
Apache Hadoop — это пакет утилит, библиотек и фреймворков, его используют для построения систем, которые работают с Big Data. Он хранит и обрабатывает данные для выгрузки в другие сервисы. У Hadoop открытый исходный код, написанный на языке Java. Это значит, что пользователи могут работать с ним и модифицировать его бесплатно.

Hadoop разделен на кластеры — группу серверов (узлов), которые используют как единый ресурс. Так данные удобнее и быстрее собирать и обрабатывать. Деление позволяет выполнять множество элементарных заданий на разных серверах кластера и выдавать конечный результат. Это нужно в первую очередь для перегруженных сайтов, например Facebook*.
Внутри Hadoop существует несколько проектов, которые превратились в отдельные стартапы: Cloudera, MapR и Hortonworks. Эти проекты — дистрибутивы или установочный пакет программы, которые обрабатывают большие данные.

Как появился Hadoop
Hadoop появилась благодаря усилиям Дуга Каттинга, который начал разрабатывать инфраструктуру для распределенных вычислений в 2005 году. Начальные шаги были предприняты в проекте Nutch, поисковой машине на Java, которая работала на основе концепции вычислений MapReduce. Эта концепция затем стала основой для Hadoop.
В 2006 году компания Yahoo предложила Дугу Каттингу возглавить специальную команду для разработки инфраструктуры распределенных вычислений. Именно тогда проект получил название Hadoop в честь игрушечного слоника, принадлежавшего сыну Каттинга.
В 2008 году на основе Hadoop была запущена поисковая машина Yahoo. Это стало важным моментом, и проект начал получать большее внимание. Крупные компании, такие как Facebook*, Last.fm, The New York Times, также начали проявлять интерес к нему. Это было спровоцировано рекордом производительности, установленным Hadoop в стандартизированном бенчмарке сортировки данных — 1 терабайт данных был обработан за 209 секунд на кластере из 910 узлов.
С того момента Hadoop продолжила свое развитие. Появлялись новые модули и технологии, расширяя функциональность и повышая скорость обработки данных. Со временем сторонние разработчики также начали вносить свой вклад в развитие проекта. Это привело к появлению современной экосистемы Hadoop, которая включает десятки инструментов и подходов для управления и обработки данных.
Архитектура Hadoop
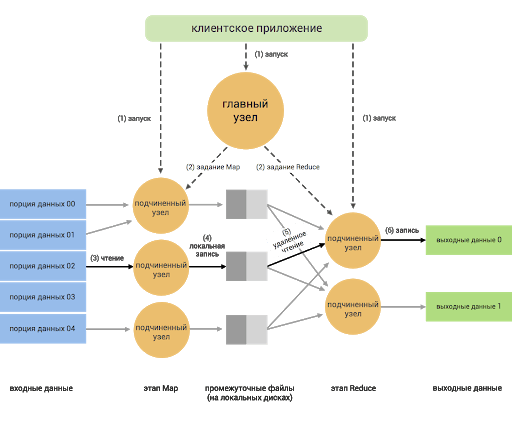
Основные компоненты
Hadoop разделен на четыре модуля: такое деление позволяет эффективно справляться с задачами для анализа больших данных: HDFS, YARN, MapReduce и Common. В дополнение к ним имеется ряд десятков инструментов, которые призваны расширить возможности платформы. Дополнительную информацию о них можно найти в официальной документации данной платформы.
Hadoop Common — набор библиотек, сценариев и утилит для создания инфраструктуры, аналог командной строки.
Ниже представлены несколько инструментов:
- Общая конфигурация (Common Configuration) предоставляет возможность настройки Hadoop-приложений через файлы формата XML.
- Общий ввод-вывод (Common IO) обеспечивает взаимодействие с различными файловыми системами, такими как HDFS и Amazon S3.
- Общая безопасность (Common Security) включает в себя утилиты, связанные с обеспечением безопасности, такие как системы аутентификации и авторизации.
Hadoop HDFS (Hadoop Distributed File System) — иерархическая система хранения файлов большого размера с возможностью потокового доступа. Это значит, что HDFS позволяет легко находить и дублировать данные.
HDFS состоит из NameNode и DataNode — управляющего узла и сервера данных. NameNode отвечает за открытие и закрытие файлов и управляет доступом к каталогам и блокам файлов. DataNode — это стандартный сервер, на котором хранятся данные. Он отвечает за запись и чтение данных и выполняет команды NameNode. Отдельный компонент — это client (пользователь), которому предоставляют доступ к файловой системе.
MapReduce — это модель программирования, которая впервые была использована Google для индексации своих поисковых операций. MapReduce построен по принципу «мастер–подчиненные». Главный в системе — сервер JobTracker, раздающий задания подчиненным узлам кластера и контролирующий их выполнение. Функция Map группирует, сортирует и фильтрует несколько наборов данных. Reduce агрегирует данные для получения желаемого результата.
YARN решает, что должно происходить в каждом узле данных. Центральный узел, который управляет всеми запросами на обработку, называется диспетчером ресурсов. Менеджер ресурсов взаимодействует с менеджерами узлов: каждый подчиненный узел данных имеет свой собственный диспетчер узлов для выполнения задач.
Дополнительные компоненты
Hive: хранилище данных
Система хранения данных, которая помогает запрашивать большие наборы данных в HDFS. До Hive разработчики сталкивались с проблемой создания сложных заданий MapReduce для запроса данных Hadoop. Hive использует HQL (язык запросов Hive), который напоминает синтаксис SQL.
Pig: сценарий преобразований данных
Pig преобразовывает входные данные, чтобы получить выходные данные. Pig полезен на этапе подготовки данных, поскольку он может легко выполнять сложные запросы и хорошо работает с различными форматами данных.

Flume: прием больших данных
Flume — это инструмент для приема больших данных, который действует как курьерская служба между несколькими источниками данных и HDFS. Он собирает, объединяет и отправляет огромные объемы потоковых данных (например файлов журналов, событий, созданных десктопными версиями социальных сетей) в HDFS.
Zookeeper: координатор
Zookeeper это сервис-координатор и администратор Hadoop, который распределяет информацию на разные сервера.
HBase: СУБД
HBase представляет собой систему управления базами данных NoSQL, функционирующую поверх инфраструктуры Hadoop и обеспечивающую оперативный доступ к обширным объемам данных в режиме реального времени для операций чтения и записи.
Spark MLlib: библиотека
Spark MLlib представляет собой библиотеку машинного обучения, разработанную для Apache Spark, которая предоставляет масштабируемые алгоритмы для решения задач машинного обучения.
Oozie: платформа
Oozie представляет собой платформу для планирования рабочих процессов, созданную для управления задачами в среде Hadoop.
Как работает Hadoop
Hadoop использует модель обработки данных MapReduce, которая позволяет эффективно обрабатывать большие объемы информации на распределенных кластерах компьютеров. Процесс работы можно разбить на следующие этапы:
- Map: На этом этапе данные разбиваются на блоки и распределяются по рабочим узлам кластера. Каждый узел применяет функцию Map к своим данным, выполняя предварительную обработку, такую как фильтрация, сортировка и анализ. Функция Map генерирует промежуточные пары ключ-значение, которые сохраняются во временном хранилище.
- Shuffle and Sort (Перераспределение и сортировка): На этом этапе промежуточные данные собираются и перераспределяются таким образом, чтобы все данные с одинаковым ключом оказались на одном узле. Затем данные сортируются по ключам.
- Reduce: На этом этапе данные передаются функции Reduce, которая обрабатывает данные с одинаковыми ключами, объединяя и агрегируя их. Результаты обработки сохраняются в окончательный набор данных.
Суть работы Hadoop заключается в параллельной обработке данных на множестве рабочих узлов в кластере. Каждый узел выполняет функции Map и Reduce над своей порцией данных, после чего результаты собираются и объединяются для получения итоговых результатов. Это позволяет обрабатывать большие объемы данных эффективно, так как задача разделяется на более мелкие подзадачи, которые выполняются параллельно.
Для чего используют Hadoop
Hadoop используется для разнообразных задач связанных с обработкой и анализом больших объёмов данных. Примеры применения в различных отраслях включают:
- Ретейл (розничная торговля): В розничной сфере Hadoop применяется для оптимизации уровня складских запасов, улучшения прогнозирования спроса и сокращения времени обработки заказов.
- Финансы: Банки и финансовые компании используют Hadoop для анализа и моделирования финансовых рисков, а также управления клиентскими портфелями.
- Здравоохранение: В медицинской сфере применяется для обработки данных о пациентах, анализа распространения заболеваний, обнаружения мошенничества с медицинскими страховками и других задач.
- Наука: В научных исследованиях Hadoop используется для анализа больших объёмов данных в разных областях, таких как геномика (исследование генетических данных), астрономия (анализ данных с телескопов), социология (анализ данных социальных сетей) и климатология (обработка климатических данных).
Также решает несколько ключевых задач по работе с большими данными:
- Обеспечивает устойчивость. Данные, хранящиеся в любом узле, воспроизводятся в других узлах кластера. Это помогает избежать поломок. Если что-то случилось с одним из узлов, то всегда есть резервная копия данных, доступная в кластере.
- Повышает скорость обработки данных. Файловая система Hadoop, параллельная обработка и модель MapReduce обеспечивают запуск сложных запросов в считанные секунды.
- Обрабатывает разнообразные данные. HDFS имеет возможность хранить различные форматы данных, такие как неструктурированные (например видео), полуструктурированные (например файлы XML). Работа с разными форматами расширяет спектр возможностей программиста.
В целом, Hadoop обеспечивает эффективное хранение и обработку данных в больших масштабах, что позволяет решать сложные задачи анализа и получать ценные инсайты из разнообразных областей.
Преимущества
Основные достоинства Hadoop:
Масштабируемость: обладает уникальной способностью масштабироваться с меньших кластеров до огромных систем с тысячами узлов. Пользователи могут легко расширять кластер, добавляя новые узлы, что позволяет обеспечивать эффективную обработку даже огромных объемов данных.
Универсальность: Экосистема Hadoop способна работать с разнообразными типами данных — от структурированных до неструктурированных. Она поддерживает множество форматов данных, что позволяет хранить и анализировать данные разного рода, собранные из различных источников.
Экономичность: Hadoop основан на общедоступном оборудовании, и это делает его экономически выгодным в сравнении с традиционными методами обработки больших данных. Он способен работать на обычных серверах, не требуя дорогостоящего специализированного оборудования.
Отказоустойчивость: Один из ключевых аспектов Hadoop — его способность к автоматическому восстановлению после сбоев. Приложения и обработка данных защищены благодаря автоматическому перераспределению задач на рабочие узлы в случае выхода из строя одного из них. Это обеспечивает надежность и устойчивость работы системы.
Недостатки
Несмотря на свои многочисленные преимущества, Hadoop также обладает определенными недостатками:
- Сложность настройки и управления: Разворачивание и настройка Hadoop-кластера может быть сложной задачей для неподготовленных специалистов. Это требует опыта в администрировании, а также знаний о конфигурации и настройке различных компонентов.
- Сложность программирования: Написание задач на MapReduce или других компонентах требует понимания и работы с Java или другими языками программирования. Это может быть вызовом для специалистов, не знакомых с программированием.
- Латентность и производительность: В силу своей архитектуры, Hadoop может иметь высокую латентность (задержку) при обработке данных. Это делает его менее подходящим для задач, требующих низкой задержки, например, интерактивных запросов.
- Неэффективность для небольших данных: Hadoop предназначен для работы с большими объемами данных. Для небольших объемов данных использование может быть неэффективным из-за накладных расходов на разделение, обработку и сбор данных.
- Сложности с безопасностью: Первоначальные версии Hadoop имели ограниченные механизмы безопасности. Несмотря на улучшения в этой области, настройка безопасности в Hadoop-кластере остается сложной задачей.
- Сложность обработки структурированных данных: Hadoop был разработан прежде всего для работы с полуструктурированными и неструктурированными данными. Обработка структурированных данных может потребовать дополнительных усилий и инструментов.
- Ограниченная поддержка для реального времени: Возможности Hadoop в обработке данных в режиме реального времени ограничены. Для задач, требующих мгновенной реакции, может потребоваться интеграция с другими технологиями.
В целом, хотя Hadoop предоставляет мощные средства обработки больших данных, его использование требует внимательной оценки и учета вышеперечисленных недостатков в зависимости от конкретных потребностей и сценариев использования.
* Принадлежит компании Meta, деятельность которой признана экстремистской в России.

0 комментариев