

С помощью парсинга можно быстро и эффективно собирать информацию с веб-сайтов. В этой статье разберемся, как работает этот процесс, рассмотрим полезные библиотеки и инструменты и научимся парсить сайты на Python.
Что такое парсинг?

Парсинг (англ. parsing — разбор) — это процесс автоматического анализа веб-сайтов для сбора структурированной информации. Еще парсинг часто называют веб-скрапингом. Представьте, что вы ищете на новостном сайте статьи про Python и сохраняете каждую в заметки: копируете заголовок и ссылку. С помощью парсинга можно автоматизировать этот процесс. Все данные будет искать и сохранять скрипт, а вам останется только проверять файл с результатами.
Часто парсинг используют боты, которые потом предоставляют доступ к собранным структурированным данным. Это может быть список статей на сайте, вакансий на платформе по поиску работы или предложений на досках объявлений. Например, один из героев нашего блога написал бот, который нашел ему работу за месяц. Если у сайта нет полноценного открытого API, то парсер ищет данные с помощью GET-запросов к серверу, а это создает дополнительную нагрузку на сервер.
Это накладывает некоторые этические ограничения на скрипты для парсинга веб-сайтов:
- не стоит отправлять слишком много запросов к серверу, главная задача — собрать полезные данные, а не положить инфраструктуру сервиса;
- если есть публичное API, то лучше использовать его;
- на сайте могут быть личные данные пользователей, к ним надо относиться бережно и внимательно.
Надо быть готовым к тому, что некоторые владельцы веб-сайтов ограничивают парсинг и пытаются с ним бороться. В этих случаях приходится смириться с политикой сервиса или использовать более продвинутых ботов, которые имитируют поведение пользователя и получают доступ к странице через собственный экземпляр браузера. Этот способ сложнее, чем отправка запроса на сервер, но надежнее.
Для чего нужен парсинг?
С помощью парсинга можно быстро собрать сразу много данных, а не тратить время на ручное исследование веб-сайтов. В некоторых задачах именно время является ключевым фактором для перехода к автоматизации. Вот сферы, в которых обычно применяют веб-парсинг:
- Мониторинг цен. Можно быстро и эффективно отслеживать цены на один и тот же товар на разных площадках. Пользователям эта информация нужна для поиска самого выгодного предложения, а компаниям — для корректировки цен в своих магазинах.
- Отслеживание трендов. В социальных сетях постоянно меняются популярные темы. Надо проводить много времени в Сети, чтобы идти в ногу со временем или использовать автоматизированные системы сбора популярных постов.
- Новости. С помощью парсинга можно разработать собственный агрегатор новостей и настроить его только на интересные сайты и медиа.
- Исследования. Для глубокого анализа рынка или конкурентов нужны большие массивы данных. Ручной сбор займет много времени. Парсер выполнит задачу быстрее и точно ничего не пропустит.
Python и Beautiful Soup
Для парсинга удобно использовать Python из-за его простого синтаксиса и интерпретируемого подхода. Скрипты можно писать быстро и не собирать весь проект снова после незначительных изменений в коде. Разработанный парсер можно без проблем перенести практически на любую платформу или запустить в облаке, автоматизировав процесс хранения информации.
Еще одно преимущество Python — его популярность. Для языка программирования есть большое количество сторонних библиотек для различных задач и активное сообщество, которое может помочь советом. Одна из полезных библиотек для парсинга веб-сайтов — BeautifulSoup. С ее помощью можно легко анализировать HTML-файлы и находить в них нужные данные. В этой статье будем парсить сайт с ее помощью.
Как установить Beautiful Soup
Есть несколько популярных способов запуска кода на Python:
- На своем компьютере. Python работает на Windows, Linux и macOS. Для этого надо предварительно установить язык программирования на устройство. Сам код можно писать в редакторе или в полноценной IDE. Из бесплатных доступны Visual Studio Code и PyCharm Community. Плюсы этого способа заключаются в том, что все данные хранятся локально, а код выполняется быстрее.
- В облачном сервисе. Есть множество платформ, которые позволяют писать и запускать код на Python в облаке. Для этого на компьютер не надо устанавливать дополнительные пакеты и заботиться о совместимости. Понадобится только браузер и стабильное подключение к интернету. Все данные будут передаваться на удаленный сервер. Такой способ подходит для новичков или для быстрых экспериментов с кодом. Можно использовать бесплатные Repl.it, Google Colab или Programiz.
Для работы нам понадобятся библиотеки BeautifulSoup, requests и lxml. Их можно установить с помощью следующей команды в терминале:
$ pip3 install requests BeautifulSoup4 lxml

Получаем HTML-страницу
Для начала парсинга надо получить страницу, из которой будем вытаскивать полезные данные. Для этого будем использовать библиотеку requests, чтобы отправить GET-запрос, в качестве ответа получить код страницы и сохранить его. Попробуем распарсить вот эту статью, получив заголовок и первый абзац. Код выглядит следующим образом:
import requests url = 'https://blog.skillfactory.ru/programmist-v-sims-4/' response = requests.get(url) response.raise_for_status() print(response.text)
Что в коде:
- import requests — импортируем библиотеку requests в код скрипта;
- url = ‘https://blog.skillfactory.ru/programmist-v-sims-4/’ — переменная, в которой хранится ссылка на целевую страницу;
- response = requests.get(url) — выполняем GET-запрос и передаем в него переменную с хранящейся ссылкой;
- response.raise_for_status() — эта функция вернет нам код ошибки, если запрос не получится выполнить. Если не добавить эту строчку, то Python будет дальше выполнять код и не обращать внимания на ошибку;
- print(response.text) — печатаем код полученной страницы.
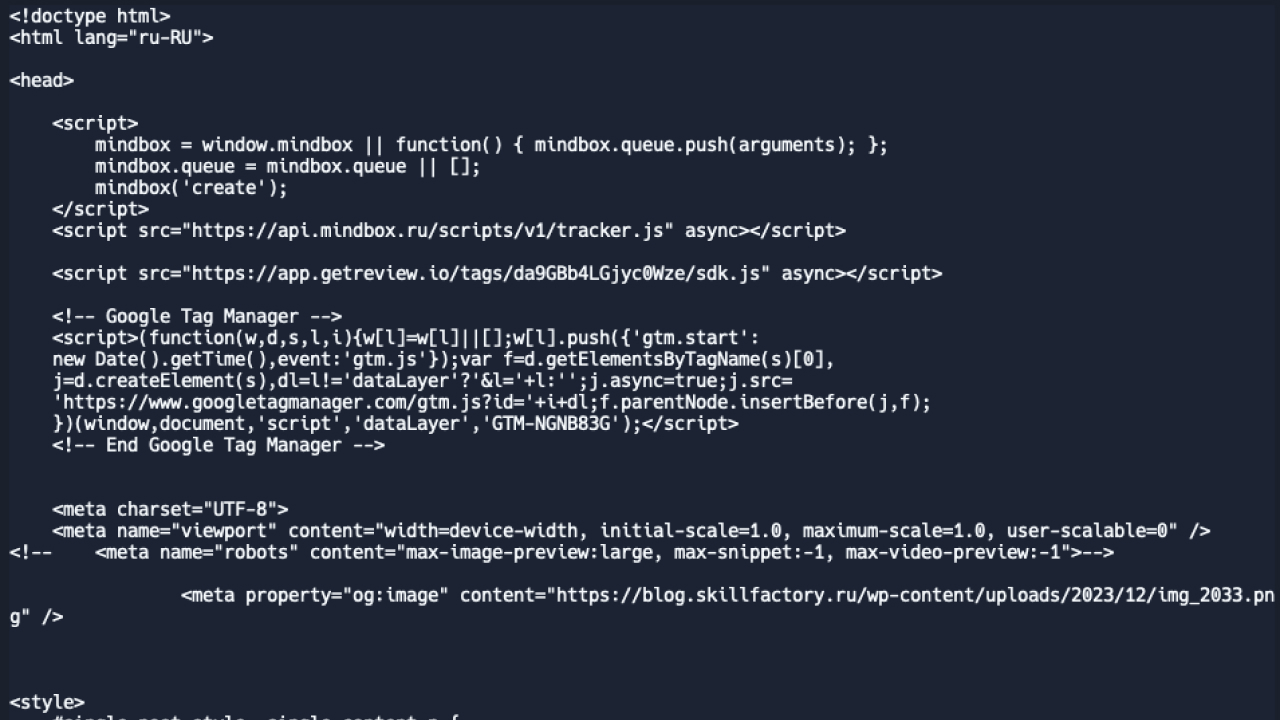
В ответе мы получим весь код страницы, включая CSS-стили и JavaScript. Вот так это выглядит:
Парсим страницу
Код страницы у нас уже есть, но теперь из него надо получить полезные данные. Обозначим, что для решения нашей задачи необходимо получить заголовок статьи и первый абзац. Для этого понадобятся возможности библиотеки BeautifulSoup. Но сперва надо найти теги элементов, которые будем извлекать из кода страницы.
Для этого потребуется веб-инспектор в любом браузере. Мы будем использовать Safari, но этот режим есть и в других браузерах. К примеру, в Google Chrome он открывается сочетанием клавиш Сtrl + Shift + I (Windows) или ⌥ + ⌘ + I (macOS). После этого можно выбрать на странице элемент и увидеть его код в инспекторе.
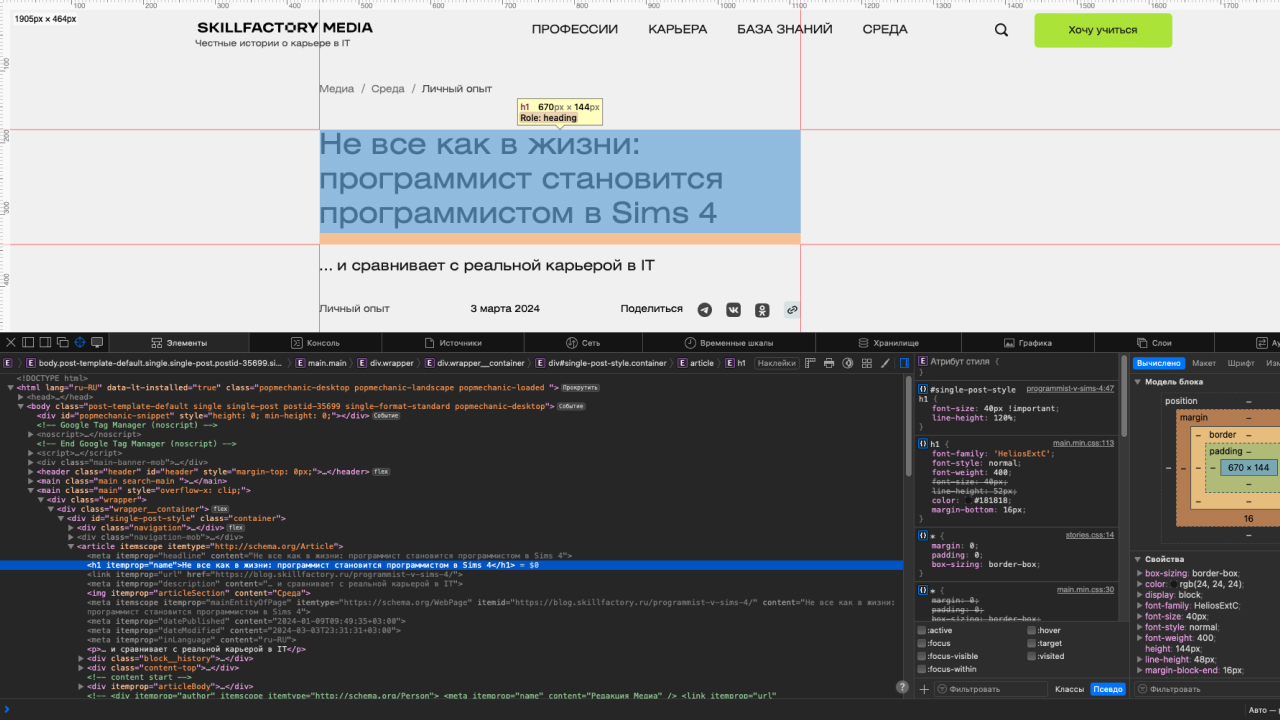
Заголовок статьи находится в теге <h1>, поэтому попробуем получить его содержимое с помощью библиотеки BeautifulSoup. Для этого передадим в функцию find искомый тег:
from bs4 import BeautifulSoup
import requests
url = 'https://blog.skillfactory.ru/programmist-v-sims-4/'
response = requests.get(url)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'lxml')
title = soup.find('h1')print(title)
>>> <h1 itemprop="name">Не все как в жизни: программист становится программистом в Sims 4</h1>
Все получилось и Python вывел в консоль текст заголовка, но с тегами. Надо избавиться от них. Это можно сделать с помощью преобразования содержимого переменной title в текст. После этого Python удалит теги, оставив только их содержимое:
soup = BeautifulSoup(response.text, 'lxml')
title = soup.find('h1')
title = title.text
print(title)
>>> Не все как в жизни: программист становится программистом в Sims 4
Теперь надо повторить весь порядок действий для вывода первого абзаца. Начинаем с поиска тега в инспекторе и после этого вытаскиваем его из файла и преобразуем в текст.
paragraph = soup.find('p')
paragraph = paragraph.text
print(paragraph)
>>> Честные истории о карьере в IT
Мы в точности повторили весь порядок действий, но парсер вывел совсем не ту строчку. Все дело в том, что мы искали элемент по тегу <p>. В HTML-файле их может быть несколько, а BeautifulSoup ищет самый первый. Поэтому запрос надо уточнить и сделать его более конкретным.
Для этого можно указать дерево наследования элементов. К примеру, если тег <p> входит в <article>, а тот — в <main>, то код запроса можно будет записать так: soup.find(‘main’).find(‘article’).find(‘p’). Еще можно искать элемент по его классу. Для этого в функцию надо передать тег и его класс: soup.find(‘p’, class_=’paragraph’).
В нашем случае запрос будет выглядеть следующим образом:
paragraph = soup.find('div', class_='single-content').find('p')
paragraph = paragraph.text
print(paragraph)
>>> Sims 4 — детальный симулятор жизни, в котором можно стать кем угодно. В игре приходится сталкиваться с трудностями, переживать неудачи и двигаться по карьерной лестнице. В этой статье попробуем с полного нуля стать программистом и развиваться как разработчик.
Таким образом можно распарсить любую веб-страницу и получить необходимые данные, а потом использовать их по своему усмотрению. К примеру, строить график изменения цен на товары в онлайн-магазинах или автоматически отправлять ссылки на новые статьи с кратким содержанием в Telegram.
Сохраняем результат
Сейчас наш код выводит результат парсинга веб-страницы в консоль. Эти данные никуда не сохраняются и к ним сложно получить доступ. Для этого каждый раз надо будет запускать скрипт. Упростим задачу и запишем данные в файл.
Для этого воспользуемся встроенной функцией write(). Сперва откроем файл в режиме записи:
file = open("parsing.txt", "w")
Если файла с таким названием нет, то Python сам создаст его в директории проекта.
После этого запишем данные, полученные во время парсинга, и обязательно закроем файл:
file.write(title) file.write(paragraph) file.close()
Коротко о том, как парсить сайты на Python
- С помощью парсинга можно автоматически анализировать веб-страницы и вытаскивать из них полезную информацию.
- Для парсинга необходимо отправлять запросы к серверу, чтобы получать код сайтов, а это может нагружать сервис, поэтому важно не злоупотреблять этим.
- Если у сервиса есть публичное API, то лучше пользоваться им.
- В Python удобно парсить веб-сайты с помощью библиотеки BeautifulSoup.
- Запросы выполняются с помощью библиотеки requests.
- Результат парсинга можно сохранять в файл, вносить в базу данных или отправлять с помощью почты и мессенджеров.
