


Скорее всего, вы уже сталкивались с классической болью дата-сайентиста: вы загружаете CSV-файл весом в пару гигабайт, запускаете pandas, и… ваш ноутбук начинает взлетать, кулер воет, а ядро Jupyter умирает с ошибкой MemoryError. Или же вы ждете завершения простого groupby столько времени, что успеваете сварить кофе, выпить его и переосмыслить свою жизнь.
Долгое время мы жили в парадигме «Pandas для всего, что влезает в память, Spark для всего остального». Но между этими двумя крайностями была огромная пропасть. Сегодня мы поговорим о технологии, которая строит мост через эту пропасть. О библиотеке, которая заставила меня переписать 80% моих пайплайнов предобработки данных. Мы поговорим о Polars.
Что такое Polars и почему он такой быстрый
В мире Python долгое время существовал де-факто стандарт для работы с табличными данными — библиотека Pandas. Она прекрасна, удобна и имеет огромную экосистему. Но Pandas была создана в 2008 году. С тех пор объемы данных выросли экспоненциально, а архитектура процессоров изменилась. Pandas, будучи однопоточной и не всегда эффективной в работе с памятью, перестала справляться с современными нагрузками на одной машине.

Появился Polars — это библиотека DataFrame, полностью написанная на языке Rust, но с удобным интерфейсом для Python. Ее главная цель — скорость и эффективность. Если Pandas — это надежный, но старенький седан, то Polars — это современный электрокар. И то и другое довезет вас до цели, но ощущения от поездки будут разными.
Почему Polars такой быстрый? Здесь нет никакой магии, только инженерные решения.
Написан на Rust
Python — великолепный язык, но он медленный. Pandas под капотом использует C и Cython, чтобы ускорить процессы. Однако она все еще страдает от ограничений самого Python, например GIL (Global Interpreter Lock), который мешает использовать все ядра вашего процессора. Polars написан на Rust. Это дает ему полный контроль над памятью и возможность работать на уровне «железа» без накладных расходов интерпретатора.
Формат памяти Apache Arrow
Это, пожалуй, самое важное. Polars основан на стандарте Apache Arrow — спецификации того, как данные должны лежать в оперативной памяти.
- Pandas (классический) часто хранит данные неоптимально, особенно строки, разбрасывая их по памяти.
- Polars (Arrow) использует колоночный формат хранения. Данные одной колонки лежат в памяти плотным непрерывным блоком.
Аналогия: Представьте, что вы собираете заказ в IKEA.
- Строчный формат (как в базах данных типа PostgreSQL): вы идете по списку покупок: Кровать, Матрас, Подушка. Потом второй заказ: Кровать, Матрас, Подушка. Вы бегаете по всему складу.
- Колоночный формат (Arrow/Polars): Вы берете сразу 100 Кроватей, потом 100 Матрасов, потом 100 Подушек. Процессору (грузчику) гораздо проще брать одинаковые коробки с одной полки подряд.
Параллелизм (SIMD и многопоточность)
Поскольку Polars написан на Rust и не связан GIL, он автоматически использует все доступные ядра вашего процессора. Если у вас 16 ядер, Polars распараллелит задачу на все 16. Pandas в большинстве операций будет использовать только одно. Кроме того, Polars активно использует инструкции SIMD (Single Instruction, Multiple Data) — это когда процессор одной командой обрабатывает сразу пачку чисел.
Ленивые вычисления — основа быстродействия
Это концепция, которая часто пугает новичков, но именно она делает Polars невероятно мощным.
В Pandas мы привыкли к Eager execution (энергичные/немедленные вычисления). Вы пишете: df = pd.read_csv(...). Pandas тут же читает весь файл в память. Вы пишете: df_filtered = df[df['val'] > 0]. Pandas тут же фильтрует и создает новую копию данных.
В Polars есть Lazy API (ленивые вычисления). Когда вы используете ленивый режим, Polars ничего не делает с данными сразу. Он просто «записывает» ваши команды в план выполнения (Query Plan). Вычисления начинаются только тогда, когда вы явно попросите результат (команда .collect()).
Зачем это нужно? Оптимизация запросов!
Представьте, что вы хотите прочитать CSV на 100 ГБ, отфильтровать строки за 2023 год и взять только колонку Price.
- Pandas (Eager): Прочитает все 100 ГБ в память (если влезет!). Потом отфильтрует год. Потом выберет колонку. Скорее всего, вы получите MemoryError на первом шаге.
- Polars (Lazy): Вы описываете эти действия. Polars смотрит на весь план целиком и понимает: «Ага, пользователю нужна только колонка Price и только за 2023 год. Мне незачем читать весь файл!»
- Projection Pushdown: Он прочитает с диска только нужные колонки.
- Predicate Pushdown: Он применит фильтр во время чтения, отбрасывая лишние строки до того, как они займут место в RAM.
Давайте визуализируем это с помощью диаграммы.
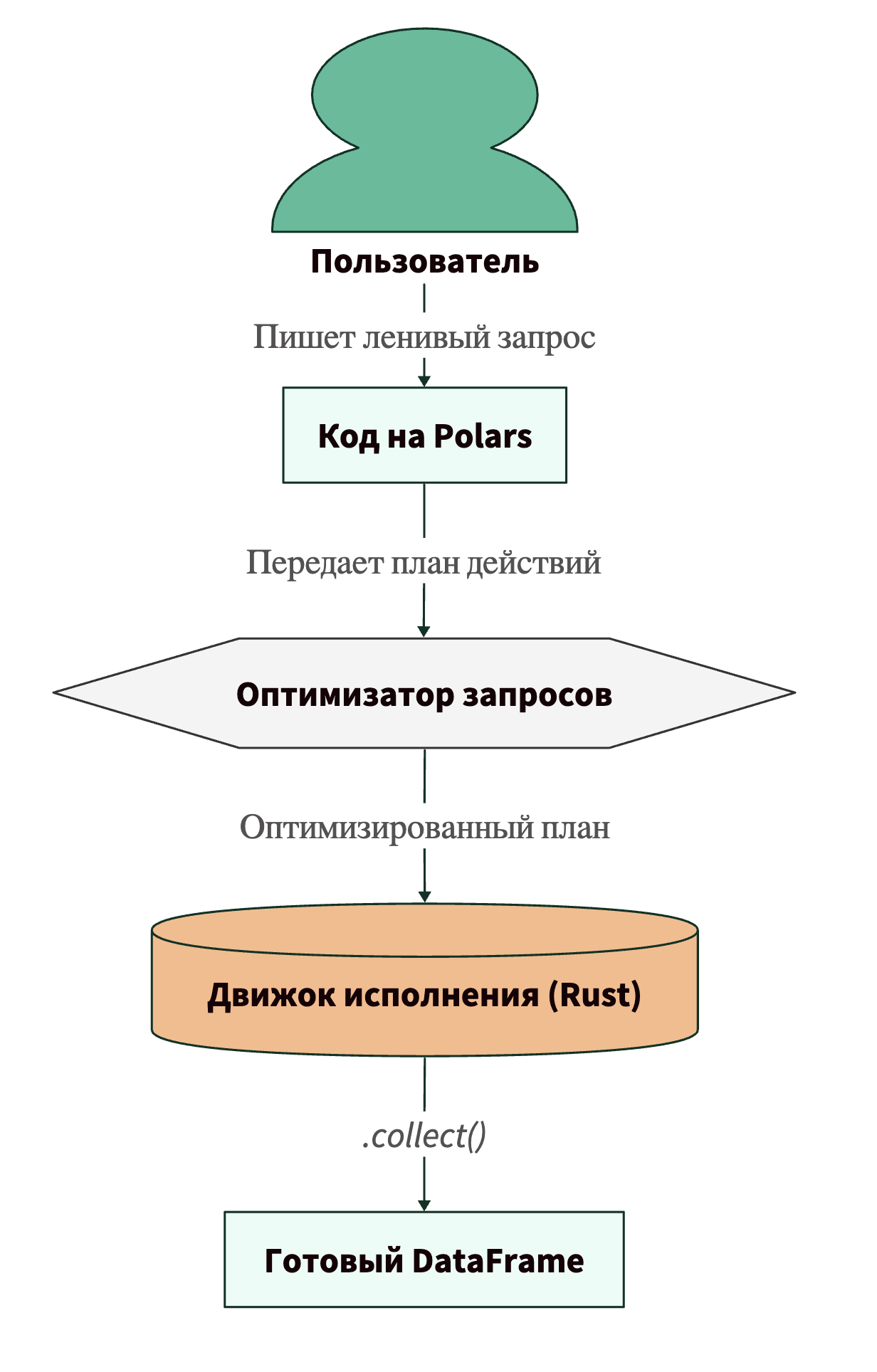
Ленивые вычисления позволяют Polars обрабатывать файлы, которые больше, чем объем вашей оперативной памяти (Streaming API), обрабатывая их частями.

Сравнение с другими решениями
Выбор инструмента зависит от задачи. Давайте честно сравним Polars с гигантами индустрии.
Polars vs Pandas: детальное сравнение
Главный вывод: Если у вас данные до 1–2 ГБ, Pandas будет достаточно. Если данные от 5 до 100–200 ГБ на одной машине — Polars уничтожает Pandas.
Polars vs PySpark
PySpark — это инструмент для распределенных вычислений.
- PySpark нужен, когда ваши данные не влезают в один компьютер (терабайты, петабайты). Он запускается на кластере из множества серверов.
- Polars предназначен для вертикального масштабирования (один мощный компьютер).
Интересный факт: На одной машине Polars часто быстрее, чем PySpark в локальном режиме. У Polars нет оверхеда на запуск JVM (Java Virtual Machine) и коммуникацию между нодами. Если ваши данные влезают на один диск (даже если это 500 ГБ), Polars в режиме streaming часто будет дешевле и проще в поддержке, чем кластер Spark.
Недостатки и ограничения Polars
Я обещал быть честным. У Polars есть свои минусы, и о них нужно знать.
Незрелость экосистемы
Pandas существует 15 лет. Любая библиотека (Scikit-learn, Matplotlib, PyTorch) умеет «кушать» Pandas DataFrame нативно. С Polars ситуация улучшается, но часто вам придется делать .to_pandas() или .to_numpy() перед тем, как отдать данные в модель машинного обучения или построить график в Seaborn. Это лишнее копирование данных.
Отсутствие привычных концепций (индекс)
В Pandas мы привыкли к Index и MultiIndex. Мы делаем df.loc['2023-01-01']. В Polars индексов нет. Вообще. Это сознательное решение разработчиков, так как индексы тормозят работу в распределенных и многопоточных системах. Если вам нужно найти строку по дате, вы делаете фильтр: df.filter(pl.col(«date») == …) или используете бинарный поиск на отсортированных данных. Для ветеранов Pandas это может быть болезненным переходом.
Ограничения в специализированных областях
Если вы занимаетесь специфическим геоанализом (GeoPandas) или очень сложной работой с временными рядами, где критичен MultiIndex, Pandas пока может быть удобнее за счет готовых расширений. Хотя GeoPolars уже развивается.
Практические примеры работы с данными в Polars
Хватит теории, давайте писать код!
Примечание: для примеров предполагается, что вы импортировали библиотеку:
import polars as pl import numpy as np from datetime import datetime
Создание DataFrame
Синтаксис похож на Pandas, но строже к типам данных.
data = {
"id": [1, 2, 3, 4, 5],
"name": ["Alice", "Bob", "Charlie", "David", "Eve"],
"salary": [50000, 60000, 55000, 70000, 65000],
"join_date": [datetime(2020, 1, 1), datetime(2021, 5, 15), datetime(2020, 8, 20), datetime(2022, 1, 10), None]
}
df = pl.DataFrame(data)
print(df)
Чтение и запись данных
Здесь начинается магия.
Eager (как в Pandas — читаем всё сразу):
# Чтение
df = pl.read_csv("data.csv")
df_parquet = pl.read_parquet("data.parquet")
# Запись
df.write_parquet("output.parquet")
Lazy (рекомендуемый путь для больших данных):
# Создаем LazyFrame. Файл НЕ читается в этот момент.
q = pl.scan_csv("massive_dataset.csv")
# ... добавляем трансформации ...
# Выполняем
df = q.collect()
Базовые операции выборки и фильтрации
В Polars мы используем Expressions (выражения). Основной метод доступа к колонке — pl.col("имя").
# Select: Выбрать конкретные колонки
# SQL-аналог: SELECT name, salary FROM df
res = df.select([
pl.col("name"),
pl.col("salary")
])
# Filter: Фильтрация строк
# SQL-аналог: WHERE salary > 55000 AND join_date IS NOT NULL
res = df.filter(
(pl.col("salary") > 55000) &
(pl.col("join_date").is_not_null())
)
Создание и модификация колонок
В Pandas мы писали df['new_col'] = .... Это меняет объект на месте (иногда) или вызывает предупреждение SettingWithCopy. В Polars мы используем метод .with_columns(). Он возвращает новый DataFrame (помните про иммутабельность и функциональный стиль).
df_new = df.with_columns([
# Увеличим зарплату на 10%
(pl.col("salary") * 1.1).alias("salary_indexed"),
# Создадим флаг "Богатый"
(pl.col("salary") > 60000).alias("is_high_earner"),
# Логика с условиями (аналог np.where)
pl.when(pl.col("name") == "Alice")
.then(pl.lit("Boss"))
.otherwise(pl.lit("Employee"))
.alias("role")
])
Обратите внимание: операции внутри with_columns выполняются параллельно!
Группировка и агрегация
Здесь Polars сияет. Синтаксис очень выразительный.
# Группировка по роли (предположим, она у нас есть) и расчет статистик
# В Pandas это часто требует нескольких строк или agg cо словарем
res = df.group_by("role").agg([
pl.col("salary").mean().alias("avg_salary"),
pl.col("salary").max().alias("max_salary"),
pl.col("name").first().alias("first_employee"),
pl.len().alias("count") # Количество в группе
])
Соединение таблиц (Joins)
Синтаксис очень похож на SQL.
# Создадим вторую таблицу
depts = pl.DataFrame({
"name": ["Alice", "Bob", "Eve"],
"department": ["HR", "Engineering", "Marketing"]
})
# Left Join
joined_df = df.join(depts, on="name", how="left")
Оконные функции
В Pandas оконные функции часто медленные и имеют сложный синтаксис (.groupby().transform()). В Polars они нативны и работают молниеносно через .over().
Пример: Хотим добавить колонку со средней зарплатой по отделу для каждого сотрудника, не схлопывая таблицу.
# Представим, что у нас есть колонка department
df_window = df.with_columns(
pl.col("salary").mean().over("department").alias("dept_avg_salary")
)
# Теперь у каждого сотрудника записана средняя зарплата его отдела.
# Можно сразу посчитать разницу:
df_diff = df.with_columns(
(pl.col("salary") - pl.col("salary").mean().over("department")).alias("diff_from_avg")
)

Работа с временными рядами
Polars имеет мощный неймспейс .dt (datetime).
# Извлечение года и месяца
df_dates = df.with_columns([
pl.col("join_date").dt.year().alias("year"),
pl.col("join_date").dt.month().alias("month")
])
# Upsampling / Resampling (аналог pandas resample)
# Требует, чтобы колонка времени была отсортирована
q = (
df.sort("join_date")
.group_by_dynamic("join_date", every="1y") # Группировка по одному году
.agg(pl.col("salary").mean())
)
Работа со строками
Неймспейс .str. Быстрее, чем Pandas, так как не использует Python-объекты для каждой строки.
df_strings = df.with_columns(
pl.col("name").str.to_uppercase().alias("NAME_UPPER"),
pl.col("name").str.contains("A").alias("has_A")
)
Работа с отсутствующими значениями
Polars использует null.
# Заполнить null-значения
df_filled = df.with_columns(
pl.col("join_date").fill_null(datetime(2020, 1, 1))
)
# Заполнить стратегией (вперед/назад)
df_fwd = df.with_columns(
pl.col("salary").fill_null(strategy="forward")
)
Сводные таблицы и reshape операции
Pivot (из длинного в широкий) и melt (из широкого в длинный).
# Pivot # Values: что внутри ячеек, index: строки, columns: новые столбцы out = df.pivot(values="salary", index="name", columns="year") # Melt (Unpivot) out_melt = df.melt(id_vars=["name"], value_vars=["salary", "year"])
Оптимизация скорости вычислений в Polars
Вы уже используете Polars, но хотите выжать из него максимум? Вот чек-лист профессионала.
Используем ленивые вычисления везде, где можем
Я не устану это повторять. Всегда начинайте с pl.scan_csv() или pl.scan_parquet(). Это позволяет Polars:
- не загружать ненужные данные;
- менять порядок операций (сначала фильтр, потом тяжелая математика);
- использовать Streaming API.
# Плохо (для больших данных):
df = pl.read_csv("big.csv")
res = df.filter(pl.col("x") > 0)
# Хорошо:
res = pl.scan_csv("big.csv").filter(pl.col("x") > 0).collect()
Параллельная обработка — используем все ядра
Polars делает это сам, но вы должны ему помочь. Старайтесь писать выражения так, чтобы они были независимы друг от друга. В блоке with_columns([ ... ]) передавайте список выражений. Polars запустит их вычисление параллельно. Если вы напишете df = df.with_columns(...), а потом на следующей строке снова df = df.with_columns(...), вы заставите его ждать завершения первого шага. Объединяйте создание колонок в один вызов!
Эффективная работа с памятью и типы данных
Polars строг к типам. Используйте минимально необходимые.
- Если у вас категория с пятью значениями, используйте pl.Categorical вместо pl.Utf8 (String). Это сэкономит тонну памяти и ускорит группировки.
- Если у вас целые числа от 0 до 100, используйте pl.Int8 вместо дефолтного pl.Int64.
df = df.with_columns(
pl.col("category_col").cast(pl.Categorical)
)
Оптимизация операций соединения (Joins)
Polars очень быстр в джойнах, но есть нюанс. Если вы джойните две таблицы, старайтесь, чтобы та, к которой присоединяют (левая), была отсортирована по ключу джойна, если это возможно (хотя Polars и сам умеет использовать Hash Joins очень эффективно). Важнее другое: отфильтруйте данные ДО джойна. В ленивом режиме Polars постарается сделать это сам (Predicate Pushdown), но явное указание фильтров перед джойном в коде делает его понятнее.
Streaming API
Если у вас 16 ГБ RAM, а файл весит 50 ГБ, в Pandas вы труп, а в Polars вы просто делаете так:
q = pl.scan_csv("huge_file.csv")
# ... сложные операции ...
df = q.collect(streaming=True)
Флаг streaming=True говорит Polars: «Обрабатывай данные чанками (кусочками), не пытайся загрузить все сразу». Это работает для многих операций (groupby, filter, select, join), но не для всех (например, сортировка всего датасета или оконные функции, требующие всех данных, могут не сработать в стриминге либо будут использовать диск для сброса временных данных).
Polars: коротко о главном
Polars — это не просто «еще одна библиотека». Это сдвиг парадигмы в обработке данных на Python. Он приносит мощь системного программирования (Rust) и эффективность колоночных баз данных в удобный мир Python-скриптов.
Стоит ли учить Polars новичку? Да. Даже если на работе сейчас используют Pandas, знание Polars даст вам преимущество. Вы будете тем человеком, который скажет «Я могу ускорить этот отчет с 40 минут до 30 секунд», — и вы реально сделаете это.
Краткое резюме:
- Polars быстр благодаря Rust, Arrow и параллелизму.
- Используйте LazyFrame (scan_csv) для оптимизации плана запроса.
- Забудьте про индексы, используйте выразительный язык выражений (pl.col).
- Используйте
streaming=Trueдля данных, не влезающих в память.
Мир данных ускоряется, и нам нужно ускоряться вместе с ним. Попробуйте переписать свой следующий пет-проект на Polars. Сначала будет непривычно без индексов, но как только вы почувствуете эту скорость… пути назад к Pandas уже не будет.
Удачи в экспериментах и чистых вам данных!