


Чтобы не убить ML-проект, в Data Science важно хранить данные, прогресс, документацию и не копить технический долг. В программировании для всего этого уже давно есть Git. Но если попытаться загрузить в Git датасет с картинками на 50 гигабайт или тяжелые веса обученной нейросети (файлы .pth или .h5), репозиторий просто лопнет, процессы замедлятся до невыносимости, а GitHub вежливо (или с ошибкой push rejected) откажется принимать такой объем.
Именно здесь на сцену выходит DVC (Data Version Control) — незаменимый инструмент в машинном обучении и MLOps. Разберем его от А до Я простым языком, заглянем под капот и научимся строить профессиональные пайплайны.
Что такое DVC и как она работает
DVC (Data Version Control) — это консольная утилита с открытым исходным кодом, написанная на Python, которая работает поверх и совместно с Git. Она создана специально для проектов в сфере Data Science.

Главная философия DVC звучит так: мы продолжаем использовать Git для хранения кода и истории коммитов, но тяжелые данные и модели физически храним в другом надежном месте (в облаке, на NAS-сервере, на S3), а в Git кладем только крошечные текстовые «ссылки» на эти данные.
Почему DVC лучше Git LFS
Часто новички (да и опытные разработчики из классического IT) спрашивают: «Зачем мне учить какой-то DVC, если давно придуман Git LFS (Large File Storage)?»
Git LFS — отличный инструмент, но он создавался для геймдева и дизайнеров (чтобы хранить текстуры, 3D-модели и PSD-файлы). Для машинного обучения он подходит плохо по нескольким причинам:
- Привязка к серверу. Git LFS требует специального LFS-сервера (например, нужно покупать дорогие пакеты данных на GitHub). DVC абсолютно независим от хранилища. Нет бюджета? Настрой DVC на использование бесплатного Google Drive. Есть корпоративная инфраструктура? Подключи Amazon S3, MinIO, Azure Blob или просто папку на соседнем SSH-сервере.
- Отсутствие понимания ML-пайплайнов. Git LFS просто хранит файлы. DVC умеет строить графы вычислений (DAG), понимая, какой датасет нужен для какого скрипта, а еще может отслеживать метрики (Accuracy, F1-score).
Магия кэша: почему DVC не забивает жесткий диск?
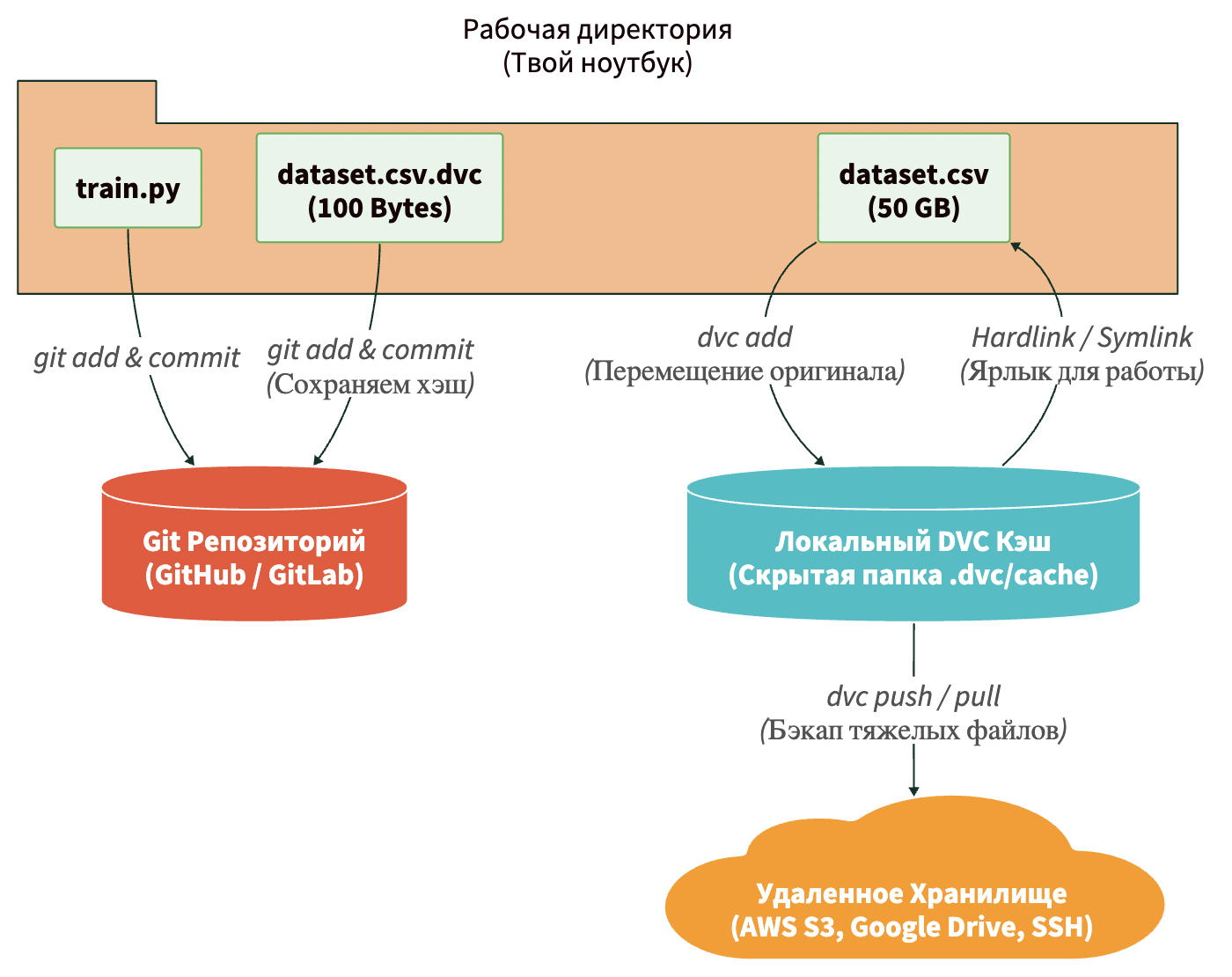
Это самый частый страх новичков. «Если у меня датасет 50 ГБ, и я делаю dvc add, DVC скопирует его в свой кэш? У меня будет занято 100 ГБ на диске?»
Ответ: нет! DVC невероятно умен. Когда добавляем файл в DVC, он физически перемещает этот файл в свою скрытую папку .dvc/cache. А в вашей рабочей папке он оставляет так называемый Hardlink (жесткую ссылку) или Symlink (символическую ссылку), в зависимости от твоей ОС. Для вас и ваших Python-скриптов этот файл выглядит и работает как обычный dataset.csv. Но физически на жестком диске он хранится в единственном экземпляре. Вы не теряете ни одного лишнего мегабайта!
Как установить DVC и привязать к хранилищу данных
Хватит теории, давай запачкаем руки в коде! Для работы нам понадобится установленный Python, Git и терминал.
Шаг 1. Создание окружения и установка
Правило хорошего тона в Python — использовать виртуальные окружения. Создадим проект:
mkdir my_ml_project cd my_ml_project # Создаем и активируем виртуальное окружение python -m venv venv source venv/bin/activate # Для Windows: venv\Scripts\activate # Устанавливаем DVC pip install dvc
Важное примечание: если вы планируете использовать специфичные облачные хранилища, DVC требует установки дополнительных плагинов. Например, для работы с Amazon S3 (или Yandex Cloud / Selectel, которые совместимы с S3) нужно писать: pip install dvc[s3]. Для Google Drive: pip install dvc[gdrive].
Шаг 2. Инициализация проекта
В корне нашей папки инициализируем сначала Git, а затем DVC. Порядок важен!
git init dvc init
Что произошло после команды dvc init? DVC создал скрытую папку .dvc, в которой лежат его конфигурационные файлы, и заботливо добавил правила в .gitignore, чтобы Git не лез в кэш DVC. DVC сам предлагает нам закоммитить эти базовые настройки:
git status git commit -m "Initialize DVC in the project"
Шаг 3. Настройка удаленного хранилища (Remote)
Для примера: представим, что у нас есть бакет (корзина) в Amazon S3 или совместимом хранилище (например, MinIO на сервере компании).
# Говорим DVC добавить хранилище типа s3 и называем его 'my_cloud' # Флаг -d (default) делает его хранилищем по умолчанию dvc remote add -d my_cloud s3://my-company-ml-bucket/project-data # Если хранилище требует авторизации, настраиваем ключи доступа # (В реальной жизни ключи лучше хранить в переменных окружения, но для примера покажем так) dvc remote modify my_cloud access_key_id 'YOUR_ACCESS_KEY' dvc remote modify my_cloud secret_access_key 'YOUR_SECRET_KEY' (Если у вас нет облака прямо сейчас, вы можете создать локальную папку вне проекта, например mkdir /tmp/dvc_remote, и подключить ее: dvc remote add -d local_remote /tmp/dvc_remote).
DVC записал информацию о хранилище в файл .dvc/config. Фиксируем это в Git:
git add .dvc/config git commit -m "Configure S3 remote storage"
Отлично! Фундамент заложен. Теперь мы готовы к настоящей магии версионирования.

Практический пример: версионирование датасетов и логирование
Представим, что мы решаем задачу предсказания цен на недвижимость. У нас есть папка data, а в ней — файл houses.csv размером 5 гигабайт.
Добавление данных под контроль
Если бы мы использовали только Git, мы бы по неопытности написали git add data/houses.csv и повесили бы наш репозиторий. Никогда так не делайте с большими файлами! Вместо этого делегируйте работу DVC.
mkdir data # Имитируем создание большого датасета (создаем файл с тремя строками) echo "area,rooms,price" > data/houses.csv echo "50,2,50000" >> data/houses.csv echo "80,3,90000" >> data/houses.csv # Добавляем файл в DVC! dvc add data/houses.csv
Что происходит под капотом в этот момент?
- DVC читает содержимое houses.csv и вычисляет его уникальный криптографический MD5-хэш (например, a1b2c3d4…).
- DVC прячет сам файл в свой кэш (.dvc/cache/a1/b2c3d4…), а в рабочей папке оставляет ссылку.
- DVC создает маленький текстовый файл-метаданных data/houses.csv.dvc. Внутри него записан этот самый хэш и размер файла.
- DVC добавляет строчку houses.csv в файл data/.gitignore.
Теперь мы коммитим в Git не сам датасет, а текстовый файл со ссылкой на него!
git add data/houses.csv.dvc data/.gitignore git commit -m "Add raw houses dataset v1"
А сами тяжелые данные (наши 5 ГБ) отправляем в облако S3:
dvc push
Все! Данные в безопасности. Наш GitHub весит пару килобайт, а тяжелые файлы надежно лежат в облаке.
Версионирование: Обновление датасета
Прошел месяц. Дата-инженеры собрали новые данные о ценах на элитные дома. Датасет обновился.
# Добавляем новые строки в датасет echo "120,4,150000" >> data/houses.csv echo "200,5,300000" >> data/houses.csv # Снова говорим DVC отследить изменения dvc add data/houses.csv
DVC пересчитал хэш, сохранил новую версию файла в кэш и обновил файл houses.csv.dvc. Снова фиксируем это:
git add data/houses.csv.dvc git commit -m "Update houses dataset to v2 (added luxury houses)" dvc push
Магия путешествий во времени (Time Travel)
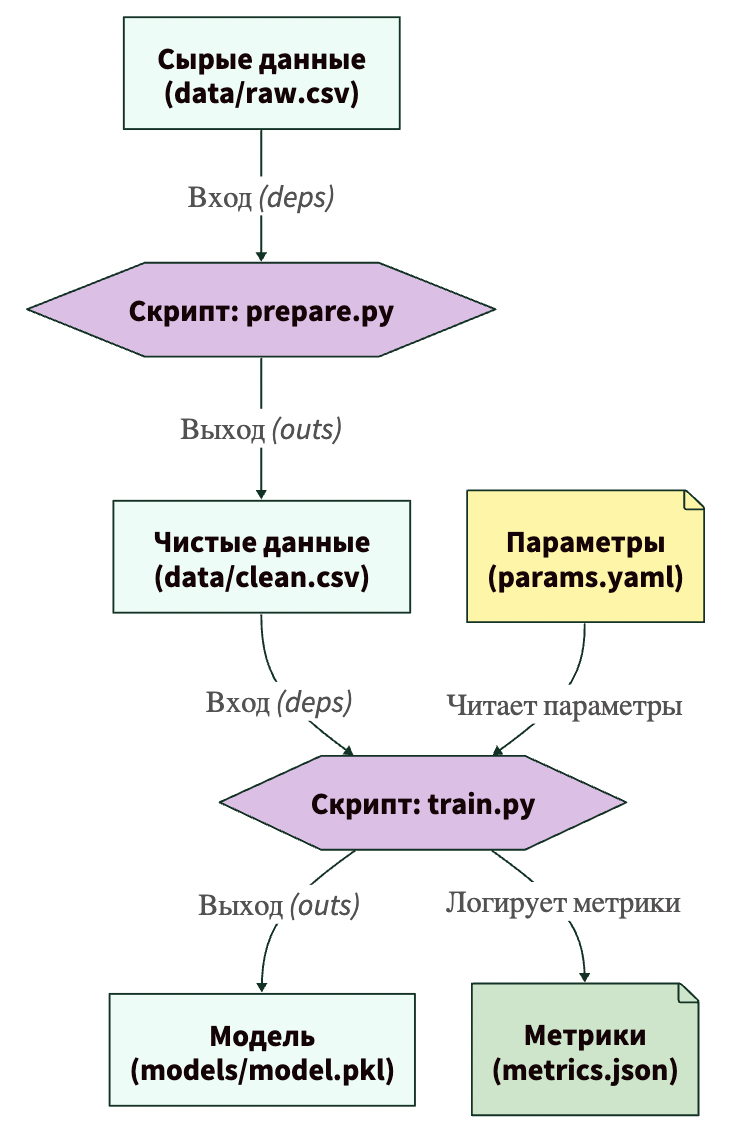
А теперь представь классическую ситуацию: наша модель, обученная на новых данных (v2), стала выдавать ужасные прогнозы в продакшене. Элитные дома сломали распределение. Нам нужно срочно откатиться к старым данным (v1), чтобы переобучить стабильную модель. Как это сделать?
Вот схема, которая объясняет весь процесс:
В терминале это две простые команды:
# 1. Откатываем Git на один коммит назад (к версии v1) git checkout HEAD~1 # 2. Говорим DVC синхронизировать реальные данные с текущими .dvc файлами dvc checkout
Если вы сейчас откроете файл data/houses.csv, вы увидите там ровно три строчки. Старый датасет вернулся за долю секунды! Вам не нужно вручную переименовывать папки, скачивать архивы из мессенджеров или искать старые флешки.
Совет: если вы случайно удалили файл houses.csv из папки data (удалил физически rm data/houses.csv), не паникуйте! Пока у вас есть файл houses.csv.dvc, достаточно написать dvc checkout, и DVC мгновенно восстановит удаленный файл из своего скрытого кэша.
Автоматизация пайплайнов с помощью DVC
До этого момента мы использовали DVC просто как «Git для больших файлов». Но его истинная мощь раскрывается в создании ML-пайплайнов (конвейеров).
Вспомните, как выглядит типичный проект начинающего дата-сайентиста. Это гигантский файл Untitled.ipynb на 1000 строк кода, где все смешано в кучу — загрузка данных из базы, очистка пропусков, генерация новых фичей (Feature Engineering), обучение случайного леса, отрисовка графиков. Если вы поменяете один гиперпараметр в самом конце (например, глубину дерева), придется перезапускать весь ноутбук сверху вниз, ожидая часами, пока данные заново скачаются и обработаются. Это чудовищно неэффективно.
В профессиональном ML код разбивают на отдельные независимые скрипты (шаги). DVC умеет строить DAG (Directed Acyclic Graph — Направленный ациклический граф). Он запоминает, какой скрипт какие данные потребляет, какие параметры он использует и какие файлы он выдает на выходе.
Внедрение гиперпараметров (params.yaml)
Создадим файл params.yaml в корне проекта. Это стандарт индустрии для хранения настроек модели.
# params.yaml train: n_estimators: 100 max_depth: 5 random_state: 42
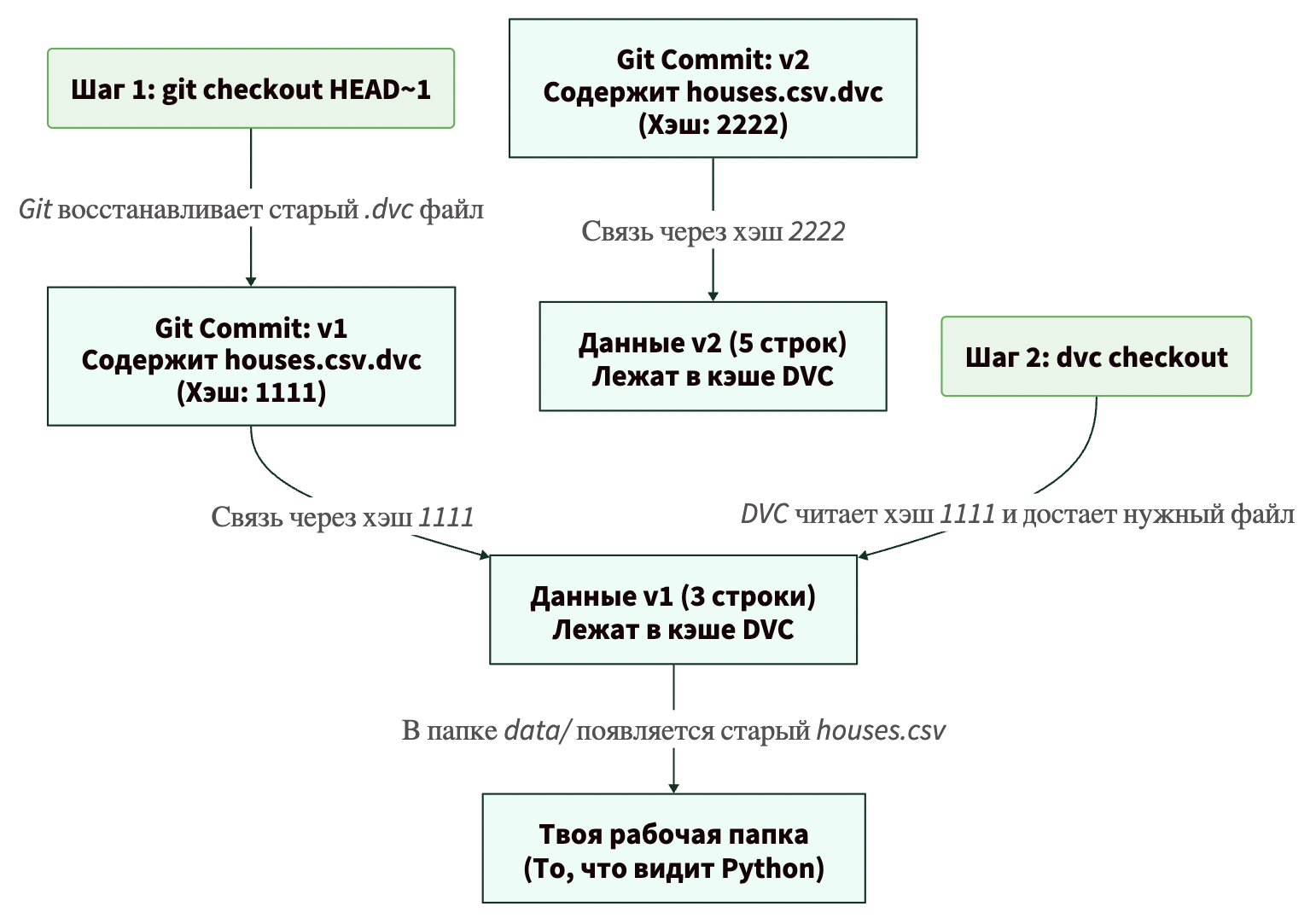
Давайте посмотрим на схему нашего будущего профессионального пайплайна:
Как настроить пайплайн (файл dvc.yaml)
Для создания конвейера используем файл dvc.yaml. Мы можем создавать этапы (stages) с помощью команды dvc stage add.
Этап 1: Подготовка данных. Мы говорим DVC: создай этап под названием prepare. Он зависит (-d, dependencies) от скрипта prepare.py и сырых данных raw.csv. На выходе (-o, outputs) он выдает файл clean.csv. Команда для запуска — python src/prepare.py.
dvc stage add -n prepare \ -d src/prepare.py -d data/raw.csv \ -o data/clean.csv \ python src/prepare.py
Этап 2: Обучение модели и логирование метрик. Этот этап сложнее. Он зависит от чистых данных и скрипта обучения. Также мы указываем, что он зависит от параметров (-p train) из файла params.yaml. На выходе — файл модели (-o) и файл с метриками (-M, metrics), например, Accuracy.
dvc stage add -n train \ -d src/train.py -d data/clean.csv \ -p train \ -o models/model.pkl \ -M metrics.json \ python src/train.py
После этих команд DVC сгенерирует файл dvc.yaml:
stages: prepare: cmd: python src/prepare.py deps: - data/raw.csv - src/prepare.py outs: - data/clean.csv train: cmd: python src/train.py deps: - data/clean.csv - src/train.py params: - train outs: - models/model.pkl metrics: - metrics.json: cache: false
Магия команды dvc repro
Чтобы запустить весь пайплайн машинного обучения, достаточно написать в терминале одну короткую команду:
dvc repro
DVC проанализирует граф зависимостей. Он выполнит prepare.py, дождется завершения, возьмет clean.csv и передаст его в train.py.
А теперь представьте киллер-фичу: вы открываете params.yaml и меняете max_depth с 5 на 10. Сохраняете файл и снова пишете dvc repro. DVC — потрясающе умный инструмент. Он проверит хэши всех файлов и скажет: «Ага! Файл raw.csv и скрипт prepare.py не менялись. Значит, файл clean.csv остался абсолютно таким же. Я пропущу этап prepare (сэкономлю тебе два часа вычислений) и запущу только этап train, потому что изменились параметры!»
Вы больше никогда не будете выполнять лишнюю работу. DVC кэширует результаты каждого шага. А чтобы посмотреть, как изменение параметра повлияло на метрики, просто введите:
dvc metrics diff
И DVC покажет вам красивую таблицу в консоли:
Path Metric Old New Change
metrics.json accuracy 0.85 0.92 0.07
Увеличение глубины дерева подняло точность на 7%. Идеально!
Командная работа: как DVC спасает нервы коллегам
Давайте рассмотрим реальный сценарий. Вы настроили DVC, запушили код в GitHub, а данные в Amazon S3, и ушли в отпуск. В команду приходит новый Data Scientist — назовем его Вася. Ему нужно продолжить вашу работу.
Как бы Вася страдал без DVC: искал бы доступы к базам данных, просил бы коллег скинуть «тот самый csv», пытался бы понять, в каком порядке запускать ячейки в вашем ноутбуке.
Как выглядит первый рабочий день Васи с DVC:
- Вася клонирует репозиторий с кодом:
git clone https://github.com/your-company/my_ml_project.git
cd my_ml_project
- Вася видит папки с кодом, файл dvc.yaml и маленькие файлы .dvc. Но самих данных (папки data/) и моделей у него пока нет.
- Вася настраивает доступы к облаку S3 (вводит ключи).
- Вася пишет одну единственную команду:
dvc pull- В этот момент DVC читает все .dvc файлы и dvc.yaml, связывается с Amazon S3 и скачивает ровно те версии тяжелых датасетов и моделей, которые соответствуют текущему коммиту в Git. Через 5 минут у Васи на компьютере полностью готовое, на 100% воспроизводимое рабочее окружение. Он может сразу писать dvc repro и проводить свои эксперименты. Это уровень зрелого MLOps!
Когда не стоит использовать DVC?
DVC — это не серебряная пуля. Если вы работаете со строго потоковыми данными (например, Streaming Data — это логи кликов пользователей в реальном времени, которые меняются каждую секунду), DVC вам не поможет. Он создан для батчевой (пакетной) обработки файлов.
Также для логирования сложных экспериментов с Deep Learning (где сотни эпох и графиков) лучше использовать DVC в связке с инструментами вроде MLflow или Weights & Biases (DVC для данных, W&B для графиков).
DVC: коротко о главном
- Git не всесилен. Хранить датасеты и веса моделей в GitHub — это путь к тормозящим репозиториям и боли.
- DVC — это элегантный мост между кодом и данными. Он заменяет тяжелые файлы на легковесные ссылки-хэши, которые мы безопасно коммитим в Git. Сами терабайты данных улетают в облако (S3, GDrive, NAS). При этом DVC использует систему ссылок в ОС, чтобы не дублировать файлы на вашем жестком диске.
- Путешествия во времени и воспроизводимость — это просто. Комбинация git checkout и dvc checkout позволяет мгновенно восстанавливать состояние проекта (и кода, и данных!) на любой момент в прошлом.
- DAG-пайплайны экономят время и деньги. Использование dvc.yaml, params.yaml и команды dvc repro позволяет запускать только те этапы машинного обучения, которые реально требуют пересчета.
- Командная работа выходит на новый уровень. Онбординг новых сотрудников сводится к командам git clone и dvc pull.
Внедрение DVC в свою рутину поначалу может показаться сложным и непривычным. Придется держать в голове, что теперь нужно делать dvc add перед git add. Это нормально! Когда-то и обычный Git казался магией с непонятными командами.
Но стоит один раз настроить DVC в своем пет-проекте или на работе, и вы больше никогда не захотите возвращаться к папкам с названиями data_final_v3_really_final_use_this. Ваши проекты станут структурированными, инженерно грамотными, а коллеги (или рекрутеры на собеседовании) будут в полном восторге от того, насколько профессионально у выстроен процесс.