


Если вы только начинаете свой путь в машинном обучении, то наверняка уже столкнулись с тем, что реальные данные — это не всегда аккуратные таблички с цифрами. Реальный мир полон текста: названия городов, марки автомобилей, цвета, дни недели, профессии.
В машинном обучении такие данные называются категориальными признаками. И сегодня мы поговорим о том, как правильно скармливать такие данные нашим алгоритмам. Мы разберем эту тему от самых азов до продвинутых техник, которые используют победители международных соревнований. Я постараюсь объяснить все максимально простым языком, с примерами из жизни, кодом и схемами.
Зачем вообще нужно преобразовывать категориальные признаки?
Давайте начнем с главного: почему мы просто не можем загрузить текст в модель?
Представьте, что вы пришли в супермаркет и пытаетесь расплатиться за хлеб… яблоками. Кассир смотрит на вас с недоумением. Касса принимает только рубли или банковские карты. Яблоко — это ценный ресурс, его можно съесть, но для кассового аппарата оно не имеет смысла, пока вы не конвертируете его в деньги (например, продав яблоки на рынке).

Точно так же работают модели машинного обучения. Будь то линейная регрессия, случайный лес или нейронная сеть — «под капотом» у них находится чистая математика. Это уравнения, матрицы, производные и градиенты. Компьютер не знает, что такое «Красный» или «Москва». Он не умеет умножать слово «Toyota» на вес 0.5 — ему нужны числа.
Поэтому главная задача в предобработке данных (Data Preprocessing) — перевести категории в числа так, чтобы не потерять смысл, а в идеале — помочь модели найти скрытые закономерности.
Категориальные признаки глобально делятся на два типа:
- Порядковые (Ordinal). В них есть естественный порядок. Например: размер одежды (S, M, L, XL), уровень образования (среднее, бакалавр, магистр), оценка состояния авто (плохое, нормальное, отличное). Мы точно знаем, что L больше M, а магистр круче бакалавра.
- Номинальные (Nominal). В них нет никакого порядка. Например, это может быть цвет машины (красный, синий, зеленый), город (Москва, Казань, Владивосток). Красный цвет не «больше» и не «лучше» синего, они просто разные.
Именно от типа признака зависит то, какой метод преобразования (энкодинга) мы выберем. А теперь поехали разбирать конкретные методы!
«Порядковое кодирование» (Label Encoder)
Это самый простой и интуитивно понятный способ. Идея Label Encoder (или Ordinal Encoder) заключается в том, чтобы просто взять все уникальные значения категории и присвоить каждому из них целое число: 0, 1, 2, 3 и так далее.
Пример из жизни: представьте электронную очередь в банке. Вы приходите, берете талончик. Клиент А получает номер 0, клиент Б — номер 1, клиент В — номер 2.
Когда стоит использовать Label Encoder?
Этот метод идеально подходит для порядковых признаков. Допустим, мы предсказываем зарплату человека, и у нас есть признак «Уровень английского»: Beginner, Intermediate, Advanced. Мы можем закодировать их как:
- Beginner = 0;
- Intermediate = 1;
- Advanced = 2.
В этом случае модель (особенно основанная на деревьях решений) легко поймет логику: чем больше число, тем выше уровень. Сохраняется естественный порядок, и алгоритм может сделать правило вида: «Если уровень английского > 0.5 (то есть Intermediate и выше), то нужно прибавить к прогнозу зарплаты 50 000 рублей».
Почему Label Encoder опасен для номинальных признаков?
А теперь представим, что у нас нет порядка. Мы предсказываем цену автомобиля, и у нас есть признак «Цвет»:
- красный = 0;
- синий = 1;
- зеленый = 2.
Что произойдет? Мы искусственно внедрили математическую зависимость туда, где ее никогда не было! Модель посмотрит на эти числа и сделает ложные выводы:
- Она решит, что зеленый (2) в два раза «больше» или «важнее», чем Синий (1).
- Она решит, что красный (0) вообще ничего не значит (ведь умножение на ноль дает ноль в линейных моделях).
- Она может решить, что среднее между красным (0) и зеленым (2) — это синий (1). Но ведь смешение красного и зеленого не дает синий цвет, это абсурд!
Особенно сильно от этого страдают линейные модели (Linear/Logistic Regression) и нейросети. Деревья решений (Random Forest, XGBoost) справляются с этим чуть лучше, так как они просто дробят пространство (например, делают сплит «Цвет < 1.5»), но даже для них это не оптимально, потому что им придется делать много лишних разбиений, чтобы отделить один цвет от другого.
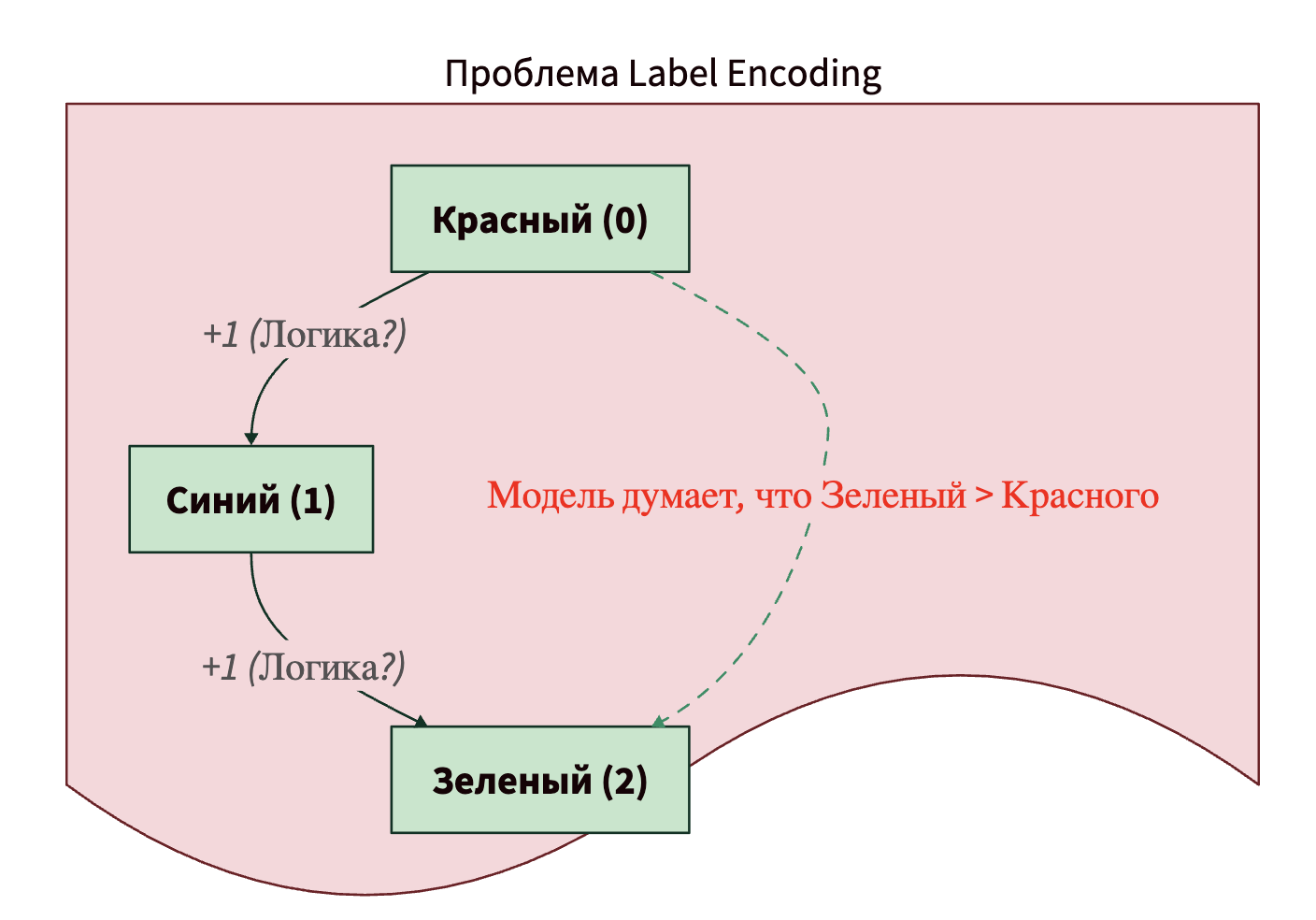
Резюме по Label Encoder: используйте только тогда, когда в данных есть четкий, логичный порядок (размер, рейтинг, уровень). Для независимых категорий (города, имена, цвета) этот метод лучше не применять.
«Кодирование частотой» (Frequency Encoder)
Если Label Encoder просто раздает случайные номера, то Frequency Encoder подходит к делу с точки зрения статистики. Идея проста: мы заменяем категорию на то, как часто она встречается в нашем датасете (либо абсолютным числом, либо в процентах).
Пример из жизни: представьте, что вы выбираете ресторан в незнакомом городе. Вы не знаете названий (категорий), но вы видите, сколько людей сидит внутри. Ресторан А — 150 человек, ресторан Б — 2 человека. Вы, скорее всего, выберете ресторан А, потому что его популярность (частота) говорит о его качестве. Мы заменили сложное название на понятную метрику популярности.
Допустим, у нас есть данные о продажах телефонов:
- iPhone — встречается 500 раз;
- Samsung — встречается 300 раз;
- Xiaomi — встречается 195 раз;
- неизвестный_китайский_бренд — встречается 5 раз.
Frequency Encoder заменит текст «iPhone» на 500 (или на 0.5, если в долях), «Samsung» — на 300 (0.3) и так далее.
Почему это работает?
В машинном обучении часто бывает так, что редкие категории ведут себя иначе, чем частые. Например, редкие, эксклюзивные марки автомобилей могут стоить аномально дорого или, наоборот, редкие неизвестные бренды ломаются чаще. Кодируя частотой, мы даем древовидным моделям (Random Forest, LightGBM) отличную возможность отделить «масс-маркет» от «эксклюзива/выбросов». Дерево просто сделает сплит: «Если частота категории < 10, то это редкий зверь, применяем к нему отдельную логику».
Минусы Frequency Encoder
Главная проблема этого метода — коллизии. Что, если в наших данных автомобили марки Lada встречаются ровно 150 раз и автомобили марки BMW тоже встречаются ровно 150 раз? Энкодер заменит обе марки на число 150. Для модели они станут абсолютно неразличимы! Модель подумает, что Lada и BMW — это одно и то же, потому что у них одинаковая частота. А ведь цены на них кардинально разные.
Поэтому Frequency Encoder редко используют как единственный метод. Обычно его добавляют как дополнительный признак к другим видам кодирования, чтобы дать модели информацию о популярности категории.
«Горячее кодирование» (OHE, One-Hot-Encoder)
Вот мы и добрались до классики. Если вы спросите любого дата-сайентиста, как закодировать цвет машины, в 90% случаев он ответит: «Используй OHE».
Идея One-Hot-Encoder невероятно изящна: вместо того чтобы впихивать все категории в одну колонку, давайте создадим для каждой уникальной категории свою бинарную колонку (где 1 – это «Да», а 0 – это «Нет»).
Пример из жизни: представьте анкету при приеме на работу. Вместо того чтобы писать в пустом поле «Какие языки программирования вы знаете?», вам дают чек-лист (список с плюсами):
- Python(+);
- C++(0);
- SQL(+);
- Java.(0)
Вы ставите 1 (плюс) там, где это правда, и 0 (пусто) там, где это ложь. Это и есть One-Hot Encoding.
Допустим, у нас есть колонка «Цвет» с тремя значениями — красный, синий, зеленый. OHE превратит ее в три новые колонки — Цвет_Красный, Цвет_Синий, Цвет_Зеленый. Если машина красная, строка будет выглядеть так: [1, 0, 0]. Если зеленая, то вот так: [0, 0, 1].
«Ловушка фиктивных переменных» (Dummy Variable Trap) и правило n-1
Здесь кроется один из самых важных математических нюансов, о котором часто забывают новички.
Если у нас есть три возможных цвета, нам не нужны три колонки. Нам достаточно двух (n-1). Почему? Потому что если машина НЕ красная (0) и НЕ синяя (0), то она гарантированно зеленая (1). Третья колонка не несет никакой новой информации, она избыточна.
В математике это называется линейной зависимостью (или мультиколлинеарностью). Сумма значений всех трех колонок для любой строки всегда будет равна 1. Для алгоритмов, основанных на деревьях, это не так страшно. Но для линейной регрессии это катастрофа. Под капотом линейной регрессии происходит обращение матриц. Если в матрице есть линейно зависимые столбцы, а ее определитель (детерминант) равен нулю, матрица становится вырожденной, и в этом случае математика ломается (веса модели могут улететь в бесконечность).
Поэтому при использовании OHE в линейных моделях всегда удаляют одну колонку (базовую категорию). В Pandas это делается параметром drop_first=True в функции pd.get_dummies().
Линейные модели vs бустинги: отношение к OHE
- Линейные модели обожают OHE. Для них это идеальный формат. Модель просто подберет отдельный вес (коэффициент) для каждого цвета. Например, +500$ — за красный, -200$ — за зеленый. Все кристально ясно.
- Градиентные бустинги (деревья) ненавидят OHE, если категорий много. Представьте, что у вас есть колонка «Город», в которой 1000 разных городов. OHE создаст 1000 колонок, состоящих почти целиком из нулей (разреженная матрица). Как работает дерево решений? Оно ищет признак, по которому можно разделить данные пополам. Но колонка Город_Москва разделит данные на «Москву» (малая часть) и «Все остальные 999 городов» (огромная часть). Дереву придется расти невероятно глубоко, чтобы отделить каждый город. Данные сильно фрагментируются (дробятся на мелкие куски), и дерево быстро переобучается или работает очень неэффективно.
Что же делать, если у нас категориальный признак с сотнями уникальных значений (высокая кардинальность), а мы хотим использовать мощный градиентный бустинг? Тут на сцену выходят «тяжеловесы» машинного обучения.

«Кодирование по таргету» (Target Encoding / Mean Encoding)
Это излюбленный метод участников соревнований на Kaggle. Он невероятно мощный, но при этом таит в себе смертельную опасность для вашей модели, если использовать его неправильно.
Идея Target Encoding: давайте заменим категорию на среднее значение целевой переменной (таргета) для этой категории.
Пример из жизни: представьте, что вы хотите предсказать, как хорошо школьник сдаст ЕГЭ (целевая переменная от 0 до 100 баллов). У вас есть категориальный признак — «Номер школы». Вместо того чтобы делать OHE (что создаст тысячи колонок для каждой школы), вы смотрите в исторические данные:
- лицей №1: исторически средний балл выпускников = 85;
- школа №5: исторически средний балл выпускников = 50.
Вы заменяете «Лицей №1» на число 85, а «Школу №5» на число 50. Гениально? Да! Мы сжали огромную категорию в одно сверхинформативное число, которое напрямую коррелирует с тем, что мы хотим предсказать. Деревья решений просто обожают такие признаки.
«Смертельная» опасность: утечка данных (Data Leakage)
Если вы просто возьмете весь свой обучающий датасет (train), посчитаете средние значения таргета по группам и подставите их, вы совершите грубейшую ошибку. Это называется Data Leakage (утечка ответов в признаки).
Представьте, что в ваших данных есть «Школа №999», из которой в датасете есть всего один ученик. И этот гений сдал ЕГЭ на 100 баллов. Если вы посчитаете среднее по всей выборке, вы замените «Школа №999» на 100. Модель во время обучения посмотрит на эту строку и увидит: признак = 100, таргет = 100. Модель скажет: «Ого! Я поняла! Ответ всегда равен этому признаку!». Модель мгновенно переобучится, запомнив эти значения. А когда в тестовых данных (test) придет обычный троечник из «Школы №999», модель уверенно предскажет ему 100 баллов и жестоко ошибется.
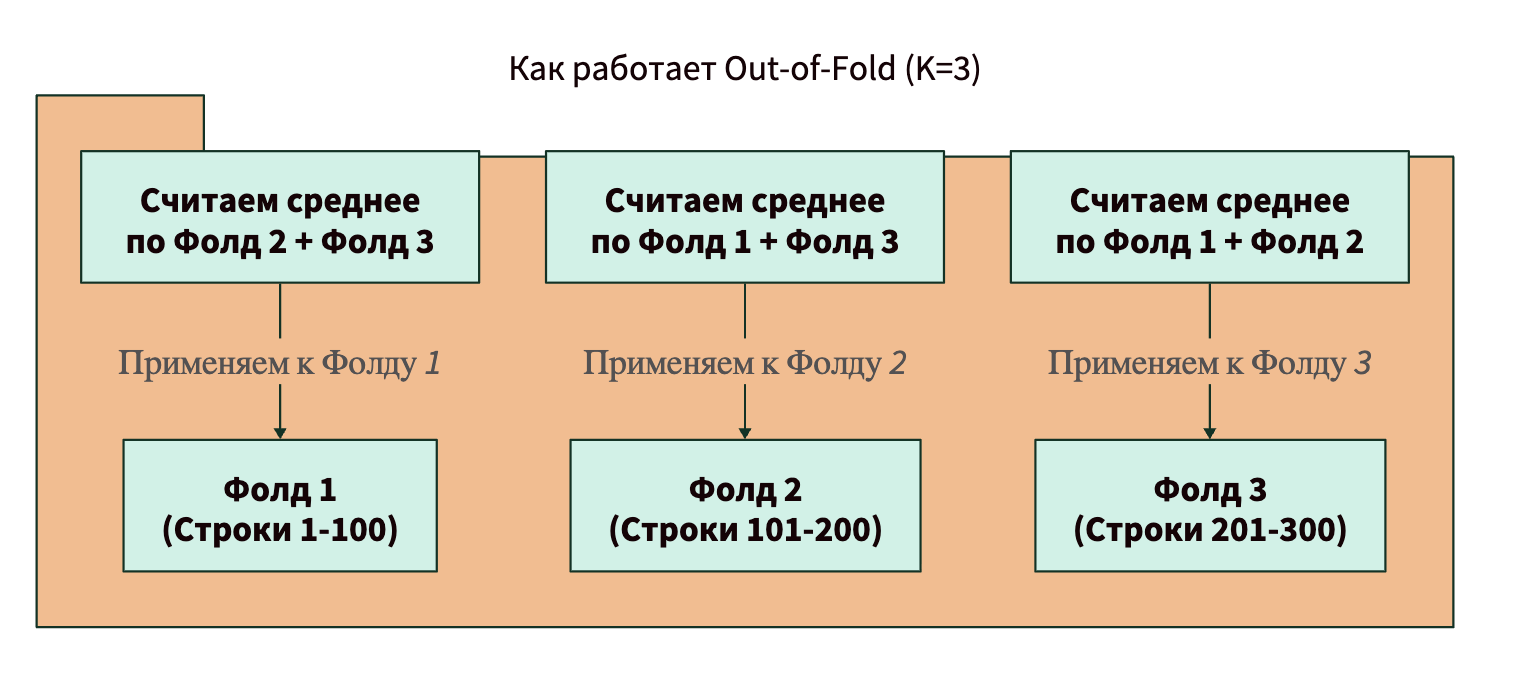
Решение 1: разбиение по фолдам (Out-of-Fold, OOF)
Чтобы избежать утечки, мы должны считать среднее значение для текущей строки, не используя саму эту строку.
Как это делается на практике:
- Делим весь обучающий датасет на K частей (фолдов) — например, на 5.
- Берем 1-й фолд. Чтобы закодировать категории в нем, мы считаем средние значения таргета только на фолдах 2, 3, 4 и 5.
- Берем 2-й фолд. Кодируем его, используя статистику из фолдов 1, 3, 4, 5.
- Дальше по этой механике примерно то же самое.
Таким образом, строка никогда не «видит» свой таргет при кодировании. Это имитирует реальную ситуацию, когда мы предсказываем будущее на основе прошлого.
Решение 2: сглаживание (Smoothing / Regularization)
Разбиение по фолдам решает проблему подглядывания в ответ, но не решает проблему редких категорий. Если в обучающих фолдах «Школа №999» встретилась два раза со средним баллом 100, мы все равно не можем доверять этой статистике. Выборка слишком мала!
Поэтому в Target Encoding всегда применяют сглаживание (smoothing). Суть сглаживания: если данных по категории мало, мы не доверяем среднему значению этой категории и «подтягиваем» его к глобальному среднему значению по всему датасету. Если данных много — мы верим локальному среднему.
Математически это часто выражается следующей формулой:
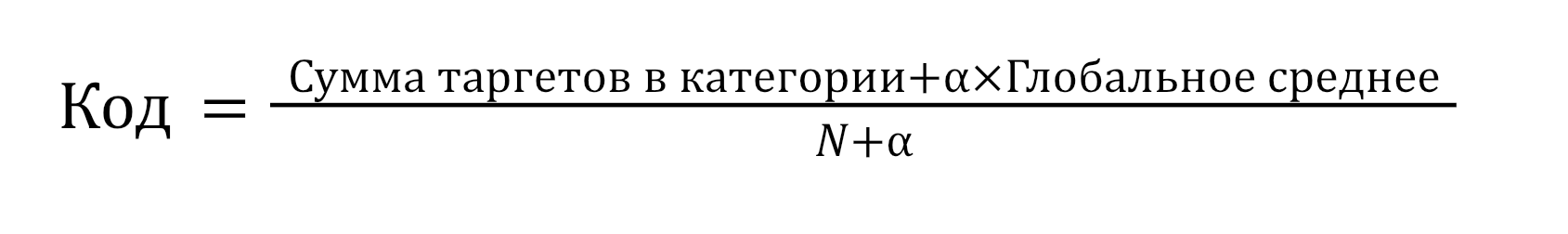
Где:
- N — количество строк (наблюдений) с данной категорией.
- Альфа — гиперпараметр сглаживания. Чем он больше, тем сильнее мы тянем значения к глобальному среднему.
- Глобальное среднее — среднее значение таргета по всему датасету.
Примечание: иногда формулу записывают через локальное среднее (Mean), тогда числитель выглядит как:
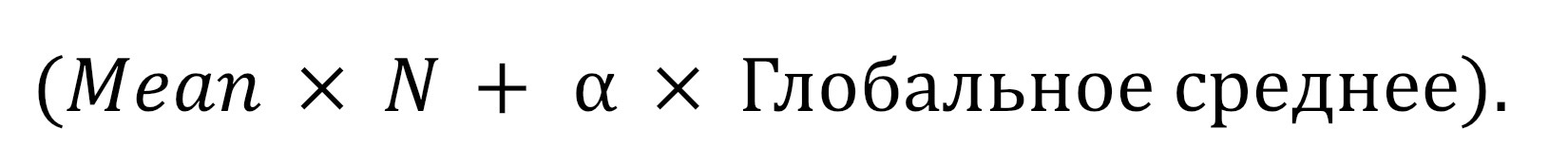
Давайте разберем на пальцах: допустим, глобальный средний балл по всем школам города = 60. Установим альфа = 10.
- Сценарий А (школа-гигант). В школе №1 учится N=1000 человек. Их сумма баллов = 80 000 (локальное среднее 80). Считаем: (80000 + 10 * 60) / (1000 + 10) = 80600 / 1010 ≈ 79.8. Как видите, из-за того, что N огромное, сглаживание почти не повлияло. Мы верим этой школе.
- Сценарий Б (редкая школа). В школе №999 учится N=1 человек, сдавший на 100 баллов (сумма = 100). Считаем: (100 + 10 * 60) / (1 + 10) = (100 + 600) / 11 = 700 / 11 ≈ 63.6. Магия! Несмотря на то что единственный ученик сдал на 100, мы не ставим кодировку 100. Из-за того, что N мало, значение «сдвинулось» от 100 очень близко к глобальному среднему (60). Модель не будет переобучаться на этом выбросе!
Target Encoding со сглаживанием и фолдами — это ультимативное оружие, которое позволяет сжимать категории любой размерности (хоть миллион уникальных значений) в один мощный числовой признак, скоррелированный с целевой переменной.
CatBoost Encoding
Если Target Encoding так хорош, можно ли сделать его еще лучше? Создатели библиотеки CatBoost ответили: «Да!». Они придумали элегантный способ избавиться от сложной возни с фолдами (которая отнимает время и ресурсы), решив проблему Data Leakage прямо на лету.
Их метод, известный как Ordered Target Encoding («Упорядоченное кодирование по таргету»), использует концепцию искусственного времени.
Пример из жизни: представьте, что вы читаете детективную книгу. Вы пытаетесь угадать убийцу на 100-й странице. Чтобы сделать прогноз, вы можете использовать только ту информацию, которую прочитали на страницах с 1 по 99. Вы не можете заглянуть на 200-ю страницу, иначе это будет читерство (утечка данных).
Алгоритм CatBoost делает то же самое с вашим датасетом:
- Он случайным образом перемешивает все строки в обучающей выборке. Теперь у строк есть «исторический порядок» от верхней к нижней.
- Для каждой строки i он считает среднее значение таргета для ее категории, используя только строки, которые находятся выше нее (от 0 до i-1).
- Строки, которые находятся ниже i, «еще не наступили в будущем», поэтому они не используются.
Давайте посмотрим на мини-примере. У нас есть датасет из четырех машин (уже перемешанный). Мы кодируем марку Ford. Таргет — купили (1) или нет (0).
| Строка (время) | Марка | Таргет | Что видит строка (история Ford) | Результат кодирования (без учета сглаживания) |
| 1 | Ford | 1 | Ничего. Это первый Ford. | Глобальное среднее (т. к. истории нет) |
| 2 | BMW | 0 | — | — |
| 3 | Ford | 0 | Строка 1 (Таргет=1) | 1 / 1 = 1.0 |
| 4 | Ford | 1 | Строки 1, 3 (Таргеты 1, 0) | (1 + 0) / 2 = 0.5 |
Почему это гениально?
- Нет никакого подглядывания в будущее. Строка никогда не использует свой таргет для своего кодирования.
- Не нужно разбивать данные на фолды, обучать несколько моделей и тратить память.
- Модель естественным образом учится на данных, которые постепенно накапливают статистику.
Конечно, в реальности CatBoost тоже использует сглаживание (prior), формулы которого похожи на те, что мы разбирали в Target Encoding. Кроме того, чтобы результат не зависел от одной неудачной случайной перетасовки, CatBoost внутри себя делает несколько разных случайных перестановок (permutations) и усредняет результаты.
Этот метод встроен прямо в алгоритм градиентного бустинга CatBoost. Вам даже не нужно делать это руками (через Pandas или Scikit-learn). Достаточно просто указать модели: cat_features=[‘Бренд’, ‘Город’], и она под капотом применит эту сложную, защищенную от утечек математику. Именно поэтому CatBoost часто побеждает «из коробки» на табличных данных с большим количеством категорий.
Категориальные признаки в Machine Learning: коротко о главном
Самое важное правило, которое вы должны вынести из этой статьи: в машинном обучении нет «серебряной пули». Нет одного идеального метода, который нужно использовать всегда и везде. Выбор энкодера зависит от двух вещей: типа ваших данных и типа вашей модели.
Давайте подведем итог в виде шпаргалки:
- Label / Ordinal Encoder:
- Когда использовать: только для порядковых признаков (маленький, средний, большой).
- Плюсы: сохраняет логику размера/порядка.
- Минусы: губителен для номинальных данных, особенно в линейных моделях (создает ложные зависимости).
- Frequency Encoder:
- Когда использовать: в связке с деревьями решений, когда важно выделить редкие или частые события.
- Плюсы: помогает находить аномалии и «мейнстрим».
- Минусы: риск коллизий (разные категории с одинаковой частотой становятся неотличимы).
- One-Hot-Encoder (OHE):
- Когда использовать: для номинальных признаков с низкой кардинальностью (мало уникальных значений: пол, цвет, день недели). Обязателен для линейных моделей и нейросетей.
- Плюсы: никаких ложных математических зависимостей, кристальная понятность.
- Минусы: раздувает датасет. Убивает производительность градиентного бустинга, если уникальных категорий сотни или тысячи. Не забывайте про правило n-1 (Dummy Variable Trap) для линейной регрессии!
- Target Encoding:
- Когда использовать: для номинальных признаков с высокой кардинальностью (города, ID пользователей, почтовые индексы), особенно при работе с древовидными моделями (XGBoost, LightGBM, Random Forest).
- Плюсы: сжимает огромные категории в один сверхполезный признак.
- Минусы: огромный риск переобучения (Data Leakage). Требует аккуратной настройки фолдов (OOF) и обязательного сглаживания (Smoothing).
- CatBoost Encoding:
- Когда использовать: когда вы работаете с библиотекой CatBoost или хотите получить преимущества Target Encoding без ручной возни с фолдами.
- Плюсы: изящное решение проблемы утечки данных через «исторический порядок». Высочайшее качество «из коробки».
- Минусы: вычислительно затратно перетасовывать данные несколько раз (хотя библиотека делает это оптимизировано на C++).
Не бойтесь экспериментировать, ведь часто лучший результат дает комбинация методов. Например, вы можете применить OHE для топ-10 самых популярных городов, а все остальные редкие города сгруппировать в категорию «Другое» и применить к ним Frequency Encoding.
Пишите чистый код, не допускайте утечек данных, и пусть ваши метрики на валидации всегда растут и удачи в ваших ML-проектах!