

Создание выборки — важный этап машинного обучения. От того, как мы разделим данные, зависит производительность модели. В статье рассказываем, что такое тестовая, валидационная и обучающая выборки и как их использовать.

Что такое выборка данных
Обычная компьютерная программа работает благодаря алгоритмам — это четкая последовательность действий, которая дает предсказуемый результат. Если пользователь нажмет кнопку «Опубликовать», он точно знает, что произойдет дальше.
В машинном обучении компьютер действует как человек — он анализирует данные, ищет закономерности и после этого дает ответ. Благодаря этому можно находить сложные взаимосвязи и разрабатывать точные и эффективные модели.
Например, с помощью машинного обучения можно создать программу для распознавания лиц, считывать камерой номера машин, которые превысили скорость, или сделать прогноз по фондовому рынку.
Чтобы компьютер мог распознавать объекты и делать прогнозы, используются специальные массивы данных — выборки.
Какие бывают выборки
Чем больше данных есть для обучения, тем более эффективной и универсальной будет модель. Обычно всю информацию делят на три группы:
- Обучающая выборка — это данные, которые используют, чтобы обучить модель, настроить параметры и найти закономерности. Обучающая выборка должна быть достаточно большой и разнообразной, чтобы модель могла хорошо «научиться»;
- Валидационная выборка — это выборка для настройки гиперпараметров модели и предотвращения переобучения. Она помогает оценить, насколько хорошо модель будет работать на новых, невидимых данных, и провести сравнение между различными моделями и настройками;
- Тестовая выборка — это данные, которые используют для контроля и оценки производительности. В процессе обучения модель видит данные, поэтому может их запоминать и приспосабливаться. Чтобы этого не произошло и итоговая оценка была объективной, тестовая выборка должна оставаться невидимой. Результаты на тестовой выборке показывают, насколько хорошо модель будет работать в реальных условиях.
В итоге процесс работы с данными выглядит так: все данные делят на три группы. Сначала модель учится на обучающей выборке, потом происходят валидация и выбор лучшей модели, а в конце мы оцениваем производительность на тестовой выборке.
Пример разделения данных на выборки
Представим, что мы готовимся к экзамену по математике и у нас есть учебник с задачами. Тогда мы можем разделить все задачи на три группы:
- Обучающая выборка: берем первую половину задач, чтобы изучить темы, научиться применять формулы и решать уравнения;
- Валидационная выборка: берем несколько задач из второй половины и пробуем решить их, используя уже полученные знания. Это промежуточный тест, который помогает понять, насколько хорошо мы усвоили материал. Если задачи решены верно, мы на правильном пути. Если нет — возможно, стоит вернуться и повторить темы еще раз;
- Тестовая выборка: берем оставшиеся задачи, которые еще не решали, и устраиваем экзамен. Это финальный тест, который показывает, насколько хорошо мы подготовились.
Как разделить датасет на обучающую и тестовую выборки
Шаг 1. Сбор данных
Обычно для этого используют:
- базы данных: SQL, NoSQL;
- API: получение данных из внешних сервисов;
- файлы: CSV, Excel, JSON и др.;
- веб-скрапинг: извлечение с веб-страниц.
Шаг 2. Подготовка
Готовим данные к последующей работе:
- Проверяем файл на наличие повторяющихся записей и удаляем дубликаты.
- Обрабатываем пропуски, например удаляем строки и столбцы с пропущенными значениями или заполняем их медианными значениями.
- Исправляем ошибки: опечатки, неверные значения и аномалии.
- При необходимости преобразовываем данные в нужный формат.
Шаг 3. Определение размеров выборок
Обычно используют следующие пропорции:
- обучающая выборка: 60–80%;
- валидационная выборка: 10–20%;
- тестовая выборка: 10–20%.
Шаг 4. Разделение данных
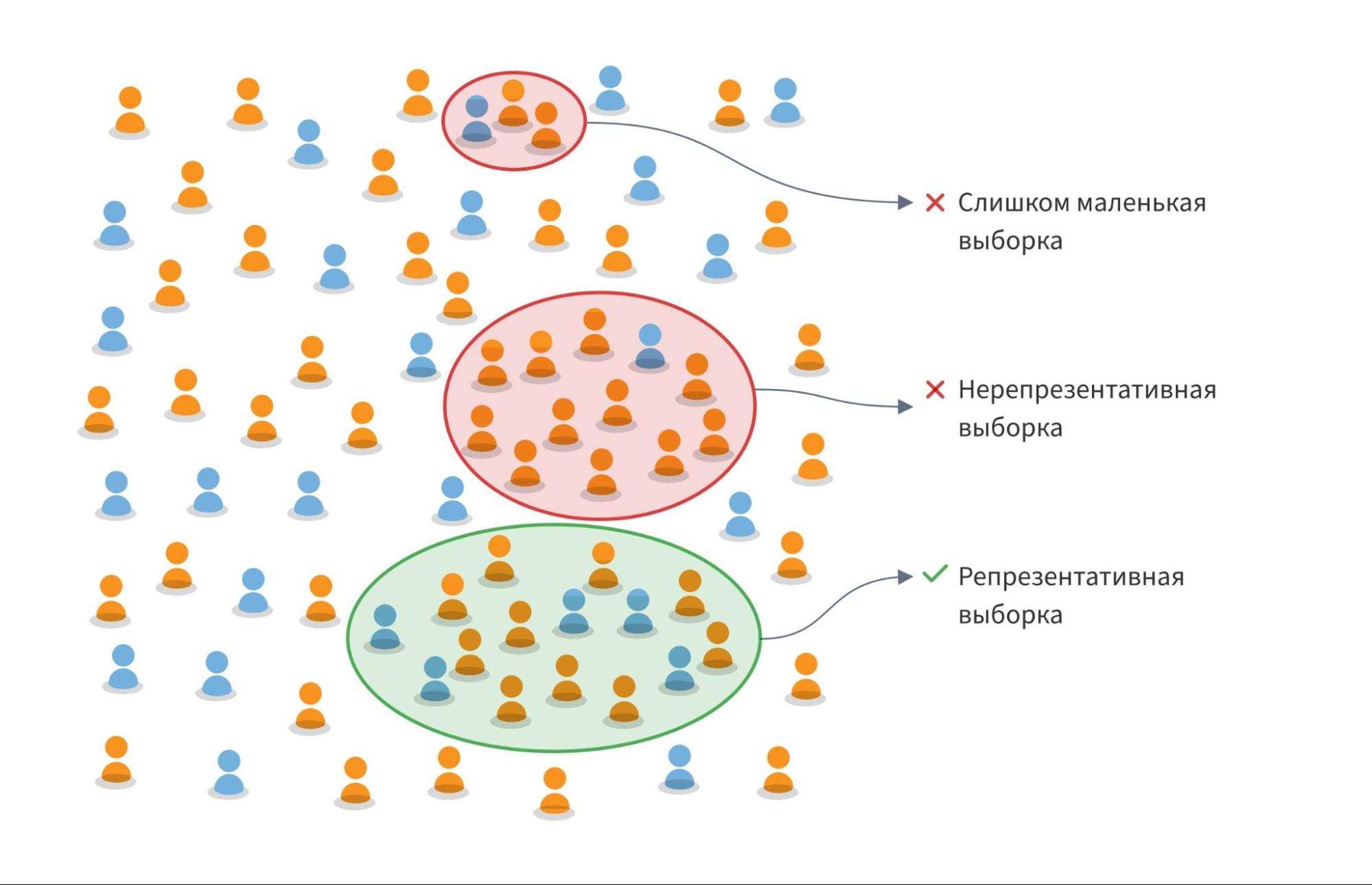
Разделить данные на группы можно случайно или с учетом их классов:
- Случайное разделение проводится с использованием функции случайной генерации. Этот метод позволяет быстро разделить даже большие наборы данных. Однако, если в наборе есть несбалансированные классы, данные могут быть распределены между выборками неравномерно. Иными словами, мы будем учиться на одной теме, а «писать контрольную» по другой;
- Стратифицированное разделение: перед случайным отбором данные делят на подгруппы по определенному признаку (например, тема задачи). Затем из каждой группы выбирают пропорциональное количество записей для обучающей (60%), валидационной (20%) и тестовой выборок (20%). Такой тип деления помогает сохранить сбалансированность классов.

Шаг 5. Проверка результатов
После деления нужно убедиться, что размеры выборок соответствуют ожиданиям и данные распределены равномерно.
Запросы на выборку данных Python
Для разделения данных можно использовать различные инструменты и библиотеки. Например, в Python это можно сделать с помощью:
- NumPy: предоставляет функции для генерации случайных чисел и выборок. Например, команда numpy.random.choice позволяет делать случайные выборки данных из массива.
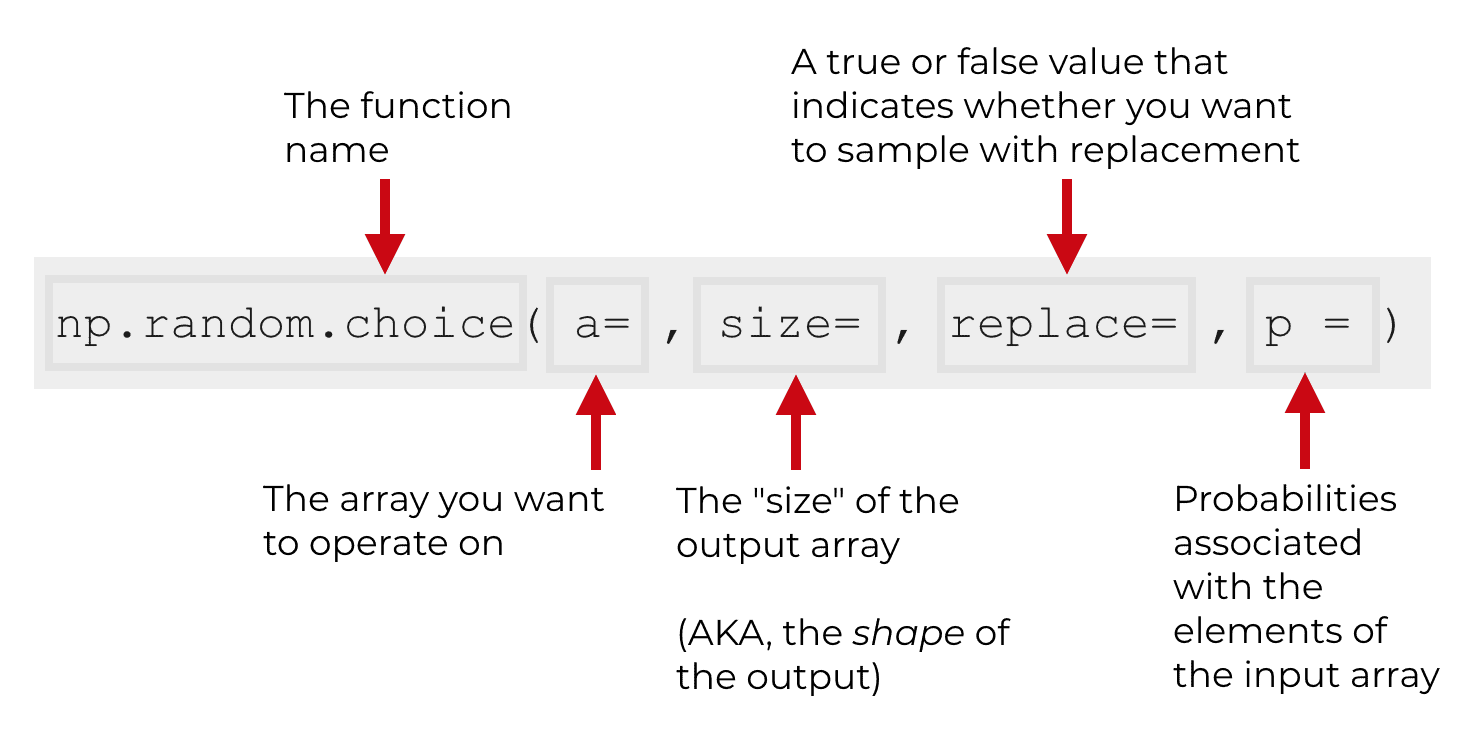
Генерация случайной выборки в NumPy. Источник
- Pandas: имеет встроенные функции для случайной выборки данных из DataFrame. Метод sample() позволяет выполнить как случайную, так и стратифицированную выборку.
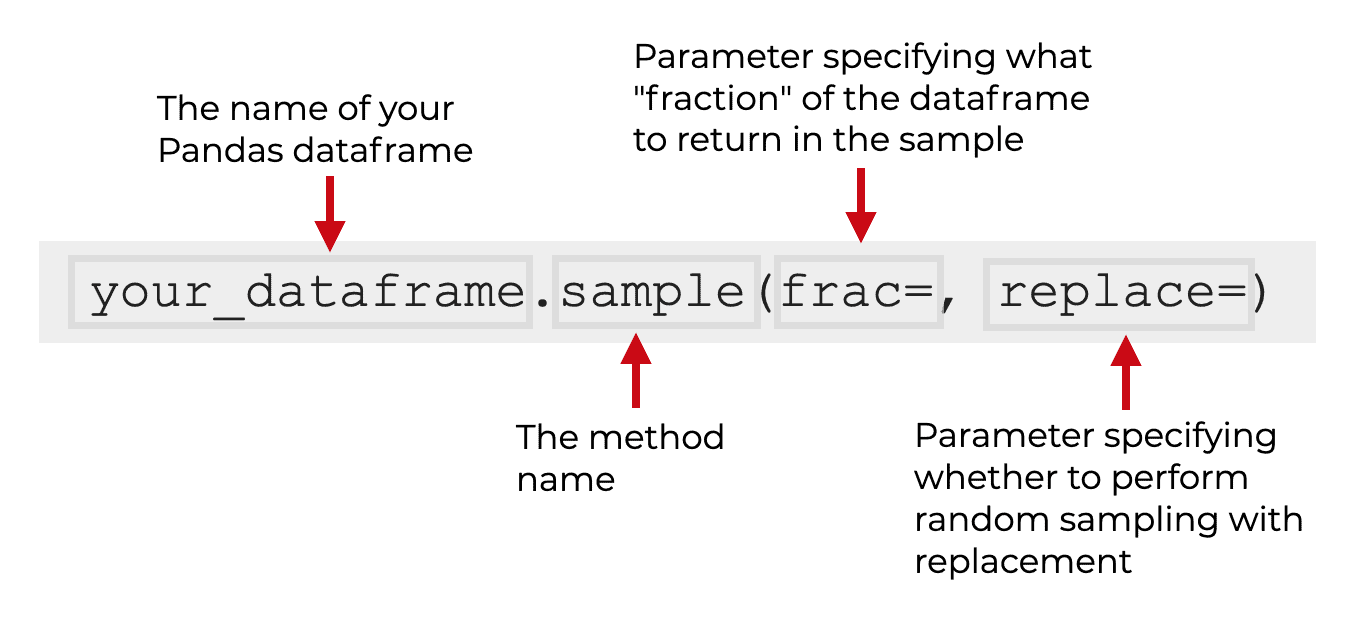
Метод sample(). Источник
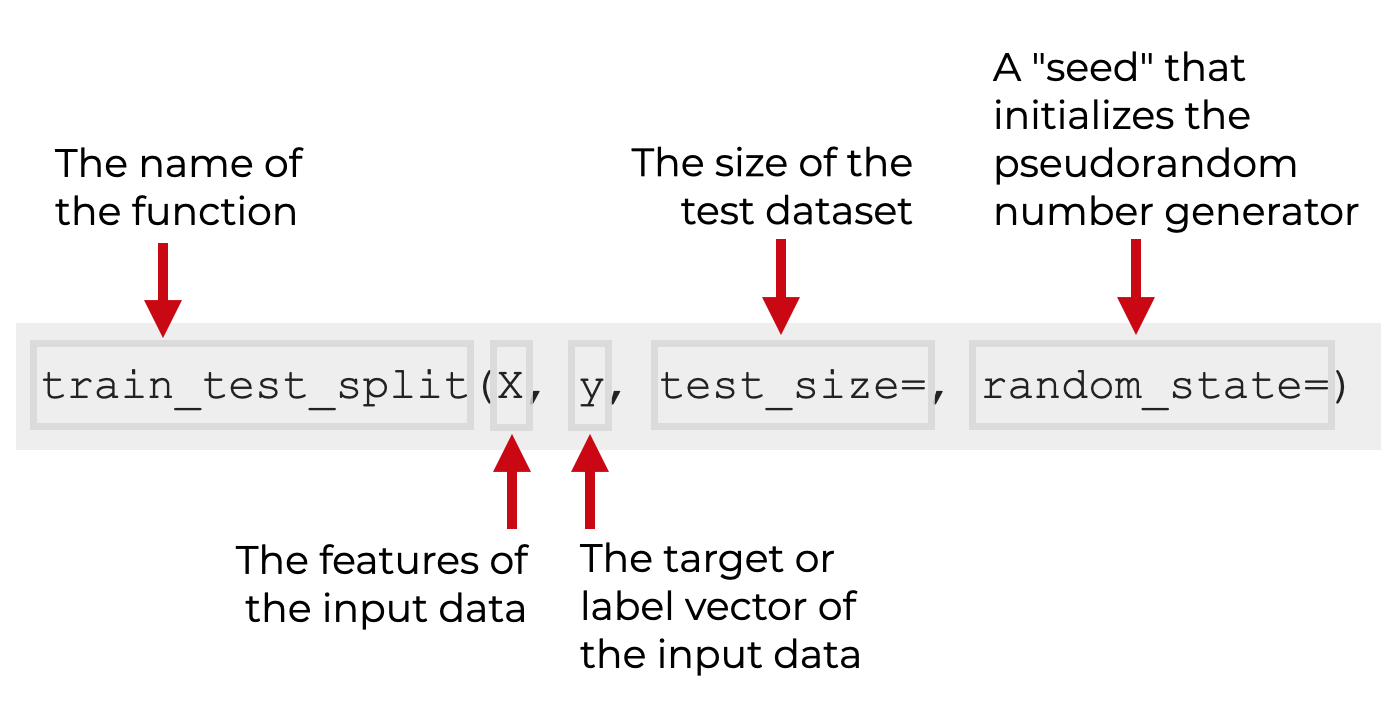
- Scikit-learn: готовит данные к машинному обучению. Функция train_test_split позволяет разбивать их на обучающую и тестовую выборки с учетом стратификации.
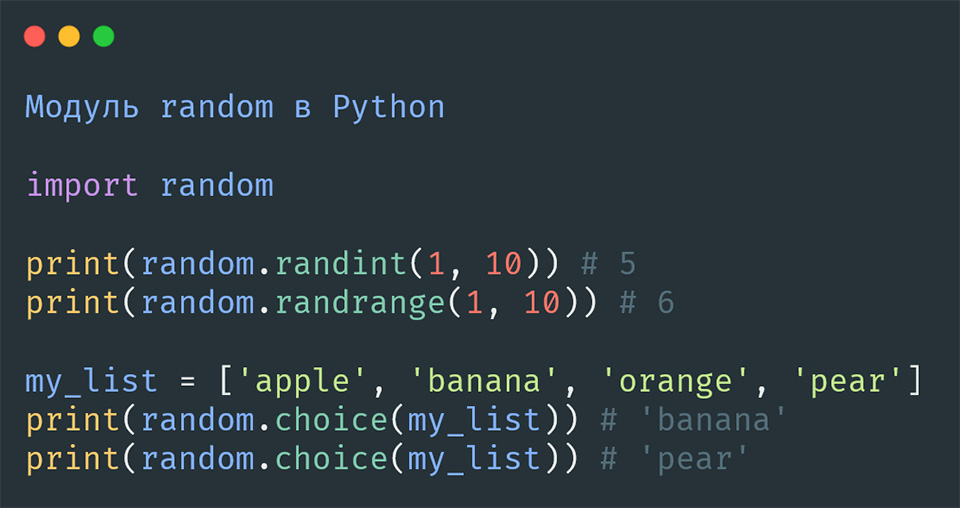
- Random: встроенный модуль Python для случайной выборки данных.
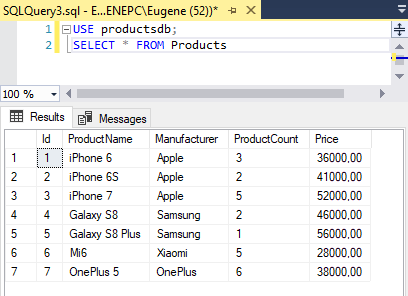
Запрос на выборку данных SQL
В языке SQL для выборки данных используется команда SELECT. С ее помощью можно извлечь информацию из таблиц для анализа или отчетности.
С помощью оператора SELECT можно выполнять разные типы выборок:
- выборка всех данных (используется символ *);
- выборка из конкретных столбцов.
Чтобы уточнить запрос и отфильтровать данные, можно использовать дополнительные операторы:
- WHERE фильтрует данные на основе заданных критериев. Например, из таблицы со списком сотрудников можно выбрать записи с определенной должностью.
SELECT * FROM employees WHERE position = 'Manager'
- ORDER BY сортирует результаты выборки по одному или нескольким столбцам. По умолчанию сортировка происходит в порядке возрастания (ASC), но можно указать и убывание (DESC).
SELECT * FROM employees ORDER BY name ASC
- GROUP BY используется для группировки строк с одинаковым содержанием в указанных столбцах.
SELECT position, COUNT(*) FROM employees GROUP BY position
Главное о выборках данных
- Выборки используются в машинном обучении для настройки модели и проверки ее производительности.
- Обучающая выборка самая большая, она используется для настройки параметров, валидационная — для промежуточного контроля, а тестовая — для итоговой оценки модели.
- Перед разделением на выборки данные нужно правильно подготовить: убрать дубликаты и пробелы, исправить ошибки.
- Данные можно разделить между выборками случайным образом или сделать стратифицированную выборку, которая учитывает соотношения классов.
- Для разделения данных можно использовать различные инструменты, например функцию test_ train_split в Scikit-learn.
