

Модель машинного обучения начинает приносить пользу только тогда, когда она работает в продакшене. Здесь многие новички в ML сталкиваются с суровой реальностью: код ломается, зависимости конфликтуют, а процесс переноса модели с локального ноутбука на сервер превращается в ад.
Сегодня мы поговорим о том, как автоматизировать рутину, перестать бояться сломать рабочий код и сделать так, чтобы ваша ML-модель или приложение обновлялись на сервере по одному клику. Мы разберем GitHub Actions и концепцию CI/CD.
Зачем нужен CI/CD
Представьте себе ситуацию: вы участвуете в хакатоне или делаете пет-проект. Вы написали отличный API на FastAPI, который оборачивает вашу модель классификации текстов. Вы скидываете код коллеге, он пытается его запустить, и… у него ничего не работает. Оказывается, вы забыли добавить новую библиотеку в requirements.txt. Вы исправляете это, заливаете код на сервер вручную через SSH, перезапускаете приложение, и тут падает ошибка — вы случайно удалили важную запятую в коде, пока правили другой баг.

В машинном обучении мы часто грешим «грязным» кодом, потому что фокусируемся на экспериментах и метриках, а не на инженерной части. Но когда проект выходит за рамки Jupyter-ноутбука, нужны инструменты контроля качества.
Именно для этого придумали автоматизацию процессов тестирования и развертывания. Вместо того чтобы вручную проверять код, запускать тесты и копировать файлы на сервер, мы поручаем это роботам. В мире разработки это называется CI/CD, а одним из самых популярных и доступных инструментов для этого является GitHub Actions.
Что такое CI/CD
Аббревиатура CI/CD звучит как заклинание из мира суровых DevOps-инженеров, но на самом деле за ней кроется очень простая и логичная концепция. Давайте расшифруем.
CI — Continuous Integration (непрерывная интеграция)
Это практика, при которой все разработчики в команде (или вы один, но работающий над разными фичами) часто и регулярно сливают свой код в главную ветку (обычно это main или master).
Главное правило CI: каждое такое слияние должно автоматически проверяться.
Пример из жизни: вы решили поменять функцию предобработки данных (например, добавили удаление стоп-слов). Вы пушите код в GitHub. Система CI автоматически просыпается, скачивает ваш код, устанавливает Python, ставит библиотеки и запускает написанные вами тесты. Если ваша новая функция случайно сломала логику предсказания модели, тесты упадут, загорится красный крестик, и этот сломанный код не попадет в продакшен. Вы узнаете об ошибке сразу, а не от злых пользователей.
CD — Continuous Delivery / Continuous Deployment (непрерывная доставка / непрерывное развертывание)
Если CI отвечает за то, чтобы код был рабочим, то CD отвечает за то, чтобы этот код попал к пользователям.
- Delivery (доставка): код автоматически собирается в готовый продукт (например, в Docker-образ с вашей ML-моделью) и отправляется в хранилище. Он готов к релизу в любую секунду, но кнопку «Выкатить на сервер» нажимает человек.
- Deployment (развертывание): полная автоматизация. Как только код прошел все тесты (CI), он автоматически отправляется на боевой сервер и заменяет старую версию.
Давайте посмотрим на упрощенную схему этого процесса с помощью диаграммы:
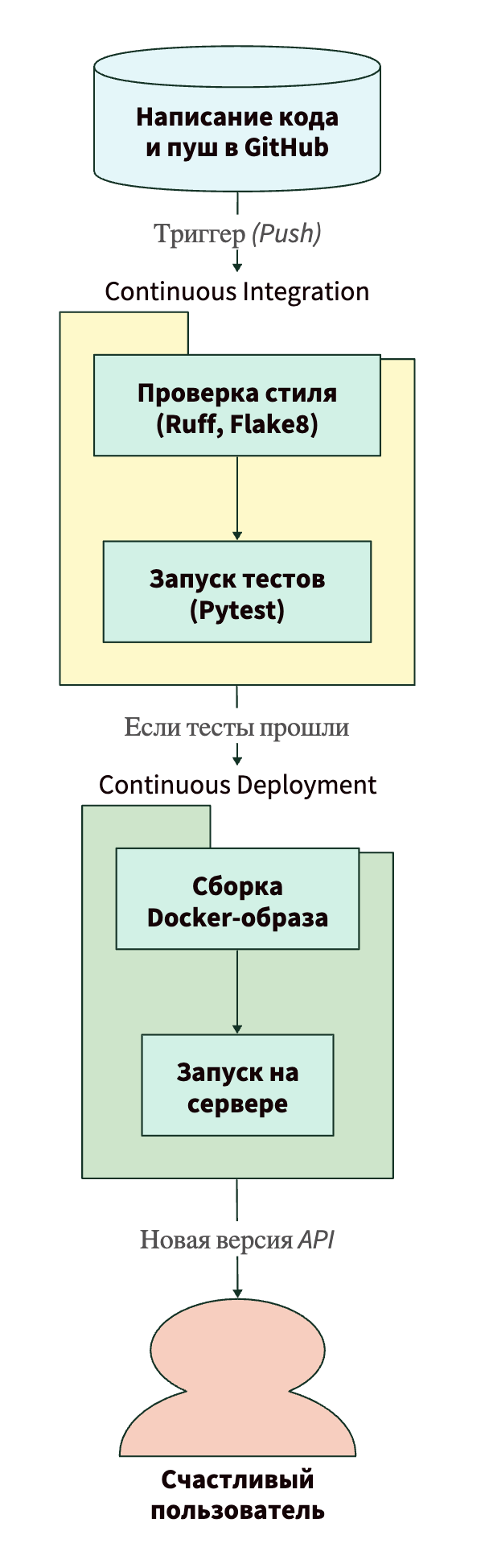
Зачем это нужно ML-специалисту? ML-системы сложнее обычных программ. У нас есть код, есть данные, есть веса моделей. Без автоматизации вы неизбежно запутаетесь, какая версия кода работает с какой версией модели. CI/CD (а в нашем случае это шаг к MLOps) гарантирует воспроизводимость и надежность ваших пайплайнов.
Что такое GitHub Actions
Инструментов для CI/CD существует множество: Jenkins, GitLab CI, CircleCI, TeamCity. Но GitHub Actions (GHA) стал настоящим хитом последних лет.
GitHub Actions — это встроенная в GitHub платформа для автоматизации рабочих процессов (workflow). Вам не нужно арендовать отдельный сервер для запуска тестов, не нужно устанавливать сложные программы. Если ваш код уже лежит на GitHub, вам достаточно просто положить специальный файл с инструкциями в папку .github/workflows/, и магия заработает сама.
Основные компоненты GitHub Actions
Чтобы писать пайплайны (цепочки автоматизированных действий), нужно понимать словарь терминов GHA. Представьте, что мы строим завод по производству автомобилей.
- Workflow (рабочий процесс / пайплайн) — это весь наш завод. То есть полная процедура, которую вы хотите автоматизировать. Например, «Протестировать и задеплоить ML-модель». Workflow описывается в одном YAML-файле.
- Events (события/триггеры) — это то, что включает рубильник на заводе. Например: разработчик сделал git push, или кто-то открыл Pull Request, или просто наступила полночь (работа по расписанию — круто для ночного дообучения моделей!).
- Jobs (задания) — это цеха на нашем заводе. Workflow может состоять из одной или нескольких Jobs. Например: Job 1 — прогнать тесты, Job 2 — собрать Docker-образ. По умолчанию Jobs выполняются параллельно (что экономит время), но можно настроить их так, чтобы Job 2 ждала успешного завершения Job 1.
- Steps (шаги) — это конкретные станки внутри цеха. Задание состоит из шагов. Шаг может быть просто командой в консоли (например, pip install -r requirements.txt) или вызовом готового Action.
- Actions (действия) — это готовые, переиспользуемые блоки кода (как купленные у поставщика умные станки). Зачем вам писать логику скачивания вашего кода из репозитория, если GitHub уже написал экшен actions/checkout? Вы просто используете его как функцию.
- Runners (раннеры) — это здание завода, вычислительная машина (виртуальный сервер), на которой все запускается. GitHub бесплатно предоставляет виртуальные машины на Linux (Ubuntu), Windows и macOS.
Место GHA в экосистеме: для небольших и средних проектов, а также для Open Source, GitHub Actions сейчас — стандарт индустрии. Он бесплатный (есть лимиты минут в месяц для приватных репозиториев, но для пет-проектов их за глаза хватает), отлично интегрирован с кодом и имеет гигантский маркетплейс готовых Actions на любой случай жизни.

Как работает GitHub Actions
Давайте разберем жизненный цикл одного запуска (run) от начала и до конца. Понимание этой механики убережет вас от часов дебаггинга в будущем.
Шаг 1: Срабатывание триггера (Events)
Все начинается с события. В вашем YAML-файле есть блок on:. Вы можете сказать GitHub: «Запускай этот процесс каждый раз, когда кто-то пушит код в ветку main». В ML часто используют событие schedule (по cron). Например, вы можете настроить GHA так, чтобы он каждую неделю скачивал свежие данные из базы, дообучал модель и, если метрики выросли, деплоил ее.
Шаг 2: Чтение YAML-конфигурации
GitHub видит событие, идет в папку .github/workflows/ и ищет там файлы с расширением .yml или .yaml. YAML — это язык разметки, похожий на Python-словари. В нем отступы имеют значение! GitHub читает этот файл и строит план выполнения (граф зависимостей между Jobs).
Шаг 3: Выделение раннера (Runner)
Для каждой Job GitHub ищет свободный сервер (Runner). Если вы указали runs-on: ubuntu-latest, GitHub за секунды создает абсолютно чистую виртуальную машину с Ubuntu. Важный нюанс для ML: бесплатные раннеры GitHub не имеют GPU и ограничены по оперативной памяти (около 7 Гб RAM). Обучить на них LLM не выйдет. Если вам нужна мощная видеокарта, вы можете настроить Self-hosted runner — подключить свой домашний ПК или арендованный AWS сервер с GPU к GitHub, и GHA будет отправлять задачи прямо на вашу машину!
Шаг 4: Запуск шагов (Steps) и кэширование
Раннер начинает выполнять шаги по очереди. И тут мы сталкиваемся с главной болью ML-инженеров — тяжелыми зависимостями. Установка Torch, Tensorflow, Pandas и Scikit-learn при каждом запуске может занимать 5–10 минут. Это тратит ваши бесплатные минуты GHA. Для решения этого используется кэширование (Caching). Вы можете сохранить скачанные библиотеки в кэш GitHub. При следующем запуске раннер проверит: «Изменился ли файл requirements.txt?» Если нет, он просто достанет готовые библиотеки из кэша за десять секунд.
Шаг 5: Использование секретов (Secrets)
В вашем коде наверняка есть пароли: API-ключи от OpenAI, токены от HuggingFace, пароль от базы данных или DockerHub. Никогда не пишите их в коде! Если вы запушите их в публичный репозиторий, боты хакеров найдут их через пять секунд и потратят все ваши деньги на AWS или OpenAI. Вместо этого мы используем GitHub Secrets. Вы заходите в настройки репозитория (Settings -> Secrets and variables -> Actions), добавляете туда свой ключ под именем, например, HF_TOKEN. А в YAML-файле обращаетесь к нему как ${{ secrets.HF_TOKEN }}. GitHub подставит его безопасно, а в логах замаскирует звездочками ***.
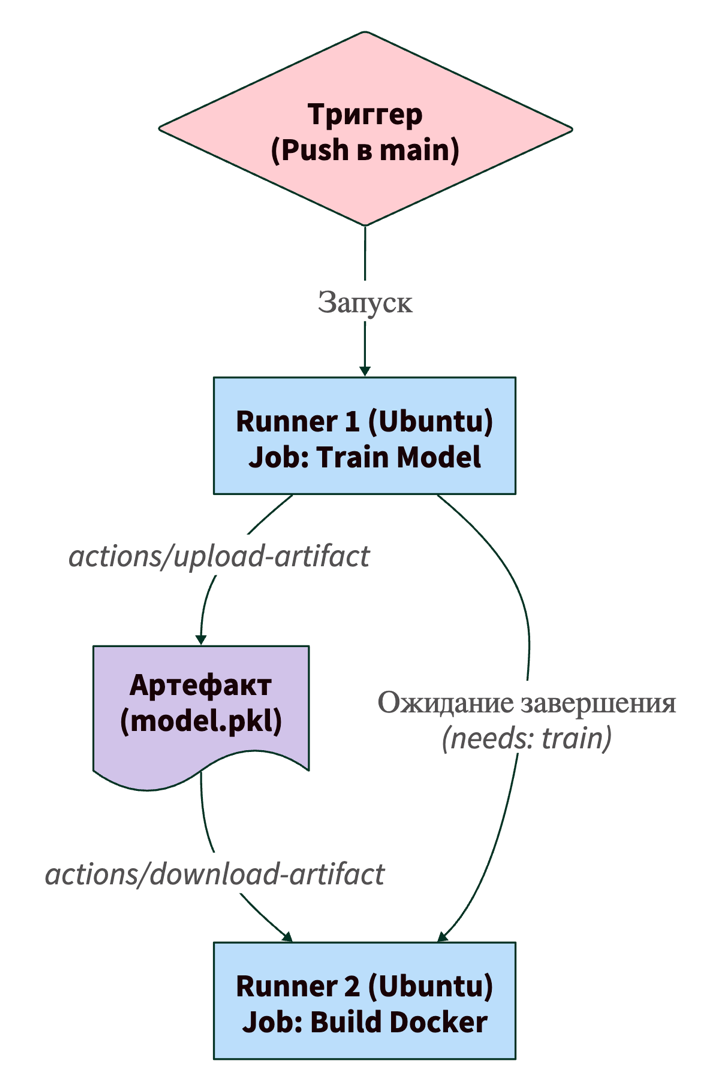
Шаг 6: Передача артефактов
Представьте, что в Job 1 вы обучили небольшую модель и получили файл model.pkl. А в Job 2 вы хотите собрать Docker-образ с этой моделью. Так как каждая Job запускается на своей изолированной виртуальной машине, Job 2 ничего не знает про файл model.pkl. Чтобы передать файл, используются Артефакты (Artifacts). Job 1 загружает файл в хранилище GitHub (экшен actions/upload-artifact), а Job 2 скачивает его оттуда (actions/download-artifact).
Создаем пайплайн с GitHub Actions (практика)
Хватит теории, давайте писать код! Мы создадим классический пайплайн для простого ML-проекта.
Наш сценарий: у нас есть API на Python (с использованием FastAPI), которое загружает предобученную модель (допустим, логистическую регрессию для классификации спама) и отдает предсказания. Мы хотим, чтобы при каждом пуше в ветку main GitHub Actions делал следующее:
- Проверял наш код линтером на соответствие стандартам (чтобы код был красивым и без явных ошибок).
- Запускал автотесты (проверял, что API отвечает и возвращает правильный формат данных).
- Собирал Docker-образ с нашим приложением.
- Отправлял (пушил) этот образ в DockerHub, чтобы потом сервер мог его скачать и запустить.
Подготовка проекта
Представим, что структура нашего проекта выглядит так:
my_ml_project/
├── .github/
│ └── workflows/
│ └── ci_cd.yml <-- Наш главный файл!
├── app/
│ ├── main.py <-- Код FastAPI
│ └── model.pkl <-- Веса модели
├── tests/
│ └── test_api.py <-- Тесты на Pytest
├── Dockerfile <-- Инструкция для сборки Docker
└── requirements.txt <-- Зависимости
Пишем YAML-конфигурацию (ci_cd.yml)
Ниже представлен полный код нашего workflow. Он большой, но не пугайтесь, сразу после него мы разберем каждую строчку. Создайте файл .github/workflows/ci_cd.yml и вставьте туда этот код:
# Название нашего Workflow, которое будет отображаться в интерфейсе GitHub
name: ML API CI/CD Pipeline
# 1. ТРИГГЕРЫ (Когда запускать?)
on:
push:
branches:
- main
pull_request:
branches:
- main
# 2. ЗАДАНИЯ (Jobs)
jobs:
# --- ЗАДАНИЕ 1: Линтинг и тестирование ---
test-and-lint:
name: Run Linters and Tests
runs-on: ubuntu-latest # Используем последнюю версию Ubuntu
steps:
# Шаг 1.1: Скачиваем наш код из репозитория на виртуальную машину
- name: Checkout code
uses: actions/checkout@v4
# Шаг 1.2: Устанавливаем Python
- name: Set up Python
uses: actions/setup-python@v5
with:
python-version: '3.10'
cache: 'pip' # Магия кэширования! Ускоряет установку зависимостей
# Шаг 1.3: Установка библиотек
- name: Install dependencies
run: |
python -m pip install --upgrade pip
pip install -r requirements.txt
pip install ruff pytest httpx # Добавляем инструменты для тестов
# Шаг 1.4: Проверка кода линтером Ruff
- name: Run Ruff Linter
run: ruff check .
# Шаг 1.5: Запуск тестов
- name: Run Pytest
run: pytest tests/
# --- ЗАДАНИЕ 2: Сборка и деплой (Docker) ---
build-and-push:
name: Build and Push Docker Image
runs-on: ubuntu-latest
# Это задание начнется, ТОЛЬКО если 'test-and-lint' завершилось успешно
needs: test-and-lint
# Запускаем сборку только при пуше в main (не для pull requests)
if: github.event_name == 'push'
steps:
- name: Checkout code
uses: actions/checkout@v4
# Шаг 2.1: Логинимся в DockerHub, используя секреты
- name: Log in to Docker Hub
uses: docker/login-action@v3
with:
username: ${{ secrets.DOCKER_USERNAME }}
password: ${{ secrets.DOCKER_PASSWORD }}
# Шаг 2.2: Собираем образ и отправляем его в DockerHub
- name: Build and push Docker image
uses: docker/build-push-action@v5
with:
context: .
push: true
# Тегируем образ именем пользователя и хешем коммита
tags: ${{ secrets.DOCKER_USERNAME }}/ml-api:latest, ${{ secrets.DOCKER_USERNAME }}/ml-api:${{ github.sha }}
Пошаговый разбор нашего пайплайна
Давайте пройдемся по конфигурации, как будто мы тот самый сервер GitHub, читающий инструкции.
Блок on: (триггеры)
on:
push:
branches: [main]
pull_request:
branches: [main]
Здесь мы говорим: «Запускайся, когда кто-то пушит код напрямую в main или когда кто-то создает Pull Request (заявку на слияние) в ветку main». Запускать тесты на Pull Request — это суперважная практика (CI). Вы проверяете код коллеги до того, как он попадет в основную ветку и что-то сломает.
Job 1: test-and-lint. В машинном обучении код часто пишут дата-сайентисты, которые пришли из математики, а не из программирования. Поэтому код бывает… специфичным. Линтеры помогают привести его в порядок.
- uses: actions/checkout@v4 — это базовый экшен. Без него виртуальная машина была бы пустой. Он клонирует ваш репозиторий на раннер. @v4 означает версию этого экшена.
- uses: actions/setup-python@v5 — устанавливает нужную версию Python. Обратите внимание на cache: ‘pip’. Это та самая магия! Экшен сам найдет ваш requirements.txt, посчитает его хеш и сохранит скачанные библиотеки. При следующем запуске пайплайн отработает на несколько минут быстрее, потому что тяжелый scikit-learn или torch достанутся из кэша.
- Линтер Ruff:
run: ruff check.Раньше все использовали flake8 или pylint. Но сейчас в мире Python доминирует Ruff. Он написан на Rust и работает в 10–100 раз быстрее аналогов. Для CI/CD, где время = деньги (или лимиты минут), это критично важно. Ruff проверит, нет ли у вас неиспользуемых импортов (например, import pandas as pd, который висит мертвым грузом) и правильно ли отформатирован код. - Тесты Pytest:
run: pytest tests/. Здесь запускаются ваши тесты. Например, тест может отправлять фейковый текст {«text»: «купи биткоин дешево»} в ваш API и проверять, что модель вернула класс “spam”, а статус ответа — 200 OK. Если код сломан, команда pytest вернет ошибку, шаг загорится красным и весь пайплайн остановится.
Job 2: build-and-push (Continuous Delivery). Если тесты прошли успешно, мы хотим запаковать наше приложение, чтобы его можно было запустить на любом сервере. В современном мире стандартом упаковки является Docker.
- needs: test-and-lint — важнейшая строчка. По умолчанию Jobs работают параллельно. Но нам не нужен Docker-образ со сломанным кодом! Эта строка заставляет вторую джобу ждать зеленого света от первой.
- if: github.event_name == ‘push’ — мы собираем и пушим образ в хранилище, только если код уже попал в main. Если это просто Pull Request (проверка предложенного кода), нам не нужно засорять DockerHub тестовыми образами.
- Секреты (${{ secrets.DOCKER_USERNAME }}) — чтобы запушить образ в ваш аккаунт DockerHub, GitHub должен авторизоваться. Вы заранее регистрируетесь на hub.docker.com, получаете там Access Token и сохраняете логин и токен в настройках репозитория GitHub (Settings -> Secrets).
- docker/build-push-action@v5 — этот официальный экшен делает всю грязную работу. Он читает ваш Dockerfile, собирает образ и отправляет его в облако.
- Тегирование (tags: …) — мы вешаем на образ два ярлыка. latest (последняя версия) и ${{ github.sha }}. github.sha — это уникальный идентификатор (хеш) коммита, который запустил этот процесс. Это золотое правило MLOps: каждый артефакт должен быть связан с конкретным коммитом кода. Если новая модель на сервере сойдет с ума, вы всегда по хешу найдете код, который ее породил, и сможете откатиться назад.
А что с деплоем (Continuous Deployment)?
В нашем примере мы доставили (Delivery) образ в DockerHub. Как он попадет на ваш боевой сервер? Есть несколько путей:
- Pull-модель (рекомендуемая): на вашем сервере работает специальная программа (например, Watchtower или агент Kubernetes), которая раз в пять минут проверяет DockerHub. Как только она видит новый образ с тегом latest, она сама его скачивает и перезапускает контейнер.
- Push-модель (через SSH): вы можете добавить в GitHub Actions еще один шаг! Использовать экшен типа appleboy/ssh-action. Вы передаете в секреты GitHub приватный SSH-ключ от вашего сервера. GitHub подключается к вашему серверу по SSH и выполняет команды: docker pull … и docker run ….
Для старта второй вариант проще, но первый считается более безопасным, так как вам не нужно отдавать ключи от сервера наружу.
CI/CD через Github Actions: коротко о главном
Подведем итоги. Сегодня мы сделали огромный шаг от простого «исследователя данных» (Data Scientist) к инженеру машинного обучения (ML Engineer / MLOps).
Мы поняли, что:
- автоматизация нужна, чтобы не ломать код, который работает;
- CI (непрерывная интеграция) — это автоматический запуск линтеров и тестов при каждом изменении кода;
- CD (непрерывная доставка/развертывание) — это автоматическая сборка Docker-образов и отправка их на сервер;
- GitHub Actions работает через события (triggers), виртуальные машины (runners), задания (jobs) и шаги (steps).
На первый взгляд YAML-файлы, Docker и виртуальные серверы могут пугать. Кажется, что это «не про математику и не про ML». Но поверьте моему опыту: умение быстро и надежно доставлять свои модели до продакшена ценится на рынке ничуть не меньше, чем умение выбить лишние 0.01 ROC-AUC на Kaggle.
Домашнее задание для вас: прямо сейчас откройте любой свой старый пет-проект на GitHub. Создайте папку .github/workflows/ и добавьте туда простейший YAML-файл, который просто будет запускать линтер ruff при пуше. Настройте это, сделайте коммит с кривым форматированием кода и посмотрите, как GitHub Actions поймает вашу ошибку. Ощущение того, что роботы работают за вас, бесценно!
Удачи в автоматизации ваших пайплайнов, и пусть ваши тесты всегда будут зелеными!
