


Чтобы хранить большие данные, нужна специальная архитектура: такая, которая позволит ими удобно управлять. Один из вариантов такой архитектуры — HDFS, распределенная файловая система Apache Hadoop. Рассказываем, как она работает.

Что такое HDFS
HDFS — это файловая система, которую используют в экосистеме Hadoop, одного из инструментов для работы с Big Data. Ее название расшифровывается как Hadoop Distributed File System — распределенная файловая система Hadoop.
Слово «распределенная» означает, что данные в HDFS хранятся не на одном устройстве. Информации много, поэтому ее разделяют на множество мелких блоков и располагают на нескольких десятках, а порой и сотнях серверов. Так сделали, чтобы система могла хранить очень большие объемы данных.
В работе HDFS есть несколько ключевых принципов:
- Данные разбиваются на большие блоки. По умолчанию — 128 МБ на один блок, но в некоторых дистрибутивах Hadoop 3.x размер увеличивается до 256 МБ.
- Блоки копируются на несколько узлов. Это называется репликацией. Один блок информации может одновременно храниться на нескольких серверах.
- Чтение происходит параллельно с разных узлов. Система может считать данные с любых серверов, где есть нужный блок.
Эти принципы нужны, чтобы обеспечить системе масштабируемость и отказоустойчивость. Даже если с одним из серверов что-то случится, за счет репликации данные будут в безопасности. А если увеличить количество устройств, система по-прежнему будет работать корректно.
Еще одна особенность HDFS — высокая скорость пакетной обработки данных. Система дает возможность одновременно работать сразу с группой больших файлов, как будто это единое целое.
Как устроена архитектура HDFS
HDFS — часть архитектуры Hadoop, и ее собственное устройство адаптировано под этот инструмент. Устройства, на которых хранятся данные, распределяются по кластерам — группам серверов. А управлением занимаются отдельные сервера. Вот как это работает и из каких компонентов состоит система.
NameNode: главный узел
Это центральный компонент, вокруг которого строится вся файловая система. Без него HDFS не сможет работать. Он выполняет сразу несколько задач:
- Хранит метаданные, то есть информацию об устройстве системы. Например, структуру каталогов, информацию о файлах и расположении блоков на серверах.
- Решает, откуда получить реплицированную информацию, если какой-то из серверов не работает.
- Обрабатывает запросы клиента, который хочет получить доступ к тому или иному блоку. Задача NameNode — предоставить информацию о том, где находятся нужные данные. Сам он с ними не взаимодействует.
В NameNode есть два типа файлов: FSImage и EditLogs. Первый хранит информацию об образах системы: описания каталогов, вложенных папок и структуры файлов. Второй логирует изменения. Если в HDFS, например, появляется новая папка, EditLogs записывает информацию об этом.
Если перезагрузить NameNode, информация из EditLogs подгрузится в FSImage, и образ системы обновится.

Secondary NameNode: вторичный главный узел
Важно понимать: «вторичный» не означает «резервный». Secondary NameNode нужен не как подстраховка на случай отказа NameNode. У него своя задача: периодически объединять FSImage и EditLogs.
Дело в том, что HDFS может работать без перезапуска очень много времени — вплоть до нескольких недель. Если все это время FSImage не будет обновляться, там не будет части информации. А EditLogs, наоборот, разрастется до огромных размеров.
Чтобы такого не происходило, и нужен вторичный главный узел. Он время от времени переносит информацию из EditLogs в FSImage и обновляет данные без остановки системы. А если главный узел даст сбой, вторичный поможет быстрее его восстановить.
DataNode: узлы данных
Так называются рабочие узлы, на которых непосредственно хранятся блоки данных. Каждый блок по умолчанию реплицируется на три DataNode, хотя количество копий можно настроить.
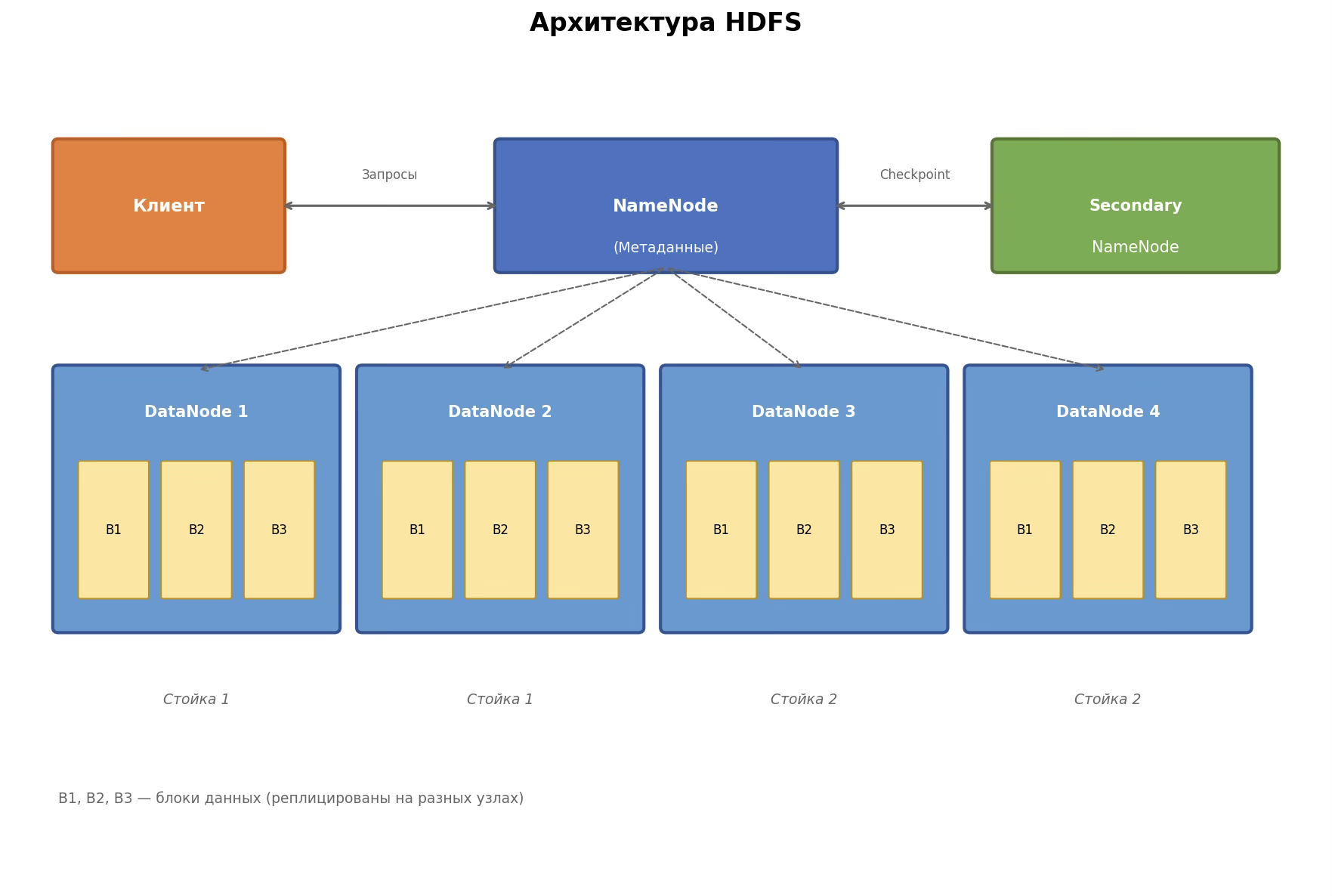
Узлы распределяются по определенным правилам — так архитектура будет устойчивее к сбоям. Например, NameNode и Secondary NameNode должны работать на отдельных серверах, не на DataNode. По умолчанию это одиночные роли.
Какими бывают перезапуски HDFS
Одна из важных особенностей HDFS — система может месяцами работать без остановки. Но бывает так, что NameNode нужно перезапустить, планово или нет. Когда это происходит, информация из EditLogs передается в FSImage.
Плановые перезапуски обычно связаны:
- с обновлением версии Hadoop;
- с изменением конфигурации файловой системы;
- с обновлением операционной системы сервера.
Внеплановые перезапуски чаще всего означают, что в работе HDFS что-то пошло не так. Например, среди возможных причин можно выделить:
- сбой оборудования;
- ошибки в метаданных;
- перегрузка NameNode.
Менее критичная ситуация — необходимость перезагрузить DataNode. Благодаря тому что данные реплицируются, перезапуск этих серверов обычно не влияет на работу кластера. Поэтому DataNode можно перезагружать чаще, чем NameNode, без серьезных последствий.
Особенности HDFS
Файловая система специально предназначена для работы с большими данными. Кластеризация, репликация, распределение на блоки — все это нужно, чтобы эффективно обрабатывать огромное количество информации без потерь. А особенности архитектуры HDFS дают три ключевых эффекта:
- Параллельное чтение. К разным блокам одного файла могут обращаться несколько процессов одновременно, например во время ETL-операций.
- Отказоустойчивость. У каждого блока есть несколько копий, которые хранятся на разных узлах. Даже если какой-то из серверов выйдет из строя, информация по-прежнему останется в целости и сохранности.
- Горизонтальное масштабирование. Если компании понадобилось больше емкости для хранения данных, ей достаточно добавить новые DataNode. Они автоматически подключатся к системе и будут работать наравне с остальными.
Как и зачем используют HDFS
HDFS — удобная, но не универсальная система для хранения больших данных. Есть несколько сценариев работы, для которых она подходит лучше всего:
- Хранение терабайтов и петабайтов данных. Оптимальнее всего HDFS работает с крупными файлами, которые можно разбить на несколько блоков. Так данные эффективнее распределяются по кластерам, и их обработка ускоряется.
- Пакетная обработка файлов. То есть работа с целой группой или пакетом данных одновременно. Например, такой подход используется в фреймворках Spark и MapReduce.
- Сценарии append-only. То есть такие, при которых в хранилище только добавляют новые файлы, а старые не изменяют. Например, подобные сценарии используют при работе с логами и журналами событий, а еще для хранения сырых данных.
- Построение отказоустойчивой системы. Репликация позволяет защитить данные даже в случае сбоя оборудования.
- Потребность в дешевом масштабировании. С HDFS масштабировать систему просто — достаточно добавить новые DataNode.
Но есть ситуации, в которых использовать HDFS — неоптимальное решение. Дело в том, что система плохо справляется с хранением мелких файлов, размер которых меньше 128 МБ — одного блока. При хранении таких данных HDFS будет работать медленно и с риском перегрузки NameNode.
Еще HDFS плохо справляется с частыми обновлениями и изменениями данных. Ее не советуют использовать для аналитики в реальном времени или быстрых точечных запросов. Если компании важно, чтобы система выдавала информацию с задержкой меньше миллисекунды, HDFS для нее не подойдет.
Преимущества и недостатки HDFS
Какие существуют альтернативы HDFS
Раньше HDFS и другие подобные системы использовались чаще, чем сейчас. Дело в том, что HDFS можно развернуть только на собственных серверах. А в последние годы компании предпочитают строить инфраструктуру в облаке, и на то есть причины:
- облака легче масштабировать — не нужно добавлять серверы вручную;
- облачное хранение дешевле собственных кластеров;
- репликация и durability уже встроены в облачное решение, их не нужно настраивать;
- вычисления отделены от хранения — так с данными удобнее работать.
Так что вместо «классических» файловых систем вроде HDFS большие данные все чаще хранят в облаках. Тут тоже есть свои популярные решения — вот какие.
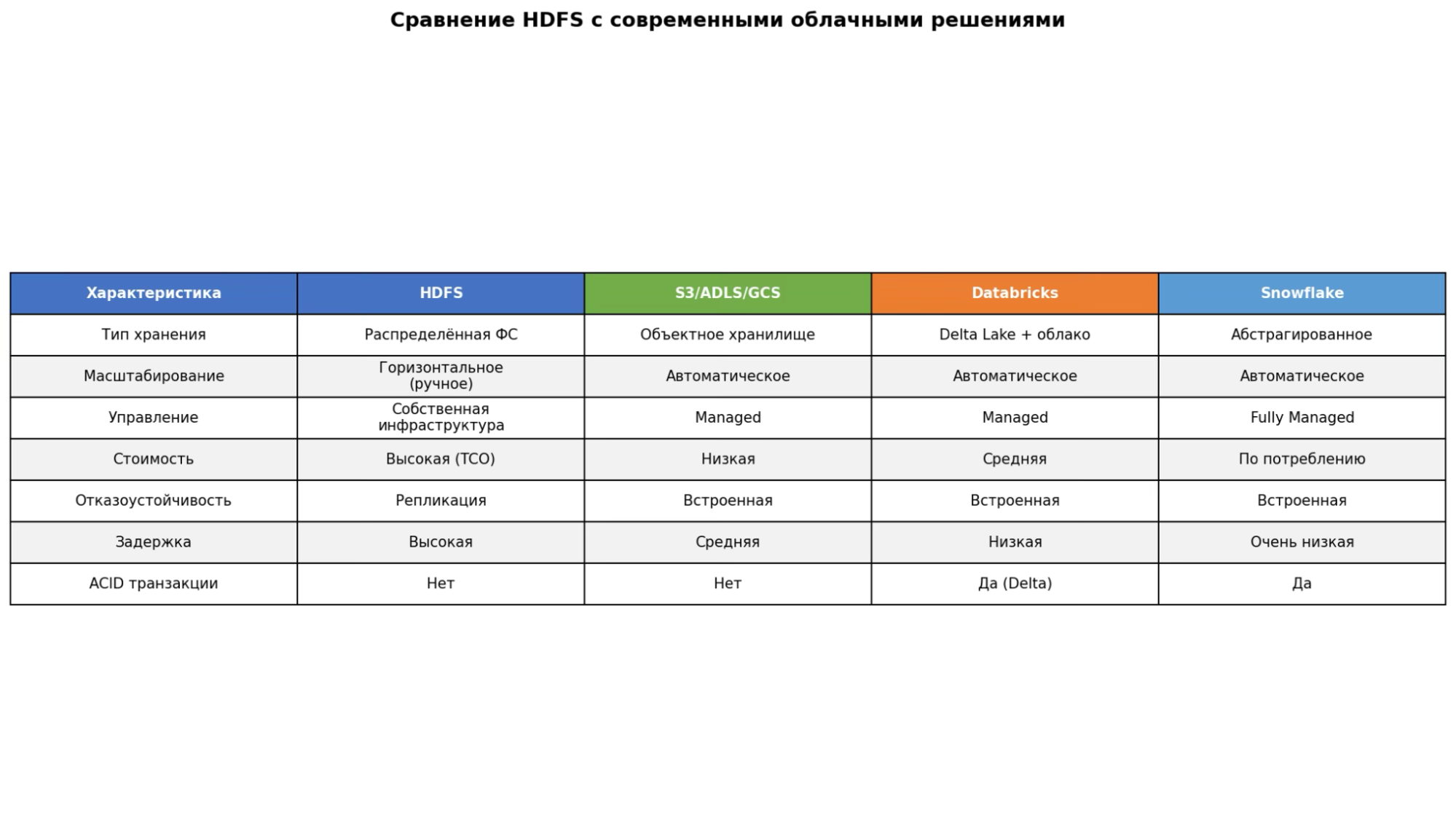
Облачные объектные хранилища. Их иногда называют «новым HDFS» в мире больших данных — они успели стать своеобразной классикой. Среди самых популярных вариантов:
- AWS S3 — продукт от Amazon, «золотой стандарт» для хранения данных;
- Azure ADLS Gen2 и Blob — облачные решения от Microsoft;
- Google Cloud Storage (GCS) — облако от Google с аналогичной функциональностью.
Многофункциональные платформы. Они включают в себя не только хранилище, но и какие-то дополнительные возможности: оптимизацию, работу с таблицами и так далее. Вот какие решения популярны сейчас:
- Databricks. На платформе используется связка из файловой системы DBFS, объектного хранилища S3/ADLS/GCS и фреймворка Delta Lake. Последний позволяет работать с транзакциями данных и оптимизирует хранение.
- Snowflake. Это хранилище, полностью абстрагированное от человека. Физически данные находятся в S3, ADLS или GCS, но пользователь не взаимодействует с ними напрямую. Он работает только с таблицами через язык запросов SQL.
- Google BigQuery. В этом решении используется Colossus — проприетарное распределенное хранилище Google. Его иногда называют «HDFS нового поколения».
Отечественные решения. Системы, перечисленные выше, актуальны во всем мире. Но в России есть свои облачные хранилища — ведь законодательство требует от бизнеса хранить данные на отечественных серверах. Вот какими платформами часто пользуются российские компании:
- Yandex Cloud. Это многофункциональная облачная система от Яндекса. Среди ее компонентов, например, Yandex DataProc — управляемый сервис Spark и Hadoop, интегрированный с Yandex Object Storage. Он позволяет быстро создавать кластеры и распределенно обрабатывать данные.
- VK Cloud. Это платформа от VK, в которую входит набор сервисов Cloud Big Data для работы с большими данными. Система построена на базе Apache Hadoop, Spark и ClickHouse.
- Arenadata. Это ведущий российский разработчик ПО для управления данными. В частности компания создала Arenadata Hadoop (ADH) — первый российский дистрибутив Hadoop, сертифицированный ODPi. И аналитическую СУБД Arenadata DB для построения корпоративных хранилищ данных.
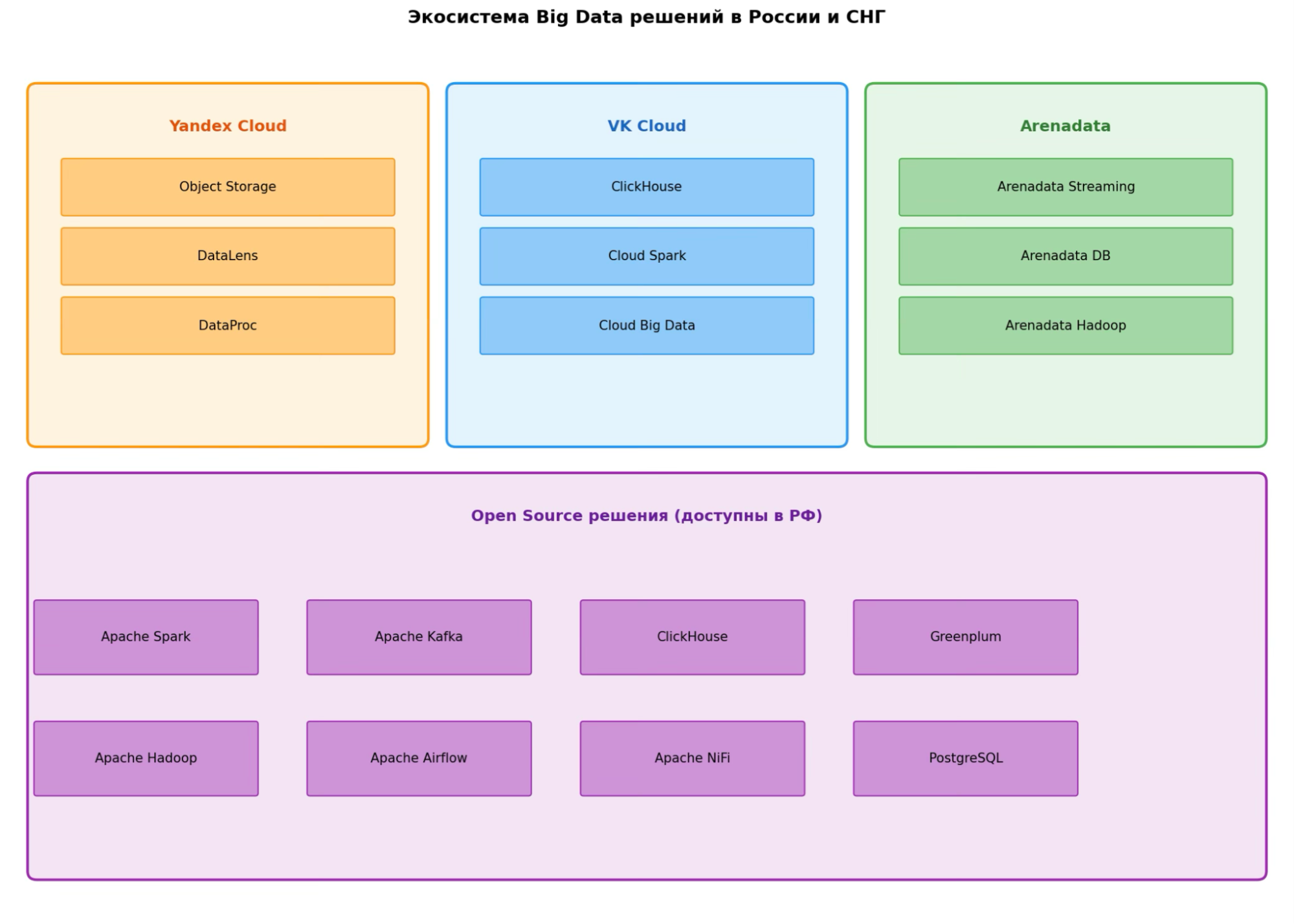
Эти решения — комплексные и проприетарные, то есть принадлежат какой-то компании. Но кроме них, российское IT активно использует открытые технологии. Например, аналитическую СУБД ClickHouse от Яндекса, базу данных Greenplum, платформу Apache Kafka для потоковой обработки сообщений и многое другое.
Краткие выводы
- HDFS — файловая система для работы с большими данными, которая входит в экосистему Hadoop. Когда-то она была «золотым стандартом» для хранения Big Data.
- Данные в HDFS разбиваются на блоки, которые хранятся на кластерах серверов. Каждый блок реплицируется — несколько раз копируется, и копии сохраняются в разных местах.
- Серверами данных управляет NameNode — главный сервер, на котором хранятся метаданные о файловой системе. Если он выйдет из строя, отказать может вся система.
- Основные плюсы HDFS — отказоустойчивость, легкое масштабирование и удобство пакетной обработки данных. Минусы — проблемы при работе с маленькими файлами и зависимость от NameNode.
- В последние годы HDFS вытеснен облачными решениями. Но его все еще можно встретить в старых Hadoop-кластерах или в компаниях, которые не могут пользоваться облаками по закону.
