


Apache Hive — это система для работы с Big Data, которая выполняет SQL‑подобные запросы. Ее основная задача — упростить обработку и анализ неструктурированных данных, а также анализировать данные из внешних хранилищ.
Hive используют как надстройку над Hadoop и другими распределенными хранилищами. С его помощью можно формировать отчеты, выполнять запросы для анализа данных и подготавливать данные для дальнейшей обработки. У системы открытый исходный код, написанный преимущественно с помощью Java.
Зачем нужен Apache Hive
Apache Hive появился в Facebook* в середине 2000-х годов — тогда в компании накапливались огромные объемы логов и пользовательских данных, которые хранились в Hadoop. Проблема в том, что для анализа всех этих данных приходилось писать сложные задачи MapReduce, а без знаний Java и инженерной подготовки тут не обойтись.
Чтобы аналитики могли работать с данными самостоятельно, команда Facebook разработала Hive — инструмент, который позволял писать запросы с синтаксисом, похожим на SQL, и не программировать MapReduce вручную. Позже Hive был передан в Apache Software Foundation и стал частью экосистемы Hadoop.
Главное отличие Hive от классических СУБД вроде PostgreSQL заключается в том, что Hive ориентирован именно на Big Data и пакетную аналитику. Конечно, это влияет на скорость работы: миллисекундных ответов от Hive не добьешься, но это и не самое главное. В основном эту СУБД используют:
- для анализа логов и событий;
- построения витрин данных;
- финансовой аналитики;
- подготовки данных для машинного обучения.

Как хранятся данные в Apache Hive
В Apache Hive существует два основных типа таблиц:
- Внутренние (managed tables) — Hive управляет жизненным циклом данных. При удалении таблицы файлы тоже удаляются.
- Внешние (external tables) — Hive хранит только метаданные. Файлы остаются на месте даже после удаления таблицы.
Для оптимизации работы Hive поддерживает различные форматы файлов: TextFile, ORC, Parquet, Avro, но на практике чаще всего используют ORC и Parquet.
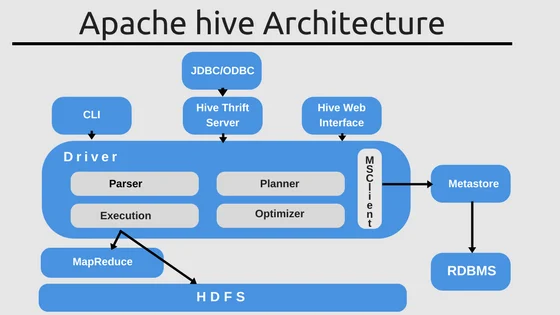
Архитектура Apache Hive
Hive взаимодействует со следующими компонентами:
- HDFS, Metastore и другими хранилищами;
- YARN (управляет ресурсами кластера);
- движками выполнения запросов (MapReduce, Tez, Spark).
Пользователь отправляет запрос на языке HiveQL, после чего Apache Hive оптимизирует его и преобразует в набор задач, которые передаются движку обработки данных. Раньше Hive работал только поверх MapReduce, но в современных версиях преимущественно используются более быстрые Tez и Spark.
Метаданные о таблицах, колонках и форматах хранения хранятся отдельно в Hive Metastore. Это обычная реляционная база данных вроде MySQL или PostgreSQL.
Разница SQL и HiveQL
Как мы уже сказали, Hive использует язык, похожий на SQL, — HiveQL. Там есть все привычные команды вроде SELECT, WHERE, GROUP BY, JOIN и далее по списку. Но несмотря на похожий синтаксис, логика работы HiveQL все же сильно отличается.
- Классический SQL нужен для работы с реляционными данными, которые хранятся внутри самой СУБД. Hive же обращается к данным из внешних хранилищ (например, из HDFS) и не управляет ими напрямую, а описывает их структуру и способы обработки.
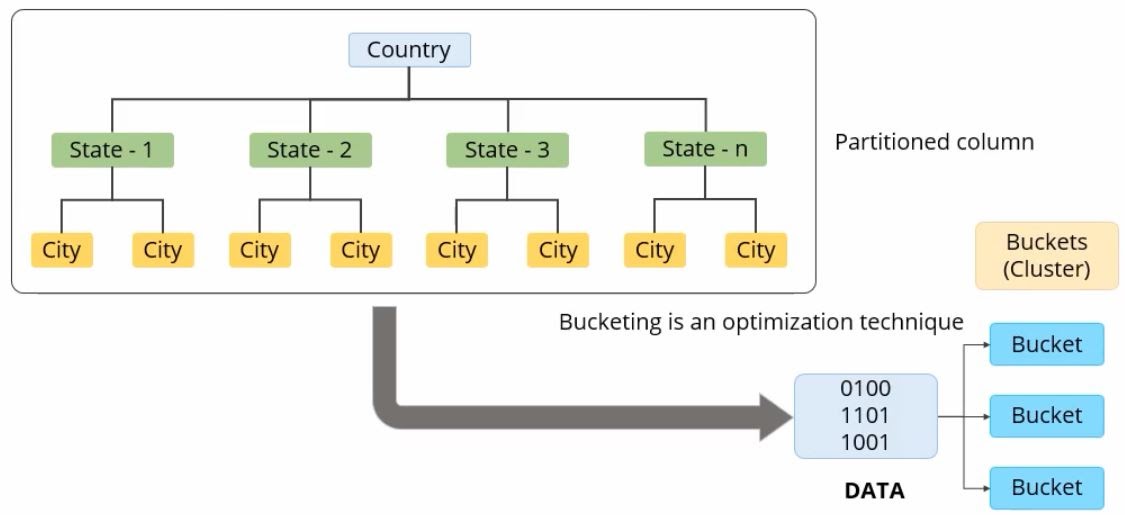
- Вместо индексов для ускорения в Hive используется партиционирование (предложение PARTITIONED BY), когда большие таблицы разбиваются на более мелкие единицы — партиции. Данные разбиваются по значениям одного или нескольких столбцов, например по дате или региону, и оказываются в разных папках в HDFS. Помимо этого, в Hive используется бакетирование, когда данные распределяются по фиксированному числу файлов (бакету) на основе хеш-функции от выбранного столбца.
- Помимо стандартных, HiveQL умеет обрабатывать сложные типы данных: массивы, словари (map), вложенные данные (struct) и объединения (union). Благодаря этому можно анализировать логи, JSON-файлы и сырые неструктурированные данные. SQL же годится, скорее, для старых добрых структурированных табличек.
- Другое важное различие — изменение данных. В SQL-базах их постоянно дополняют и удаляют. Hive же рассчитан на одноразовую загрузку данных, хотя формально команды UPDATE, DELETE и INSERT там есть.
- Наконец, Hive не предназначен для обработки данных в реальном времени. Он работает с уже сохраненными датасетами и запускает аналитические задачи пакетно. Для онлайн-аналитики подойдут другие инструменты вроде Kafka или Spark Streaming.
Когда использовать Hive, а когда — нет
Hive подходит, если:
- нужно анализировать терабайты данных;
- данные загружаются большими партиями;
- нужен инструмент для анализа полу- или неструктурированных данных;
- данные хранятся в Hadoop, S3 или другом распределенном хранилище;
- нужно строить витрины и выполнять сложные агрегации;
- данные загружаются большими партиями.
А вот когда Hive — не лучший выбор:
- Данных немного.
- Работа с короткими пользовательскими запросами. Ждать десятки секунд, пока выполнится запрос, — та еще мука, поэтому для приложений, банковских операций, заказов в интернет-магазине или биллинга лучше выбрать классические СУБД.
- Нужно часто обновлять отдельные строки (Hive для этого просто не предназначен).
- Нужна аналитика в реальном времени.
- Нет распределенной инфраструктуры. Вряд ли нужно разворачивать Hive ради небольшого проекта.
Как начать работать с Hive
Порог входа в Hive чаще всего лежит через уже освоенный SQL: несмотря на то, что HiveQL работает немного по-другому, основные команды языков все-таки совпадают. Не будет лишним базово ознакомиться с архитектурой и принципом работы Apache Hadoop: разобраться в том, зачем данные разбиваются на блоки и хранятся на разных узлах, почитать про файловую систему HDFS, фреймворки YARN и MapReduce (последний можно изучить очень базово, без углубления в Java).
Для старта достаточно развернуть Hive через локальный Hadoop в Docker или виртуальную машину. В учебных целях часто хватает минимальной конфигурации и Hive, работающего поверх одного узла.
Дальше стоит научиться подключаться к Hive и выполнять простые запросы через командную строку или веб-интерфейсы типа Hue. На этом этапе достаточно уметь создавать таблицы, указывать их структуру, выполнять базовые запросы для выборки и агрегации. После этого имеет смысл познакомиться с базовой оптимизацией: партицирование и бакетирование, пожалуй, одни из самых полезных и популярных фич в Hive.
И уже в самом конце можно переходить к более продвинутой работе со сложными типами данных (массивы, словари, вложенные структуры), объединению больших таблиц и подготовке данных для дальнейшей обработки — например, для Spark или машинного обучения.
Альтернативы Apache Hive
- Apache Spark — быстрый движок для обработки Big Data, который набирает скорость за счет вычислений в памяти. Подходит для SQL-аналитики, ETL, машинного обучения и стриминга.
- ClickHouse — колоночная аналитическая СУБД для быстрых агрегаций и работы с BI-дашбордами.
- Apache Flink — инструмент для потоковой обработки данных. С его помощью можно анализировать как статичные данные, так и датасеты, поступающие в реальном времени.
- Trino (Presto) — распределенный SQL-движок для интерактивной аналитики. Он не хранит данные, а выполняет запросы поверх разных источников (HDFS, S3, PostgreSQL и других).
- BigQuery, Snowflake, Amazon Redshift — облачные хранилища данных. Подойдут, если нужно избавиться от необходимости управлять Hadoop-инфраструктурой.
Apache Hive — коротко о главном
Apache Hive — СУБД для анализа больших данных, которая работает с распределенными хранилищами через SQL‑подобный интерфейс. Благодаря Hive аналитики и разработчики могут работать с данными без необходимости создавать сложные задания MapReduce.
Hive не используют для задач, где данные нужно часто обновлять или где нужно получать результаты молниеносно. По сравнению с классическими СУБД, Hive работает намного медленнее, зато эта система позволяет работать с большими и неструктурированными данными.
* Принадлежит компании Meta, деятельность которой признана экстремистской в России.
