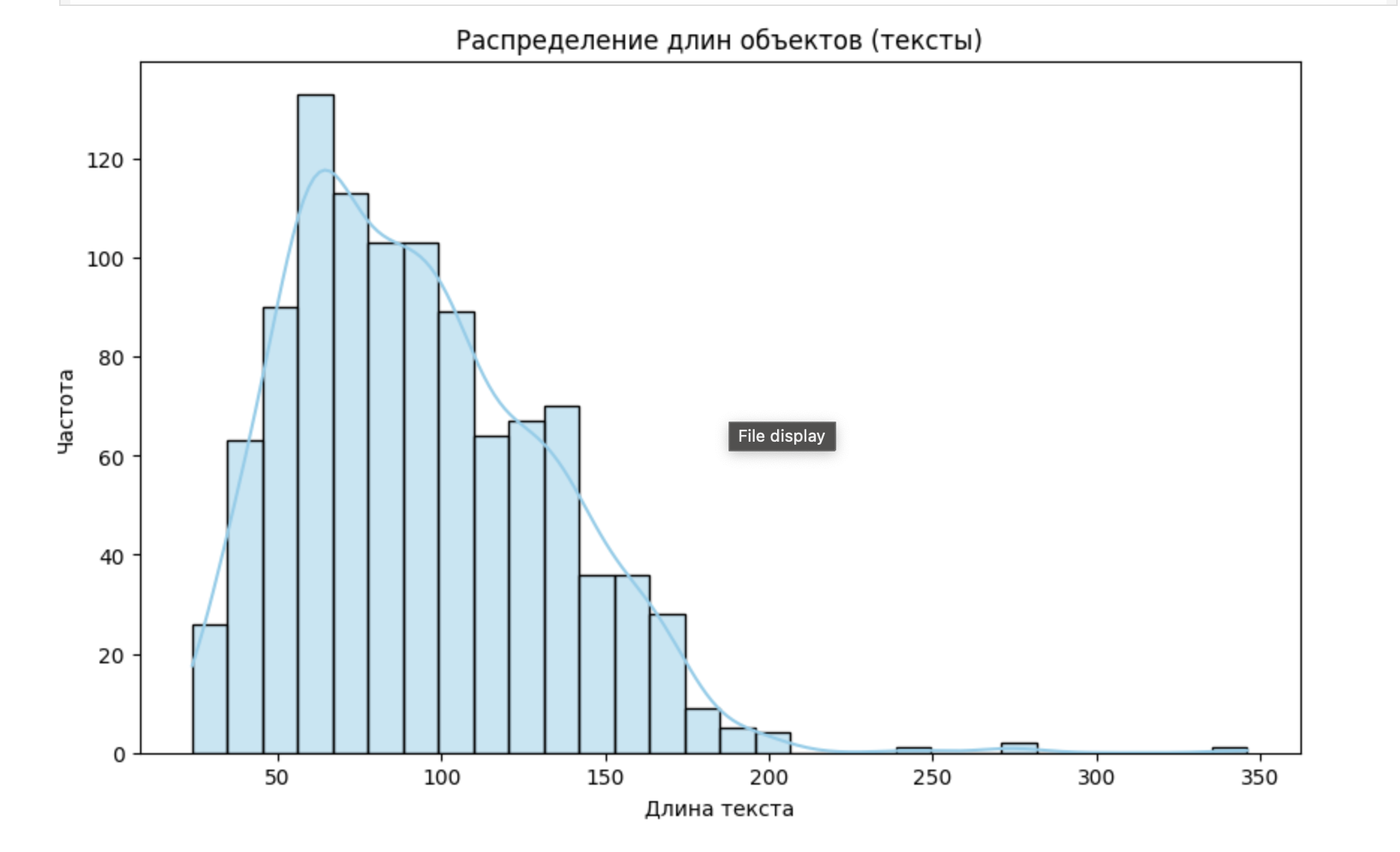
0. Измерение длины сообщений
Студенты определили длину каждого сообщения и составили визуализацию распределения.
- Приведение текста к нижнему регистру
Расшифровки голосовых сообщений могут содержать слова, записанные как с заглавной, так и со строчной буквы. Например, «Пермь» и «пермь» обозначают одно и то же слово, однако без приведения регистра модель может воспринимать их по-разному. Чтобы избежать ошибок в работе, все слова перевели в нижний регистр.
- Удаление стоп-слов
В языке существуют служебные части речи — это слова, которые не несут смысловой нагрузки, но необходимы для формирования предложений. К ним относятся, например, союзы и предлоги: «и», «но», «в», «на», «с». Эти слова не добавляют информации о содержании текста, но могут создавать шум для модели и снижать ее точность. Чтобы повысить точность, стоп-слова удалили из датасета.
- Лемматизация
Лемматизация — это приведение слов к их базовой форме (лемме). Например:
- «стоял» — «стоять»;
- «автобусы» — «автобус»;
- «поющий» — «петь».
Для выполнения лемматизации команда использовала библиотеку pymorphy2. Она анализирует морфологическую структуру слов и помогает разработчикам привести их к начальной форме. Лемматизация сократила количество уникальных токенов и улучшила качество классификации эмоций.
Пример обработки текста:
- Исходный текст: «Сегодня прекрасный день!».
- После приведения к нижнему регистру: «сегодня прекрасный день!».
- После удаления стоп-слов: «сегодня прекрасный день».
- После лемматизации: «сегодня прекрасный день».
Преобразовав датасет по этим этапам, студенты смогли создать чистый и структурированный набор текстов, который можно было анализировать для классификации эмоциональной окраски сообщений.
Выбор моделей обучения и результаты экспериментов
Команда протестировала несколько алгоритмов, чтобы выбрать наиболее эффективное решение:
- Logistic Regression: простая модель, использующая TF-IDF-признаки.
- Random Forest: подходит для текстов небольшого объема, но менее эффективна для конкретной задачи.
- XGBoost: модель градиентного бустинга, эффективная для структурированных данных.
- LightGBM: легковесная версия градиентного бустинга.
- MLP (многослойный перцептрон): простой искусственный нейронный подход.
- BERT: предобученная трансформерная модель.
В результате первых экспериментов студенты получили следующие значения эффективности работы разных моделей.
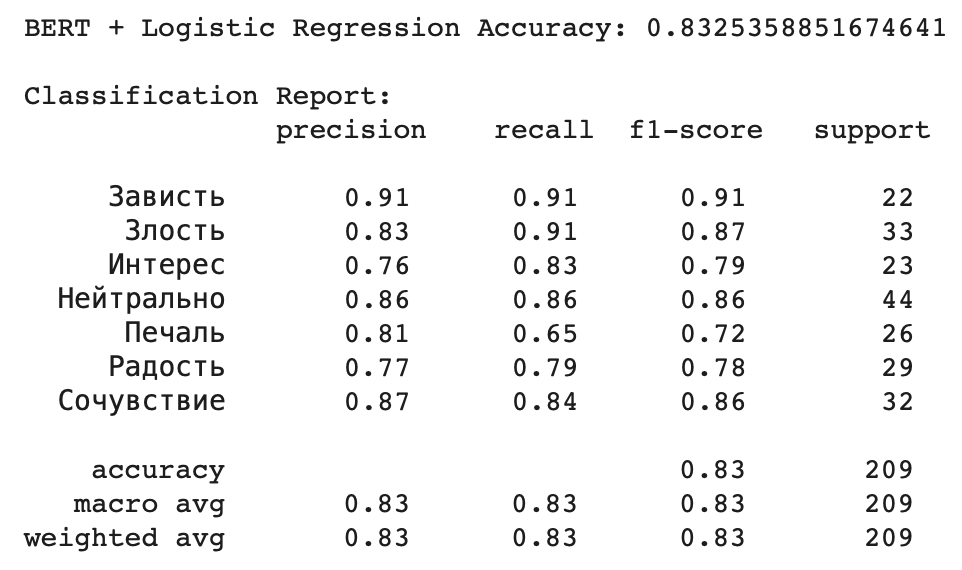
В дальнейших тестах лучший результат показала комбинация BERT + Логистическая регрессия с точностью 0,8325, что значительно превышает результаты остальных моделей.
Визуализация данных
Для лучшего понимания работы моделей студенты подготовили:
- матрицы ошибок (Confusion Matrix) — для выявления частых ошибок модели;
- графики важности признаков — определение ключевых слов, влияющих на классификацию;
- диаграммы распределения эмоций — оценка сбалансированности классов.