
Почему все вокруг говорят про большие данные? Какие именно данные считаются большими? Где их искать, зачем они нужны, как на них заработать? Объясняем простыми словами, что такое «Биг Дата», вместе с экспертом Skillfactory — ведущим автором курса по машинному обучению, старшим аналитиком в «КиноПоиске» Александром Кондрашкиным.

Что такое большие данные?

Big Data («Биг Дата», большие данные) — огромные наборы разнообразных данных. Огромные, потому что их объемы такие, что простой компьютер не справится с их обработкой, а разнообразные — потому что эти данные разного формата, неструктурированные и содержат ошибки. Большие данные быстро накапливаются и используются для разных целей.
Big Data — это не обычная база данных, даже если она очень большая. Вот отличия:
Объем информации в мире увеличивается ежесекундно, и то, что считали большими данными десятилетие назад, теперь умещается на жесткий диск домашнего компьютера.

60 лет назад жесткий диск на 5 мегабайт был в два раза больше холодильника и весил около тонны. Современный жесткий диск в любом компьютере вмещает до полутора десятков терабайт (1 терабайт равен 1 млн мегабайт) и по размерам меньше обычной книги.
В 2021 году большие данные измеряют в петабайтах. Один петабайт равен миллиону гигабайт. Трехчасовой фильм в формате 4K «весит» 60‒90 гигабайт, а весь YouTube — 5 петабайт или 67 тысяч таких фильмов. 1 млн петабайт — это 1 зеттабайт.
Пройдите наш тест и узнайте, какой вы Data Scientist. Ссылка в конце статьи.
Как работает технология Big Data?
Источники сбора больших данных делятся на три типа:
- социальные;
- машинные;
- транзакционные.
Все, что человек делает в сети, — источник социальных больших данных. Каждую секунду пользователи загружают в Инстаграм* 1 тыс. фото и отправляют более 3 млн электронных писем. Ежесекундный личный вклад каждого человека — в среднем 1,7 мегабайта.
Другие примеры социальных источников Big Data — статистики стран и городов, данные о перемещениях людей, регистрации смертей и рождений и медицинские записи.
Большие данные также генерируются машинами, датчиками и «интернетом вещей». Информацию получают от смартфонов, умных колонок, лампочек и систем умного дома, видеокамер на улицах, метеоспутников.
Транзакционные данные возникают при покупках, переводах денег, поставках товаров и операциях с банкоматами.
Как обрабатывают большие данные?
Массивы Big Data настолько большие, что простой Excel с ними не справится. Поэтому для работы с ними используют специальное ПО.
Его называют «горизонтально масштабируемым», потому что оно распределяет задачи между несколькими компьютерами, одновременно обрабатывающими информацию. Чем больше машин задействовано в работе, тем выше производительность процесса.
Такое ПО основано на MapReduce, модели параллельных вычислений. Модель работает так:
- сначала данные фильтруются по условиям, которые задает исследователь, сортируются и распределяются между отдельными компьютерами (узлами);
- затем узлы параллельно рассчитывают свои блоки данных и передают результат вычислений на следующую итерацию.
MapReduce — не конкретная программа, а скорее алгоритм, с помощью которого можно решить большинство задач обработки больших данных.
Примеры ПО, которое основывается на MapReduce:
- Hadoop — набор программ с открытым исходным кодом для хранения файлов, планирования и совместной работы с данными. Система разработана так, чтобы при сбое на одном узле нагрузка сразу перераспределялась на другие, не прерывая вычисления.
- Apache Spark — набор библиотек, которые позволяют выполнять вычисления в оперативной памяти и многократно обращаться к результатам расчетов. Его применяют для решения широкого круга задач, от простой обработки и фильтрации данных до машинного обучения.
Специалисты по большим данным используют оба инструмента: Hadoop для создания инфраструктуры данных и Spark для обработки потоковой информации в реальном времени.
Читайте также: Отзыв о профессии Data Scientist, рассказ о карьерном пути и советы для новичков
Где применяется аналитика больших данных?
Большие данные нужны в маркетинге, перевозках, автомобилестроении, здравоохранении, науке, сельском хозяйстве и других сферах, в которых можно собрать и обработать нужные массивы информации.
Бизнесу большие данные нужны, чтобы:
- Оптимизировать процессы — например, крупные банки используют большие данные, чтобы обучать чат-бота — программу, которая заменит живого сотрудника по простым вопросам и при необходимости переключит на специалиста.
- Делать прогнозы — анализируя большие данные о продажах, компании могут предсказать поведение клиентов и покупательский спрос на товары в зависимости от времени года или ситуации в мире.
- Строить модели — с помощью анализа данных о прибыли и издержках компания может построить модель для прогнозирования выручки.
Анализ больших данных позволяет бизнесу не только систематизировать информацию, но и находить неочевидные причинно-следственные связи.

Продажи товаров
Онлайн-маркетплейс Amazon запустил решение для рекомендаций товаров, работающую на машинном обучении. Она учитывает не только поведение и предыдущие покупки пользователя, но и время года, ближайшие праздники и остальные факторы, важные для бизнеса. После того как эта система заработала, рекомендации начали генерировать 35% всех продаж сервиса.
В супермаркетах «Лента» с помощью больших данных анализируют информацию о покупках и предлагают персонализированные скидки на товары. К примеру, говорят в компании, система по данным о покупках может понять, что клиент изменил подход к питанию, и начнет предлагать ему подходящие продукты.
Американская сеть Kroger использует большие данные для персонализации скидочных купонов, которые получают покупатели по электронной почте. После того как их сделали индивидуальными, подходящими конкретным покупателям, доля покупок только по ним выросла с 3,7 до 70%.
Читайте также: Чем занимается дата-инженер в X5 retail Group?
Найм сотрудников
Крупные компании, в том числе российские, стали прибегать к помощи роботов-рекрутеров, чтобы на начальном этапе поиска сотрудника отсеять тех, кто не заинтересован в вакансии или не подходит под нее. Так, компания Stafory разработала робота Веру, которая сортирует резюме, делает первичный обзвон и выделяет заинтересованных кандидатов. PepsiCo заполнила 10% нужных вакансий только с помощью робота.
Банки
Обработка больших данных помогает защищать клиентов от мошенников. Именно с помощью этих технологий обнаруживают аномалии в поведении пользователя, нетипичные для него покупки или переводы. Уже в 2017 году Visa с помощью анализа данных ежегодно предотвращала мошенничества на $2 млрд.
Автомобилестроение
В 2020 году у автоконцерна Toyota возникла проблема: нужно было понять причину большого числа аварий по вине водителей, перепутавших педали газа и тормоза. Компания собрала данные со своих автомобилей, подключенных к интернету, и на их основе определила, как именно люди нажимают на педали.
Оказалось, что сила и скорость давления различаются в зависимости от того, хочет человек затормозить или ускориться. Теперь компания разрабатывает новый сервис, который будет определять манеру давления на педали во время движения и сбросит скорость автомобиля, если водитель давит на педаль газа, но делает это так, будто хочет затормозить.
Медицина
Американские ученые научились с помощью больших данных определять, как распространяется депрессия. Исследователь Мунмун Де Чаудхури и ее коллеги загрузили в прогностическую модель сообщения из Twitter, Фейсбук* с геометками. Сообщения отбирали по словам, которые могут указывать на депрессивное и подавленное состояние. Расчеты совпали с официальными данными.
Госструктуры
Большие данные просто необходимы госструктурам. С их помощью ведется не только статистика, но и слежка за гражданами. Подобные технологии используют во многих странах: известен новый сервис PRISM, которыми пользуются ФБР и ЦРУ для сбора персональных данных из соцсетей и продуктов Microsoft, Google и Apple. В России информацию о пользователях и телефонных звонках собирает решение СОРМ.
Маркетинг
Работа с большими данными нужна и в этой сфере. Социальные большие данные помогают группировать пользователей по интересам и персонализировать для них рекламу. Людей ранжируют по возрасту, полу, интересам и месту проживания. Те, кто живут в одном регионе, бывают в одних и тех же местах, смотрят видео и читают статьи на похожие темы, скорее всего, заинтересуются одними и теми же товарами.
При этом регулярно происходят скандалы, связанные с использованием больших данных в маркетинге. Так, в 2018 году стриминговую платформу Netflix обвинили в расизме из-за того, что она показывает пользователям разные постеры фильмов и сериалов в зависимости от их пола и национальности.
Читайте также: Чем занимается дата-сайентист в «ИТ Магнит»?
Медиа
С помощью анализа больших данных в медиа измеряют аудиторию. В этом случае Big Data может даже повлиять на политику редакции. Так, издание Huffington Post использует решение, которое в режиме реального времени показывает статистику посещений, комментариев и других действий пользователей, а также готовит аналитические отчеты.
Новый сервис в Huffington Post оценивает, насколько эффективно заголовки привлекают внимание читателя, разрабатывает методы доставки контента определенным категориям пользователей. Например, выяснилось, что родители чаще читают статьи со смартфона и поздно вечером в будни, после того как уложили детей спать, а по выходным они обычно заняты, — в итоге контент для родителей публикуется на сайте в удобное для них время.
Логистика
Анализ больших данных помогает оптимизировать перевозки, сделать доставку быстрее и дешевле. В компании DHL работа с большими данными коснулась так называемой проблемы последней мили, когда необходимость проехать через дворы и найти парковку перед тем, как отдать заказ, съедает в общей сложности 28% от стоимости доставки. Стали анализировать «последние мили» с помощью информации с GPS и данных о дорожной обстановке. В результате удалось сократить затраты на топливо и время доставки груза.
Внутри компании большие объемы данных помогают отслеживать качество работы сотрудников, соблюдение контрольных сроков, правильность их действий. Для анализа используют машинные данные, например со сканеров посылок в отделениях, и социальные — отзывы посетителей отделения в приложении, на сайтах и в соцсетях.
Читайте также: Чем занимается тимлид-аналитик в сервисе срочной доставки Gett Delivery?
Обработка фото
До 2016 года не было технологии нейросетей на мобильных устройствах, это даже считали невозможным. Прорыв в этой области (в том числе благодаря российскому стартапу Prisma) позволяет нам сегодня пользоваться огромным количеством фильтров, стилей и разных эффектов на фотографиях и видео.
Аренда недвижимости
Сервис Airbnb с помощью технологий Big Data изменил поведение пользователей. Однажды выяснилось, что посетители сайта по аренде недвижимости из Азии слишком быстро его покидают и не возвращаются. Оказалось, что они переходят с главной страницы на «Места поблизости» и уходят смотреть фотографии без дальнейшего бронирования.
Компания детально проанализировала поведение пользователей и заменила ссылки в разделе «Места поблизости» на самые популярные направления для путешествий в азиатских странах. В итоге конверсия в бронирования из этой части планеты выросла на 10%.
*деятельность компании Meta Platforms Inc., которой принадлежит Инстаграм / Фейсбук, запрещена на территории РФ в части реализации данной (-ых) социальной (-ых) сети (-ей) на основании осуществления ею экстремистской деятельности
Кто работает с большими данными?
Три основные профессии в больших данных: дата-инженер, дата-сайентист, аналитик данных.
Дата-сайентисты специализируются на анализе Big Data. Они ищут закономерности, строят модели и на их основе прогнозируют будущие события.
Например, исследователь больших объемов данных может использовать статистику по снятиям денег в банкоматах, чтобы разработать математическую модель для предсказания спроса на наличные. Эта система подскажет инкассаторам, сколько денег и когда привезти в конкретный банкомат.
Чтобы освоить эту профессию, необходимо понимание основ математического анализа и знание языков программирования, например Python или R, а также умение работать с SQL-базами данных.
Аналитик данных использует тот же набор инструментов, что и дата-сайентист, но для других целей. Его задачи — делать описательный анализ, интерпретировать и представлять данные в удобной для восприятия форме. Он обрабатывает данные и выдает результат, составляя аналитические отчеты, статистику и прогнозы.
С Big Data также работают и другие специалисты, для которых это не основная сфера работы:
- дизайнеры интерфейсов, анализирующие данные поведенческих исследований для создания пользовательских интерфейсов;
- NLP-инженеры, которые разрабатывают программы для чат-ботов и автоматизации колл-центров, анализируя естественный язык;
- маркетологи-аналитики, которые исследуют массив данных для выстраивания маркетинговой политики и персонализации рекламы;
- инженеры и программисты на предприятиях, занимающиеся обработкой объема данных.
Дата-инженер занимается технической стороной вопроса и первый работает с информацией: организует ее сбор, хранение и первоначальную обработку.
Дата-инженеры помогают исследователям, создавая ПО и алгоритмы для автоматизации задач. Без таких инструментов большие данные были бы бесполезны, так как их объемы невозможно обработать. Для этой профессии важно знание Python и SQL, уметь работать с фреймворками, например со Spark.
Александр Кондрашкин о других профессиях, в которых может понадобиться Big Data: «Где-то может и product-менеджер сам сходить в Hadoop-кластер и посчитать что-то несложное, если обладает такими навыками. Наверняка есть множество backend-разработчиков и DevOps-инженеров, которые настраивают хранение и сбор данных от пользователей».
Востребованность больших данных и специалистов по ним
Востребованность больших данных растет: по исследованиям 2020 года, даже при пессимистичном сценарии объем рынка Big Data в России в 2024 году вырастет с 45 млрд до 65 млрд рублей, а при хорошем развитии событий — до 230 млрд.
Компании все чаще прибегают к анализу больших данных, так как те, кто этого не делает, замечают упущенную выгоду: The Bell приводит пример корпорации Caterpillar. В 2014 году ее дистрибьюторы ежегодно упускали от $9 до $18 млрд прибыли только из-за того, что не внедряли технологии обработки Биг Дата. Теперь 3,5 млн единиц техники компании оборудованы датчиками, которые собирают информацию о ее состоянии и степени износа ключевых деталей, что позволяет лучше управлять затратами на техобслуживание.
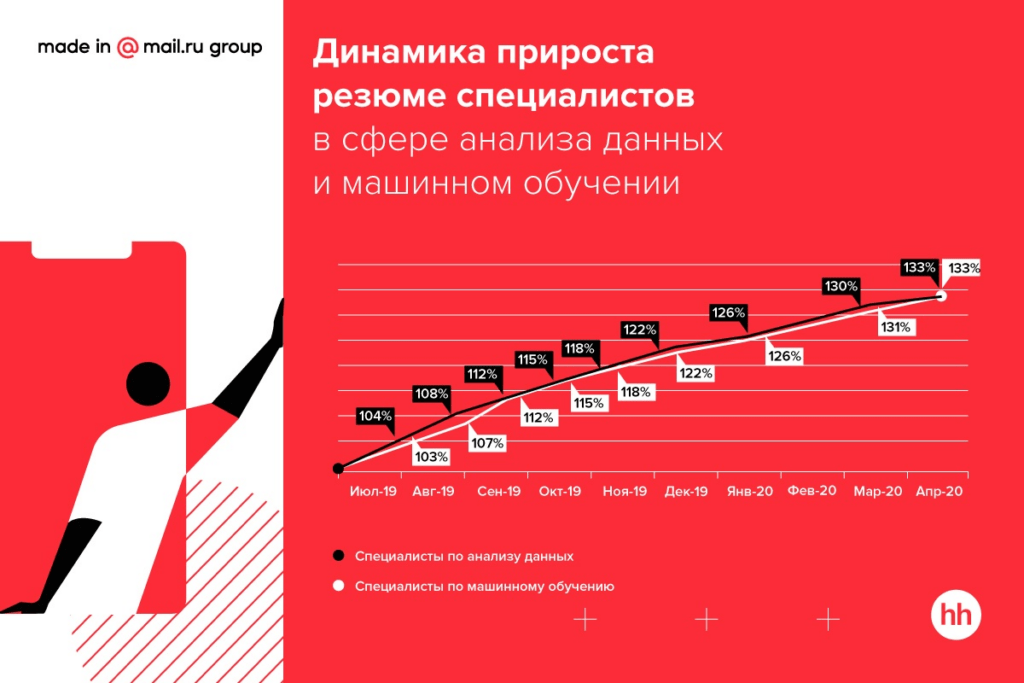
Более трети вакансий для специалистов по анализу данных (38%) приходится на IT-компании, финансовый сектор (29%) и сферу услуг для бизнеса (9%). В сфере машинного обучения IT-компании публикуют 55% вакансий на рынке, 10% приходит из финансового сектора и 9% — из сферы услуг.
Как начать работать с большими данными?
Проще будет начать, если у вас уже есть понимание алгоритмов и хорошее знание математики, но это не обязательно. Например, Оксана Дереза была филологом и для нее главной трудностью в Data Science оказалось вспомнить математику и разобраться в алгоритмах, но она много занималась и теперь анализирует данные в исследовательском институте.
Еще несколько историй людей, которые успешно освоили data-профессию.
Виктор Коваценко: Как я бросил финансы, изучил Data Science и уехал работать в Берлин
Иван Алешин: Я был геологом и ездил в тайгу, а теперь работаю дата-сайентистом в зарубежной компании
Леонид Яковлев: Как я бросил нелюбимую работу и стал аналитиком данных
Если у вас нет математических знаний, на курсе SkillFactory «Data Science с нуля» вы получите достаточную подготовку, чтобы работать с большими данными. За год вы научитесь получать данные из веб-источников или по API, визуализировать данные с помощью Pandas и Matplotlib, применять методы математического анализа, линейной алгебры, статистики и теории вероятности для обработки данных и многое другое.
Чтобы стать аналитиком данных, вам пригодится знание Python и SQL — эти навыки очень популярны в вакансиях компаний по поиску соответствующей позиции. На курсе «Аналитик данных» вы получите базу знаний основных инструментов аналитики (от Google-таблиц до Python и Power BI) и закрепите их на тренажерах.
Важно определиться со сферой, в которой вы хотите работать. Студентка SkillFactory Екатерина Карпова, рассказывает, что после обучения ей была важна не должность, а сфера (финтех), поэтому она сначала устроилась консультантом в банк «Тинькофф», а теперь работает там аналитиком.
FAQ
Big Data — это большие объемы данных, которые невозможно обработать и анализировать с помощью стандартных средств.
Технологии Big Data применяются во многих сферах, таких как банковское дело, здравоохранение, розничная торговля, производство, научные исследования и др.
Технологии Big Data используются для анализа больших объемов данных, выявления скрытых закономерностей, определения потребностей клиентов и оптимизации бизнес-процессов.
Работа с Big Data — это анализ больших объемов данных с помощью специальных технологий, которые позволяют обрабатывать и анализировать данные быстро и эффективно.
Для работы с Big Data необходимо знание базовых технологий, таких как Hadoop, Spark, NoSQL и др.
С Big Data работают аналитики данных, разработчики, инженеры данных, специалисты по машинному обучению и др.
Примеры больших данных включают в себя данные о клиентах, данные о продажах для бизнеса, данные о посетителях веб-сайтов, данные о здоровье и др.
Big Data хранятся на серверах в облаке или на серверах компаний, которые занимаются обработкой данных.
Учиться Big Data можно на онлайн-курсах, в университетах, технических колледжах и других учебных заведениях.
В Big Data используется язык программирования Java, Python, R, Scala и др.
Да, можно. Для этого нужно изучить базовые принципы и технологии работы с данными, учиться на курсах и в онлайн-школах, получать опыт работы в сфере аналитики данных.
Подведем итоги
Большие данные (Big Data) — это, простыми словами, огромные объемы информации, которые невозможно обработать стандартными средствами. Этот термин широко используется во многих сферах, включая финансы, медицину, розничную торговлю и научные исследования.
Для эффективной работы с такими данными требуются специализированные технологии и инструменты.
Сегодня технологии Big Data становятся все более популярными. В сфере бизнеса они применяются для анализа рыночных тенденций, прогнозирования спроса и оптимизации производственных процессов. В медицине эти технологии помогают улучшить диагностику и разработать более эффективные методы лечения.
Для работы с большими данными необходимо владеть основными технологиями, такими как Hadoop, Spark и NoSQL. Аналитики данных, разработчики и инженеры применяют эти инструменты в повседневной практике. Кроме того, существует множество онлайн-курсов и образовательных программ, которые помогают изучить основы работы с Big Data и получить соответствующие навыки.
Анализ больших объемов данных может осуществляться на различных языках программирования, таких как Java, Python, R и Scala. Эти инструменты обеспечивают эффективную обработку данных и извлечение ценной информации.
Таким образом, понимание термина Big Data и умение работать с такими данными становятся все более важными для специалистов в различных областях. Развитие технологий Big Data открывает новые возможности для улучшения бизнес-процессов, научных исследований и повышения качества жизни.