
Машинное обучение — это методы искусственного интеллекта, которые позволяют построить обучаемые модели для разных целей: например, автоматизации процессов, автоматического перевода текстов, распознавания изображений. Именно машинное обучение помогает ранжировать контент в лентах социальных сетей и создавать чат-ботов, которые общаются на естественном языке.

Типы машинного обучения
Выделяют два типа машинного обучения: дедуктивное и индуктивное.
Дедуктивное обучение (экспертные системы). В этом случае в задачах есть сформулированные и формализованные знания. Например, это может быть база данных, в которой указано, что если температура больше 30 градусов, то нужно включить кондиционер, а если на улице идет дождь — закрыть окна. Нужно вывести из них новое правило, которое можно применить к конкретному случаю. Экспертные системы чаще относят к ответвлению кибернетики — науки об управлении информацией в сложных системах, — чем к машинному обучению.

Индуктивное обучение подразделяется на:
- Обучение с учителем. Пример задач: по предыдущему курсу валют предсказать курс на завтрашний день; отличить по изображениям кошек от собак (в этом случае изначально должна быть информация, на какой картинке и где изображены кошка и собака).
- Обучение без учителя. Пример задачи: разделить группу пользователей сайта на основе их интересов или демографических характеристик. Обычно нужно знать, сколько групп уже имеется в данных.
- Обучение с подкреплением (reinforcement learning). Пример: игра Super Mario, в которой компьютер (агент) взаимодействует со средой (уровень игры) и получает положительные или отрицательные очки.
- Активное обучение. Пример: подсказка слов на клавиатуре телефона.
Многие методы индуктивного обучения связаны с извлечением информации (information extraction). Например, создание для пользователя дополнительного признака на основе его транзакций, чтобы понять, потратил ли клиент в этом месяце больше, чем в предыдущем.
Основные методы машинного обучения
Обучение с учителем (supervised learning)
Для этого алгоритма обучения нужны данные, на основе которых будет строиться модель. К supervised learning относятся задачи классификации, прогнозирования и ранжирования и регрессии.
Например, на основе данных о продажах квартир в Москве можно создать алгоритм, который будет оценивать стоимость жилья, выставляемого на продажу. Для алгоритма нужны данные вида X, Y. Если предположить, что X — это таблица с параметрами домов, то Y — таблица со стоимостью каждого дома. Таким образом можно обучить модель предсказывать по параметрам дома его стоимость. Обычно это выражают в виде функции F(X) = Y.
Небольшая часть данных для алгоритма будет выглядеть так:
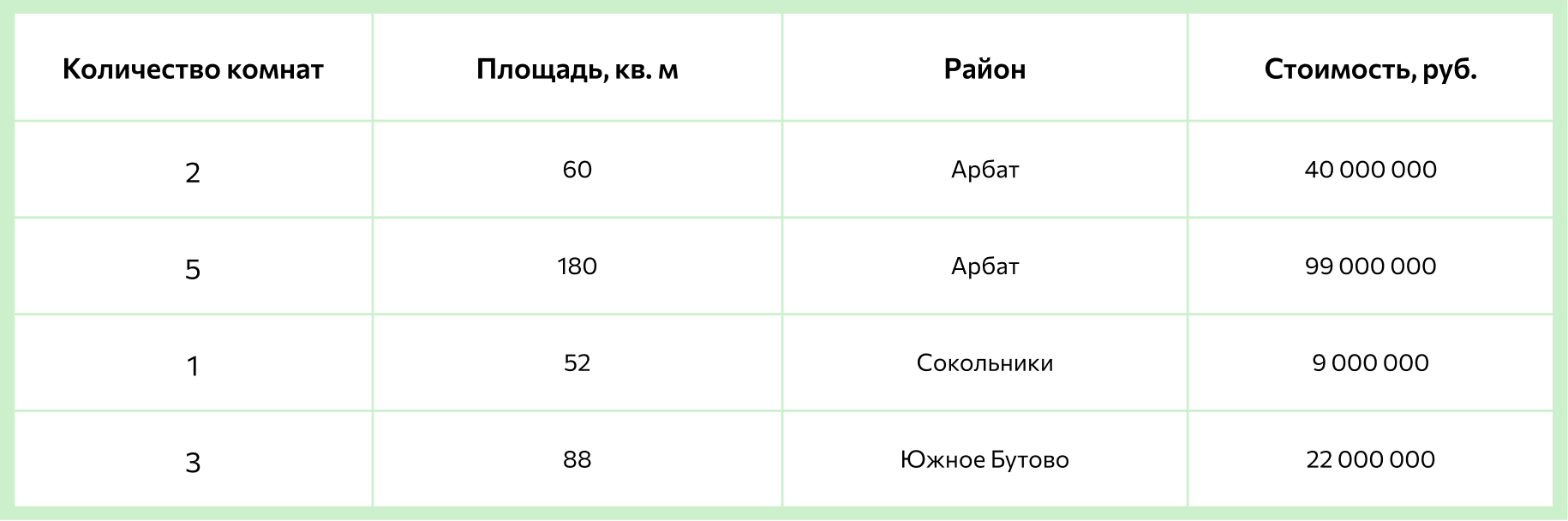
Благодаря этим данным алгоритм сможет определить цену квартиры в Москве.
Обучение без учителя (unsupervised learning)
При обучении без учителя задействуются неклассифицированные данные. Главное отличие от предыдущего пункта — это то, что тут нет Y, то есть имеется список домов, но неизвестна их стоимость. В этих данных нужно будет найти закономерности, а также создать их структуру. К формам обучения без учителя относят, например:
- кластеризацию — разбивку данных на похожие категории. Например, космические объекты объединяются в конкретные категории по схожим признакам: размеру, удаленности, типу;
- уменьшение размерности — снижение количества признаков наборов данных. Например, можно визуализировать данные о пользователях (их пол, возраст, платежеспособность, город и т.д.) на одном графике. Для этого какие-то признаки нужно убрать, а какие-то — трансформировать специальными методами.
Вернемся к примеру с продажей квартир. Бывает, что невозможно собрать полную информацию по каждому объекту. Тогда алгоритмы машинного обучения будут искать закономерности среди имеющихся вводных.
Так, можно создать алгоритм, автоматически определяющий разные рыночные сегменты. Тогда можно обнаружить, что покупатели недвижимости рядом с университетом выбирают маленькие квартиры, а владельцы коттеджей — дома с большой площадью.

Обучение с подкреплением (reinforcement learning)
В этом случае есть так называемый агент (A), который обычно моделируется нейронной сетью. Этот агент должен на каждом шаге взаимодействия со средой (E) предсказывать действие, позволяющее максимизировать награду, которую можно получить. Обучение с подкреплением больше всего похоже на то, как учатся дети: если ребенок дотронется до горячего чайника, он обожжется, получит негативную награду (или опыт) и в дальнейшем перестанет его трогать. Сейчас обучение с подкреплением активно используется для сборки кубика Рубика и в компьютерных играх.
Топ библиотек для машинного обучения
JavaScript
TensorFlow.js
Machine learning tools
Brain.js
PHP
PHP-OPENCV
RubixML
PHP-ML
Tesseract for PHP
R
Python
SciPy
NumPy
Pandas
Keras
Skikit-learn
Java
Massive Online Analysis (MOA)
Weka
MALLET
ELKI

0 комментариев