


Искусственный интеллект стал незаменимым помощником в работе. Он отвечает на вопросы, помогает составлять отчеты и даже генерирует уникальный контент. Но создание такого AI-ассистента с нуля способна позволить себе далеко не каждая компания. В этом случае можно использовать опенсорсную модель LLM. Что это такое — рассказываем в статье.
Что такое LLM
LLM (Large Language Model) — это языковая модель, обученная на большом количестве данных.

Это тип искусственного интеллекта, который специально разработан для работы с текстами. Он может их понимать и анализировать, писать самостоятельно, давать ответы на вопросы.
Самый известный разработчик LLM сегодня — американская компания OpenAI. Однако есть и другие: например, свою LLM развивает Meta* (модели OPT, OPT-IML и LLaMA), а также Google (PaLM, Gemini и BERT).

Что умеют LLM
LLM используют для самых разных задач:
- чат-бот: выполняет роль консультанта и отвечает на типовые вопросы;
- создание контента: может написать пост для социальных сетей, список вопросов для интервью, сценарий для ролика, статью или даже целую книгу. Причем на это уйдет совсем немного времени;
- многоязычный перевод: переводит текст на разные языки и пишет программный код (например, модель Code Llama);
- анализ и резюмирование: может быстро изучить большой объем данных, выписать основные итоги в простой и понятный список;
- интеллектуальный поиск: находит нужную информацию и предоставляет исчерпывающие ответы.
Как обучают LLM
Процесс обучения языковой модели можно разделить на несколько этапов:
- Сбор данных: в качестве источников могут выступать книги, сайты в интернете, статьи. Важно, чтобы модель училась на разных примерах и большом количестве данных.
- Обработка: информацию делят на более мелкие части, чтобы модель могла понять структуру языка.
- Обучение: для этого используют специальный алгоритм. Например, модель пытается предсказать следующее слово в предложении, основываясь на предыдущих словах. При ошибке алгоритм корректирует ее, чтобы в следующий раз она могла предсказать лучше. Этот процесс повторяется миллионы раз, поэтому требует больших вычислительных мощностей и занимает много времени.
- Тестирование и доработка: инженеры оценивают, насколько хорошо модель справляется с различными задачами. Важно, чтобы финальное тестирование проходило на новых данных, которые LLM еще не видела. При необходимости модель дорабатывают и улучшают.
После этого LLM загружают в приложение, где она может начать работу. При этом разные модели будут давать разные ответы на один и тот же вопрос, ведь они обучались на разных данных.
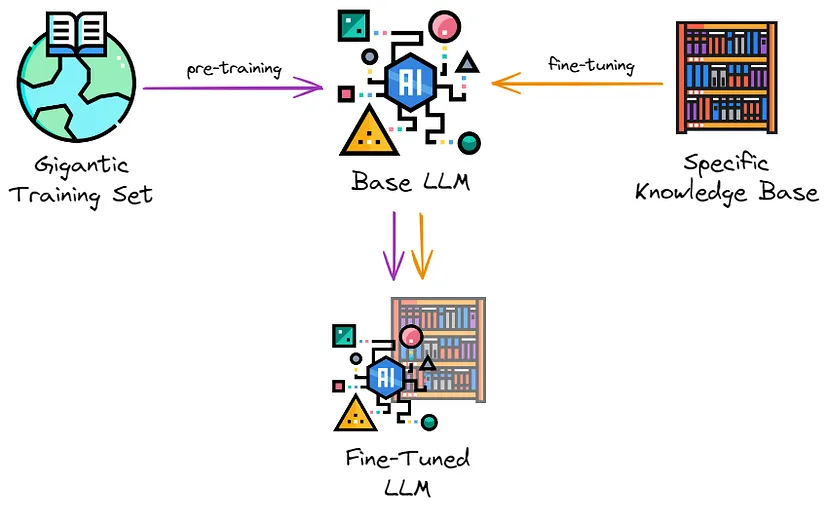
Что такое опенсорсные LLM
Поскольку создание языковой модели требует много ресурсов, этим занимаются только крупные корпорации.
Готовая LLM может распространяться по закрытой лицензии, т. е. платно, или иметь открытую лицензию — в этом случае воспользоваться моделью смогут все желающие. Это и есть опенсорсные модели LLM. Скачать их можно, например, с HuggingFace.
Обычно опенсорсные языковые модели обучены на небольшом количестве данных, поэтому они не такие «умные», как платные, но их можно дообучить на своих данных и донастроить для решения конкретных задач, например общения с клиентом или составления отчетов. В отличие от обучения с нуля, это не требует больших ресурсов, поэтому справиться с такой задачей могут даже небольшие стартапы.
Преимущества и недостатки опенсорсных LLM
Открытые модели LLM имеют множество преимуществ:
- доступность: их может скачать любой желающий без оплаты лицензии;
- гибкость: их легко адаптировать под свои нужды, изменить архитектуру и обучить на ваших данных;
- прозрачность: модель имеет открытый код, который можно доработать;
- большое сообщество: разработчики и инженеры активно делятся друг с другом опытом и совместно работают над улучшениями;
- независимость: модель не привязана к конкретной компании, что уменьшает риск потери доступа;
- конфиденциальность данных: LLM с открытым кодом можно развернуть на собственной инфраструктуре, не пересылая информацию на сторонние серверы.

Также у открытых LLM есть недостатки:
- качество работы: могут отвечать с ошибками, т. к. обучались на общих данных;
- отсутствие официальной поддержки: это может усложнить решение потенциальных проблем;
- необходимость доработки: внедрение и обслуживание требуют знаний и ресурсов, в отличие от закрытых LLM, которые сразу готовы к использованию;
- управление данными: пользователи должны самостоятельно заботиться о сборе, обработке и хранении данных для обучения;
- законность: использование опенсорсных LLM может вызывать вопросы о правомерности данных, на которых они были обучены, или предвзятости в работе;
- безопасность: открытый код может быть уязвим для злоумышленников, его могут использовать для создания вредоносных приложений или атак.
Помимо этого, опенсорсные LLM часто имеют те же проблемы, что и закрытые, например галлюцинации или ограничения длины контекстного окна.
Популярные модели LLM
Самые популярные опенсорсные модели сегодня:
- GPT-J: разработана EleutherAI. Считается более мощной и эффективной по сравнению со своим предшественником GPT-Neo. У нее шесть миллиардов параметров, и она очень производительна при обработке естественного языка. Модель обучали на большем объеме данных, поэтому она умеет генерировать качественный текст.
- BERT: модель от Google, которая стала основой для многих последующих моделей. Широко используется для классификации и анализа текста. Еще есть улучшенная версия RoBERTa от Facebook AI*, которая демонстрирует лучшие результаты на многих задачах.
- LLaMA: разработка от Meta*, предназначенная для обработки естественного языка. Включает несколько моделей с различным количеством параметров (от 7 до 65 миллиардов). Это позволяет пользователям выбирать модель в зависимости от их потребностей и вычислительных ресурсов.
- T5: еще одна языковая модель от Google, представленная в 2020 году. Использует единый фреймворк для всех задач NLP, включая перевод, суммирование, классификацию и генерацию текста. Каждая задача формулируется как преобразование одного текста в другой, что упрощает процесс обучения.
- Mistral: современная языковая модель, разработанная Mistral AI. Качественно обрабатывает текстовые данные и доступна в различных конфигурациях, включая модели с большим числом параметров. Обучена на разных источниках информации, поэтому генерирует разнообразные и качественные ответы.
- Yandex YaLM: языковая модель от Яндекса. Была представлена в 2023 году для обработки естественного языка. Модель обучена на русскоязычных и англоязычных источниках, что улучшает качество генерации текста. Доступна для пользователей в нескольких версиях, различающихся по количеству параметров.
Как выбрать LLM
Чтобы правильно выбрать опенсорсную LLM для вашей задачи:
1. Определите цель
Подумайте, для чего вам нужна языковая модель: генерировать текст, отвечать на вопросы, переводить тексты? Разные модели могут лучше подходить для разных задач.
Например, PT-Neo и GPT-J хорошо генерируют текст и выполняют задачи, связанные с обработкой естественного языка. Их можно использовать для чат-ботов и генерации контента. LLaMA предназначена для исследований, а BERT — для классификации, извлечения информации и ответов на вопросы.
2. Изучите документацию
Убедитесь, что у модели есть подробные инструкции по установке и использованию. Это поможет быстрее разобраться с ней.
3. Проверьте требования
Некоторые LLM требуют много вычислительных ресурсов. Убедитесь, что у вас есть необходимое оборудование и доступ к облачным сервисам, чтобы модель работала исправно.
4. Оцените сообщество и поддержку
Форум или группы поддержки могут быть полезными, если возникнут вопросы при настройке языковой модели.
5. Попробуйте модель
Многие опенсорсные модели можно протестировать на небольших задачах, прежде чем использовать их в полном объеме. Это поможет вам понять, подходит ли эта модель для вашего проекта.
6. Посмотрите лицензию
Убедитесь, что лицензия лингвистической модели позволяет использовать ее в вашем проекте. Некоторые могут иметь ограничения на коммерческое использование или модификацию.
Например, LLaMA можно использовать для исследований, но у нее есть ограничения на коммерческое использование и распространение. Некоторые реализации BERT также могут иметь ограничения в лицензии, особенно если были дообучены на специфических данных или в рамках коммерческих проектов.
Еще при выборе LLM можно использовать виртуальные тестовые арены — лидерборды, например Open LLM Leaderboard. Там языковые модели «сражаются» между собой. Их можно оценить по разным характеристикам — бенчмаркам — и выбрать подходящую.
Где применяют LLM
Сегодня языковые модели используют в самых разных сферах.
- IT: помогают автоматизировать рутинные задачи. Могут анализировать и обрабатывать большие объемы данных, составлять отчеты, генерировать код, что сокращает время и снижает вероятность ошибок.
- Образование: создают учебные материалы, тесты, задания и даже целые курсы. Это позволяет экономить время на подготовку и создавать персонализированные образовательные программы с учетом прогресса студентов.
- Бизнес: используются в службах поддержки клиентов. Могут обрабатывать запросы пользователей, предоставлять быстрые и точные ответы на вопросы. Это улучшает качество обслуживания и снижает нагрузку на сотрудников. Также языковые модели могут анализировать целевую аудиторию и создавать новый контент: рекламные материалы, статьи, посты для социальных сетей.
- Здравоохранение: используются для диагностических систем. Они анализируют истории болезни, результаты анализов и помогают врачам принимать более обоснованные решения.

Главное об опенсорсных LLM
- LLM — это большая языковая модель, обученная на большом количестве данных. Она умеет понимать и генерировать текст, отвечать на вопросы, поэтому используется в самых разных сферах — от IT до здравоохранения.
- Опенсорсные LLM — это модели, открытые для массового использования. Их можно скачивать и настраивать под свои задачи.
- Опенсорсные модели гибкие, доступные и независимые, но в то же время уязвимые и не имеют официальной поддержки.
- При выборе открытой LLM важно отталкиваться от задачи, которая перед вами стоит.
- Чтобы сравнить разные LLM, можно использовать специальные виртуальные арены — лидерборды.
*Meta — деятельность компании признана экстремистской в России.