


Мы используем технологии распознавания речи почти каждый день: когда прокладываем маршрут голосом в навигаторе или общаемся с виртуальными помощниками, такими как Алиса, Маруся или Салют. А еще speech-to-text — это интересное и перспективное IT-направление.
Вместе с Павлом Богомоловым, руководителем STT в SberDevices, разберемся, как работает распознавание речи и в каких сферах его применяют.
Что такое распознавание речи
Технология распознавания речи, или Speech-to-Text (STT) — это переведение устной речи в текст. В ее основе — многоуровневый процесс, который включает обработку и анализ аудио. Речь с помощью искусственного интеллекта преобразуется сначала в буквы, затем слова, фразы, предложения, и в результате получается текст.

Часто вместо аббревиатуры STT используют другое название технологии — ASR (Automatic Speech Recognition), что переводится как «автоматическое распознавание речи».
Как развивалась технология распознавания речи
Технология STT появилась еще в 1950-х годах, а активное развитие началось лишь в 1970-х. Но скачок случился в начале 2000-х благодаря прогрессу в области машинного обучения. Тогда IT-специалисты начали создавать программы, которые точно преобразовывали речь в текст.
Ранний процесс распознавания речи выглядел так:
- Сначала микрофон записывал звук: замерял и фиксировал давление воздуха от речи человека. На выходе получалась звуковая дорожка, напоминающая волну.
- Затем эта волна преобразовывалась в двухмерную модель частот, которые человек может различать на слух.
- По частотам определялись фонемы — отдельные звуки речи, которые потом переводились в буквы, слова и предложения. Существует международный фонетический алфавит. В него включены звуки, которые может издавать человек с помощью губ, языка, зубов, неба. У каждого языка свои фонемы. Например, в русском часто встречается звук [r], а в английском — довольно редко. Фонемы — это еще не текст. Поэтому задача распознавания речи — перевести их в буквы, иными словами — в письменные единицы.
Для распознавания речи использовались три модели. Акустическая преобразовывала звук в фонемы. Лексикон (словарь произношений) сопоставлял фонемы с буквами. Языковая модель определяла, какое слово должно быть произнесено, соединяя предыдущие модели в единую систему, чтобы превращать устную речь в текст.
Как работает распознавание речи сейчас
С конца 2010-х старые алгоритмы распознавания речи стали вытесняться end-to-end-моделями. Сам процесс основан на двух моделях, но теперь они работают эффективнее благодаря машинному обучению.
- Акустическая. Раньше она преобразовывала речь в фонемы, а сейчас — сразу в буквы. Это работает за счет обучения на большом объеме данных и модели относительно большого размера.
- Языковая. Она анализирует контекст, выбирая наиболее вероятное слово, если разные варианты звучат одинаково (например, «night» и «knight»). Сегодня языковые модели обучаются на огромных объемах текстов, поэтому они могут точно предсказывать смысл и корректировать ошибки предыдущих этапов.
В end-to-end-подходе основную часть работы выполняет акустическая модель. Обычно она состоит из энкодера, который преобразует звук в представления, понятные модели, и декодера: он с помощью этих представлений генерирует текст. Энкодеры в целом довольно похожи. Как правило, это сверточная сеть или вариация модели Transformer. А вот декодирование в распознавании речи бывает разным. Так, есть три основных подхода для end-to-end-систем:
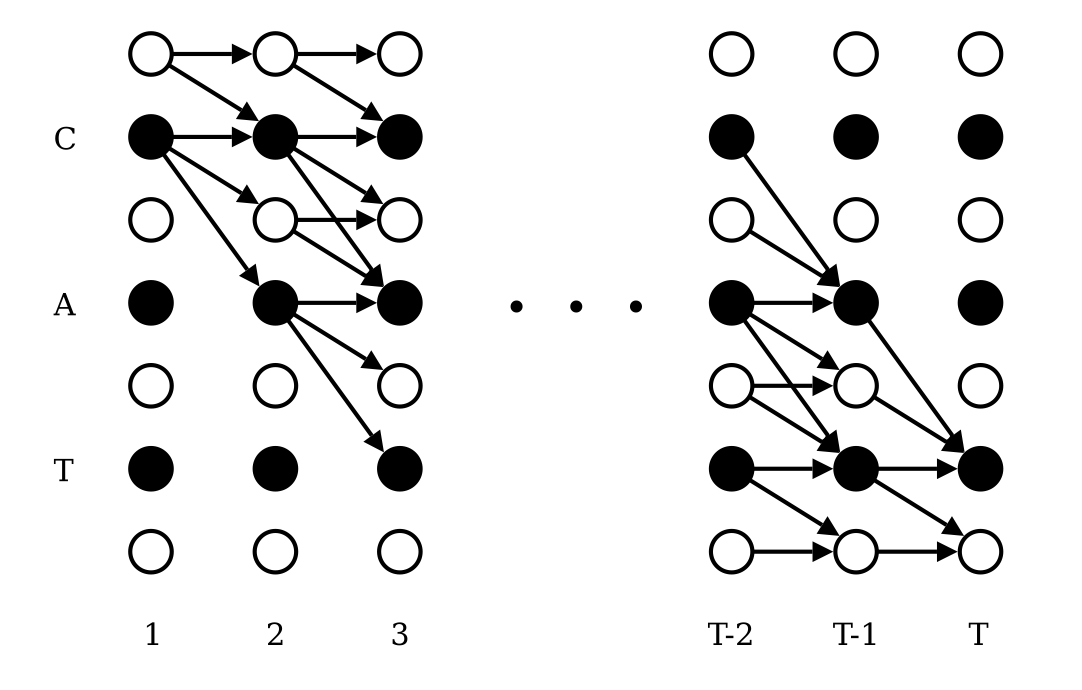
- CTC (Connectionist Temporal Classification) помогает расшифровывать речь, определяя, какой символ произнесен в каждый момент. Преимущество CTC в том, что он хорошо обучается, в том числе на больших объемах данных, и позволяет быстро применять модель в работе.
- RNN Transducer. Подходит для обработки звука по мере его поступления, иначе говоря — в стриминговом режиме. Может учитывать контекст и меньше подвержен ошибкам выравнивания, чем, например, CTC. Благодаря совместному обучению акустической и языковой моделей обеспечивает улучшенное качество транскрипций.
- LAS (Listen, Attend and Spell, другое название — Attention-based Encoder-Decoder). Имеет встроенную языковую модель наподобие ChatGPT, которая с помощью механизма внимания может учитывать всю входящую последовательность для каждого символа. Также благодаря механизму внимания можно использовать эту архитектуру для Speech Translation — перевода аудио на одном языке в текст на другом. LAS хорошо справляется с длинными записями, в которых важно учитывать глобальный контекст.
После распознавания текст проходит этап нормализации, чтобы стать читабельным. Во время него исправляется написание чисел (буквами или цифрами), расставляются знаки препинания, приводятся в порядок заглавные и строчные буквы, а имена собственные пишутся с большой буквы.
Иногда требуется не полная расшифровка текста, а только определенных частей, например запросов к умной колонке. В других случаях может понадобиться полное распознавание диалога, чтобы точно определить, кому принадлежат конкретные реплики. Эти задачи требуют разных подходов в технологии распознавания.
Где используют технологию распознавания речи
Телефония
Всё чаще с клиентами связываются не «живые» операторы, а роботы. Их речь сложно отличить от человеческой: они хорошо различают, что говорит абонент, реагируют на перебивание, имеют большой запас реплик. Еще есть голосовой набор, когда человеку нужно произнести нужное слово, и он сможет получить ответы на вопросы или решить проблему. В данном случае технология распознавания речи экономит время сотрудников и предоставляет более удобный сервис клиентам: им не придется ждать, пока освободится линия, потому что робот всегда на связи.
Умные устройства и голосовые помощники
Управлять разной техникой — от электрического чайника до выключателей — можно с помощью голоса. А чтобы это стало возможным, гаджеты используют ASR-технологию. То же самое касается умных колонок и голосовых помощников на мобильных устройствах, таких как Ok, Google или Siri.

Мессенджеры
Во всех соцсетях и мессенджерах есть голосовые сообщения. Но не все пользователи любят слушать их, поэтому разработчики внедряют ASR-технологию и добавляют функцию распознавания речи и преобразования ее в текст.
Рекрутинг
HR-специалисты тоже используют ASR. Например, чтобы провести первое интервью с соискателем. Робот звонит кандидату и выясняет стандартную информацию: образование, опыт, навыки. В процессе он сохраняет запись в CRM, а затем расшифровывает ее. HR-специалисты знакомятся с информацией и приглашают на следующий этап интервью только подходящих кандидатов. Благодаря технологии распознавания речи получится сэкономить время и сразу отсеять неподходящих соискателей.
Медицина
Есть сервисы, которые записывают голос врача, распознают его и вносят информацию в медицинские документы пациентов. Такие программы экономят время врачей и позволяют им работать более продуктивно, потому что избавляют от рутины. Пример такого сервиса — Voice2Med группы ЦРТ, который разработали в России в 2018 году.
Создание контента
Многие пользователи соцсетей смотрят видео без звука, особенно это касается коротких форматов. Поэтому авторам контента нужно добавлять субтитры. Благодаря технологии распознавания речи можно сделать это автоматически.
Это лишь часть сфер, где применяется ASR. Технология все больше проникает в повседневную жизнь и помогает решать рабочие задачи в разных отраслях — от IT до медицины.
С какими ограничениями сталкивается ASR-технология
В сфере распознавания речи несколько основных проблем.
- Недостаток данных для обучения ML-моделей. Необходимы не стерильные студийные аудиозаписи с простым текстом, а речь в реалистичных акустических условиях, со сложными темами и терминами.
- Модели, обученные на одном конкретном языке, не справляются с распознаванием смешанной речи. Это касается стран, где говорят на двух языках. Например, в Индии — на хинди и английском, в странах СНГ — на русском и государственном. Из-за этого человек, даже говоря на одном языке, добавляет слова из другого. Поэтому система распознавания речи не может идентифицировать некоторые части записи.
- Алгоритмы плохо работают с терминами. Если говорящий употребляет узкопрофильные слова из конкретной сферы, которых не было в обучении, модель зачастую не может их распознать.
Как будет развиваться технология
Скоро системы распознавания речи (ASR) начнут работать с большими языковыми моделями (LLM), обученными на огромных массивах данных. Это поможет решить проблему нехватки данных для узких задач и позволит точнее распознавать речь в разных ситуациях. Всё больше специалистов занимаются этим, а крупные компании уже внедряют LLM для улучшения точности и гибкости таких систем.
Модели также научатся понимать не только смысл слов, но и весь контекст, различать интонации и эмоции. Общение с голосовыми помощниками станет более естественным — особенно это важно для бизнеса.
Технология распознавания речи — главное
- Распознавание речи (STT) — это переведение устной речи в письменную. С помощью технологий искусственного интеллекта она преобразуется сначала в буквы, затем в слова и предложения, и после — в связный текст.
- Технология распознавания речи появилась еще в 1950-х, но получила мощный скачок в 2000-х благодаря развитию машинного обучения.
- Процесс распознавания речи основан на двух моделях — акустической и языковой. Сначала звуки преобразуются в буквы, затем система анализирует контекст, чтобы правильно выбрать слово из нескольких вариантов. Затем текст нормализуется: расставляются знаки препинания, строчные и прописные буквы, формируется диалог, если нужно.
- Чтобы адаптировать ML-модели под разные задачи, используются функции потерь — механизмы, которые совершенствуют алгоритмы. Для распознавания речи применяют CTC, RNN Transducer и LAS (Attention-based Encoder-Decoder).
- Технология распознавания речи используется во многих сферах, в том числе в медицине, телефонии, банковском деле, рекрутинге, создании контента и других.