
NLP (Natural Language Processing, обработка естественного языка) — это направление в машинном обучении, посвященное распознаванию, генерации и обработке устной и письменной человеческой речи. Находится на стыке дисциплин искусственного интеллекта и лингвистики.

Инженеры-программисты разрабатывают механизмы, позволяющие взаимодействовать компьютерам и людям посредством естественного языка. Благодаря NLP компьютеры могут читать, интерпретировать, понимать человеческий язык, а также выдавать ответные результаты. Как правило, обработка основана на уровне интеллекта машины, расшифровывающего сообщения человека в значимую для нее информацию.
Процесс машинного понимания с применением алгоритмов обработки естественного языка может выглядеть так:
- Речь человека записывается аудио-устройством.
- Машина преобразует слова из аудио в письменный текст.
- Система NLP разбирает текст на составляющие, понимает контекст беседы и цели человека.
- С учетом результатов работы NLP машина определяет команду, которая должна быть выполнена.

Кто использует NLP
Приложения NLP окружают нас повсюду. Это поиск в Google или Яндексе, машинный перевод, чат-боты, виртуальные ассистенты вроде Siri, Алисы, Салюта от Сбера и пр. NLP применяется в digital-рекламе, сфере безопасности и многих других.
Технологии NLP используют как в науке, так и для решения коммерческих бизнес-задач: например, для исследования искусственного интеллекта и способов его развития, а также создания «умных» систем, работающих с естественными человеческими языками, от поисковиков до музыкальных приложений.
Как устроена обработка языков
Раньше алгоритмам прописывали набор реакций на определенные слова и фразы, а для поиска использовалось сравнение. Это не распознавание и понимание текста, а реагирование на введенный набор символов. Такой алгоритм не смог бы увидеть разницы между столовой ложкой и школьной столовой.
NLP — другой подход. Алгоритмы обучают не только словам и их значениям, но и структуре фраз, внутренней логике языка, пониманию контекста. Чтобы понять, к чему относится слово «он» в предложении «человек носил костюм, и он был синий», машина должна иметь представление о свойствах понятий «человек» и «костюм». Чтобы научить этому компьютер, специалисты используют алгоритмы машинного обучения и методы анализа языка из фундаментальной лингвистики.

Задачи NLP
Распознавание речи. Этим занимаются голосовые помощники приложений и операционных систем, «умные» колонки и другие подобные устройства. Также распознавание речи используется в чат-ботах, сервисах автоматического заказа, при автоматической генерации субтитров для видеороликов, голосовом вводе, управлении «умным» домом. Компьютер распознает, что сказал ему человек, и выполняет в соответствии с этим нужные действия.
Обработка текста. Человек может также общаться с компьютером посредством письменного текста. Например, через тех же чат-ботов и помощников. Некоторые программы работают одновременно и как голосовые, и как текстовые ассистенты. Пример — помощники в банковских приложениях. В этом случае программа обрабатывает полученный текст, распознает его или классифицирует. Затем она выполняет действия на основе данных, которые получила.
Извлечение информации. Из текста или речи можно извлечь конкретную информацию. Пример задачи — ответы на вопросы в поисковых системах. Алгоритм должен обработать массив входных данных и выделить из него ключевые элементы (слова), в соответствии с которыми будет найден актуальный ответ на поставленный вопрос. Для этого требуются алгоритмы, способные различать контекст и понятия в тексте.
Анализ информации. Это схожая с предыдущей задача, но цель — не получить конкретный ответ, а проанализировать имеющиеся данные по определенным критериям. Машины обрабатывают текст и определяют его эмоциональную окраску, тему, стиль, жанр и др. То же самое можно сказать про запись голоса.
Анализ информации часто используется в разных видах аналитики и в маркетинге. Например, можно отследить среднюю тональность отзывов и высказываний по заданному вопросу. Соцсети используют такие алгоритмы для поиска и блокировки вредоносного контента. В перспективе компьютер сможет отличать фейковые новости от реальных, устанавливать авторство текста. Также NLP применяется при сборе информации о пользователе для показа персонализированной рекламы или использования сведений для анализа рынка.

Генерация текста и речи. Противоположная распознаванию задача — генерация, или синтез. Алгоритм должен отреагировать на текст или речь пользователя. Это может быть ответ на вопрос, полезная информация или забавная фраза, но реплика должна быть по заданной теме. В системах распознавания речи предложения разбиваются на части. Далее, чтобы произнести определенную фразу, компьютер сохраняет их, преобразовывает и воспроизводит. Конечно, на границах «сшивки» могут возникать искажения, из-за чего голос часто звучит неестественно.
Генерация текста не ограничивается шаблонными ответами, заложенными в алгоритм. Для нее используют алгоритмы машинного обучения. «Говорящие» программы могут учиться на основе реальных данных. Можно добиться того, чтобы алгоритм писал стихи или рассказы с логичной структурой, но они обычно не очень осмысленные.
Автоматический пересказ. Это направление также подразумевает анализ информации, но здесь используется и распознавание, и синтез.Задача — обработать большой объем информации и сделать его краткий пересказ. Это бывает нужно в бизнесе или в науке, когда необходимо получить ключевые пункты большого набора данных.
Машинный перевод. Программы-переводчики тоже используют алгоритмы машинного обучения и NLP. С их использованием качество машинного перевода резко выросло, хотя до сих пор зависит от сложности языка и связано с его структурными особенностями. Разработчики стремятся к тому, чтобы машинный перевод стал более точным и мог дать адекватное представление о смысле оригинала во всех случаях.
Машинный перевод частично автоматизирует задачу профессиональных переводчиков: его используют для перевода шаблонных участков текста, например в технической документации.
Как обрабатывается текст
Алгоритмы не работают с «сырыми» данными. Большая часть процесса — подготовка текста или речи, преобразование их в вид, доступный для восприятия компьютером.
Очистка. Из текста удаляются бесполезные для машины данные. Это большинство знаков пунктуации, особые символы, скобки, теги и пр. Некоторые символы могут быть значимыми в конкретных случаях. Например, в тексте про экономику знаки валют несут смысл.
Препроцессинг. Дальше наступает большой этап предварительной обработки — препроцессинга. Это приведение информации к виду, в котором она более понятна алгоритму. Популярные методы препроцессинга:
- приведение символов к одному регистру, чтобы все слова были написаны с маленькой буквы;
- токенизация — разбиение текста на токены. Так называют отдельные компоненты — слова, предложения или фразы;
- тегирование частей речи — определение частей речи в каждом предложении для применения грамматических правил;
- лемматизация и стемминг — приведение слов к единой форме. Стемминг более грубый, он обрезает суффиксы и оставляет корни. Лемматизация — приведение слов к изначальным словоформам, часто с учетом контекста;
- удаление стоп-слов — артиклей, междометий и пр.;
- спелл-чекинг — автокоррекция слов, которые написаны неправильно.
Методы выбирают согласно задаче.
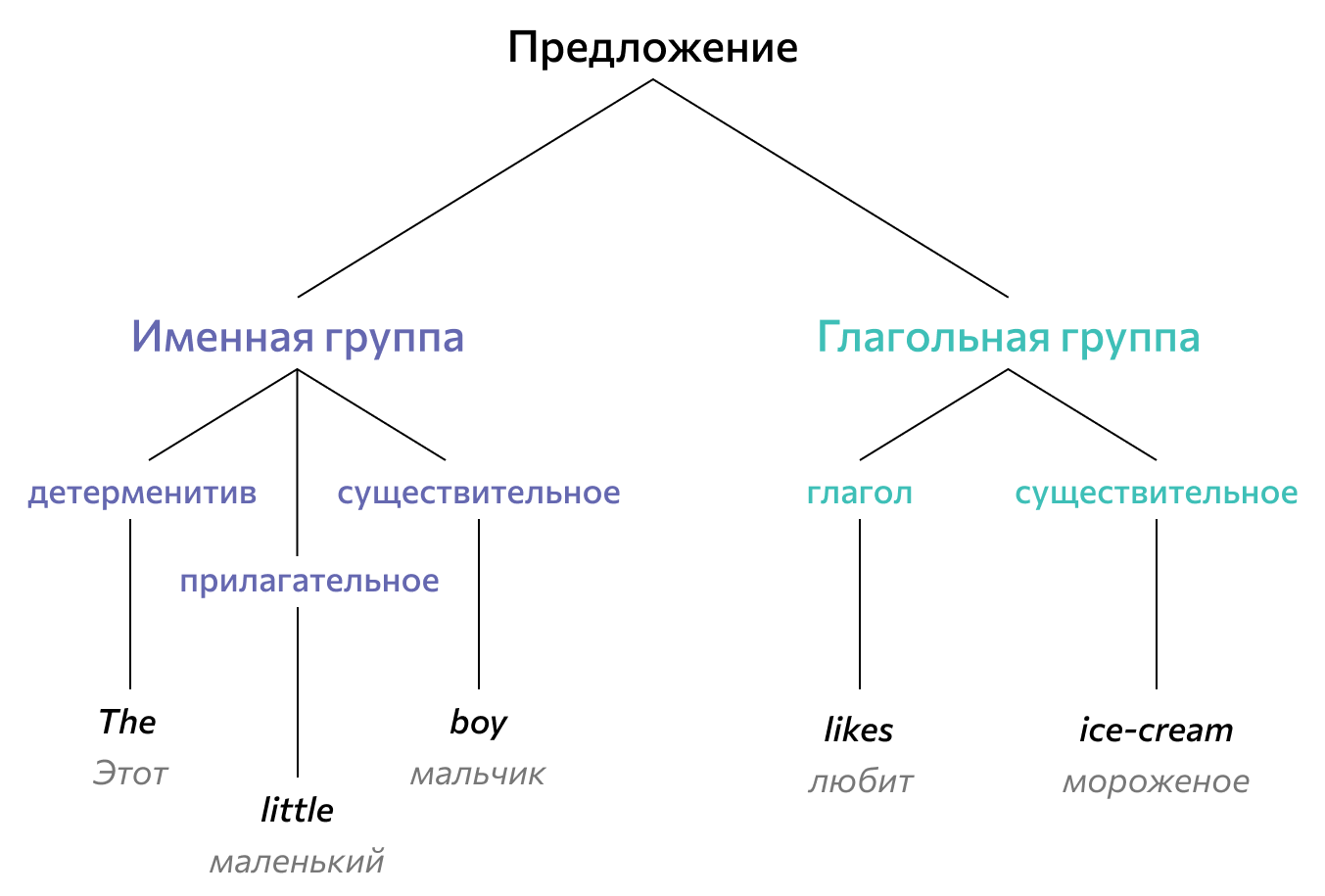
Векторизация. После предобработки на выходе получается набор подготовленных слов. Но алгоритмы работают с числовыми данными, а не с чистым текстом. Поэтому из входящей информации создают векторы — представляют ее как набор числовых значений.
Популярные варианты векторизации — «мешок слов» и «мешок N-грамм». В «мешке слов» слова кодируются в цифры. Учитывается только количество слова в тексте, а не их расположение и контекст. N-граммы — это группы из N слов. Алгоритм наполняет «мешок» не отдельными словами с их частотой, а группами по несколько слов, и это помогает определить контекст.
Применение алгоритмов машинного обучения. С помощью векторизации можно оценить, насколько часто в тексте встречаются слова. Но большинство актуальных задач сложнее, чем просто определение частоты — тут нужны продвинутые алгоритмы машинного обучения. В зависимости от типа конкретной задачи создается и настраивается своя отдельная модель.
Алгоритмы обрабатывают, анализируют и распознают входные данные, делают на их основе выводы. Это интересный и сложный процесс, в котором много математики и теории вероятностей.

0 комментариев