SRE (Site Reliability Engineering) — это инженерный подход в области поддержки ИТ-инфраструктуры, который придумал вице-президент Google по разработке Бен Трейнор Слосс в 2003 году. Подход состоит в том, чтобы сделать онлайн-сервисы надежными и предсказуемыми в продакшене.

Если коротко, то SRE помогает поддерживать сервис в рабочем состоянии и снижает риск сбоев с помощью инженерных методов, через метрики и автоматизацию. При этом система должна быть максимально автономной и тратить минимум человеческих ресурсов.
Термин SRE и его принцип Бен Трейнор обсудил в интервью с другим инженером по обеспечению надежности Google Найлом Мерфи.
Зачем нужен SRE
Главные цели SRE — заранее выявлять риски, сокращать число инцидентов и снижать их влияние на пользователей.
На практике это означает понять, что для пользователя считается нормальной работой сервиса, выразить это метриками (SLI) и целями (SLO), спланировать реакцию на отклонения и снизить риск изменений через правила и автоматизацию.
Чем занимается SRE-инженер
- Мониторинг и алертинг
SRE определяет набор SLI (индикаторов надежности) и настраивает систему так, чтобы видеть, как влияют проблемы на пользователя.
- Реагирование на инциденты
SRE участвует в дежурных ситуациях, восстанавливает работоспособность сервиса, координирует действия и коммуникации во время инцидента.
- Автоматизация типовых операций
Цель автоматизации в SRE — уменьшить объем повторяющихся ручных действий и ускорить восстановление и обслуживание системы в случае инцидентов.
- Разбор причин инцидента и постмортемы
После инцидента SRE организует разбор, что произошло, почему система отказала, какие защитные механизмы не сработали и какие изменения нужно внедрить, чтобы снизить вероятность повторения.
- Планирование объема ресурсов и надежности
SRE-инженер оценивает нагрузку на систему и рассчитывает объем ресурсов, чтобы рост трафика не привел к падению системы. Он выявляет узкие места в системе и повышает ее устойчивость.
Где работает SRE-инженер
Специалисты по SRE обычно работают в специальных командах. В статье Google Cloud описывают несколько способов организовать SRE. Google выделяют шесть направлений: kitchen sink (everything SRE), infrastructure, tools, product (application), embedded, consulting. Но в реальности организации часто комбинируют подходы.
- Kitchen sink (Everything SRE). Идиома kitchen sink означает «все возможное и без исключений». В контексте SRE это модель, где одна команда отвечает за весь спектр задач: от инфраструктуры и мониторинга до разработки инструментов и поддержки приложений. В компаниях с такой моделью пока нет отдельных SRE-специалистов, но они потребуются при увеличении трафика.
- Infrastructure SRE. Такие команды обеспечивают надежность общей технической базы (сеть, балансировщики, базы и хранилища, системы деплоя, мониторинг и доступы), на которой работают продуктовые сервисы. SRE отвечают за надежность платформы и единые стандарты для продуктовых команд.
- Tools SRE. Эти SRE делают внутренние инструменты для поддержки надежности, например, шаблоны мониторинга и алертов, панели с показателями, инструменты для планирования нагрузки, ресурсов и действий при сбоях.
- Product (application) SRE. Это SRE, которые сосредоточены на надежности конкретного продукта или приложения. При этом надежность вспомогательных сервисов может оставаться на других специалистах (например, разработчиках со знанием DevOps).
- Embedded SRE. SRE может работать с разработчиками конкретного сервиса или группы сервисов. На одну такую часто команду приходится один специалист по SRE. Он помогает команде формулировать SLO, настраивать наблюдаемость, улучшать процессы релизов и готовность к инцидентам. SRE-инженер может вносить изменения в код и конфигурации сервисов.
- Consulting SRE. Отличается от embedded только тем, что в такой команде SRE-специалист не вносит изменения в код, а консультирует команду разработчиков или разрабатывают отдельные инструменты для интеграции их разработчиками.
Разница между SRE и DevOps
И SRE, и DevOps стремятся к тому, чтобы изменения доходили до продакшена быстрее и безопаснее.
DevOps в компании чаще всего:
- поддерживает CI/CD и создает пайплайны,
- делает так, чтобы окружения создавались и обновлялись автоматически,
- настраивает деплой-стратегии (канареечное развертывание, сине-зеленое развертывание, быстрый откат и т. п.),
- стандартизирует сборку, секреты, конфиги, доступы, шаблоны сервисов,
- отвечает за платформу запуска (облако, контейнеры, кластеры).
Результат работы DevOps: релизы становятся регулярными, предсказуемыми и повторяемыми.
SRE в компании:
- формулирует и поддерживает метрики и стандарты качества (что измерять и какой уровень качества считать нормой),
- строит наблюдаемость (метрики, логи, трассировки, дашборды),
- задает правила алертинга,
- участвует в инцидентах с диагностикой, восстановлением, координацией и постмортемами,
- снижает повторяемость проблем с помощью конкретных инженерных изменений и автоматизации,
- планирует объем ресурсов и проверяет готовность к росту нагрузки.
Результат SRE: меньше инцидентов, а если появляются, то проще восстановить систему после них, ниже влияние на пользовательский опыт.
Роли в одной компании
В ИТ-компаниях DevOps фокусируется на механизмах доставки кода, а SRE — на гарантиях безопасности и надежности. Например, нужно провести обновление мобильного банка.
DevOps настроил канареечное развертывание (тест на малой доле трафика, примерно 5%, чтобы не рисковать всеми пользователями) с автоматическим откатом при проблемах.
SRE установил правила: если p95 latency (95-й перцентиль задержки, время, за которое отвечают 95% запросов) или доля 5xx-ошибок (серверные ошибки, как 500 Internal Server Error) выходит за целевые показатели надежности, то развертывание автоматически останавливается и откатывается.
При инциденте:
SRE берет на себя управление инцидентом как структурированным процессом: проводит триаж (быструю оценку проблемы и ее приоритета), определяет severity (уровень серьезности инцидентов), организует коммуникации (уведомления командам и пользователям), обеспечивает восстановление сервиса, а потом составляет постмортем с планом действий.
DevOps подключается, если проблема в платформе (инфраструктуре, например, облаке) или механизмах (CI/CD-пайплайнах или автоматизации.
В российских компаниях, как VK или Ozon, SRE использует инструменты вроде Prometheus для мониторинга и Kubernetes для оркестрации, чтобы инциденты решались максимально быстро.
Ключевые термины SRE
Ранее мы уже упоминали показатели SLO и метрики SLI, теперь разберем эти и другие термины SRE подробнее.
В основе подхода SRE от Google лежат SLI, SLO, SLA, error budget, уменьшение количества ручных операций (toil), наблюдаемость (observability), severity (уровень серьезности) и priority (приоритет) в управлении инцидентами.
Эти термины также описаны в официальной книге Google Site Reliability Engineering (на английском).
SLI, SLO, SLA (объект, цель, результат)
- SLI (Service Level Indicator, индикатор уровня сервиса) — показатель, который напрямую измеряет качество сервиса с точки зрения пользователя.
Он основан на реальных данных о взаимодействии с сервисом и помогает понять, соответствует ли качество ожиданиям. Показатели SLI выбирают таким образом, чтобы они были простыми, релевантными и основанными на пользовательском опыте (например, не на CPU-загрузке сервера, а на скорости загрузки страницы для юзера).
SLI фокусируется на показателях задержки (latency), частоты ошибок (error rate), пропускной способности (throughput) и доступности (availability).
Задержка (latency) — время, которое требуется на обработку запроса и получение ответа. Это не просто среднее время, а перцентиль (например, p95 — время, за которое выполняются 95% запросов.
Пример: для веб-сайта latency — это секунды от клика до загрузки страницы. Если p95 больше 500 мс, пользователи могут раздражаться и уходить. В SRE его измеряют на стороне сервера или клиента, чтобы избежать искажений от сети.
Частота ошибок (error rate) — процент неудачных запросов по отношению к общим. Это включает HTTP-ошибки (например, 4xx — клиентские, как 404 Not Found, 5xx — серверные, как 500 Internal Server Error) или кастомные сбои (например, неудачный логин).
Пример: если из 1000 запросов 10 провалились, error rate = 1%.
Пропускная способность (throughput) — объем успешно обработанных запросов за единицу времени (например, запросы в секунду, RPS). Это показывает, сколько нагрузки сервис выдерживает без неполадок.
Пример: для стримингового сервиса throughput — количество одновременных просмотров видео. Если он падает ниже нормы, значит, система перегружена, и пользователи видят буферизацию.
Доступность (availability) — процент времени, когда сервис работает корректно и отвечает на запросы. Вычисляется как (время работы / общее время) × 100%.
Пример: доступность в «пять девяток» (99,999%) — это всего 5 минут простоя в год. В SRE availability часто измеряют через успешные запросы, а не просто пинг (ping) сервера, чтобы учесть частичные сбои (например, сервис отвечает, но медленно).
- SLO (Service Level Objective, цель уровня сервиса) — целевое значение для SLI за определенный период, определяющий стандарт работы сервиса для пользователей.
Например, «99.9% успешных запросов за 28 дней» или «p95 latency меньше 300 мс».
В Google SRE SLO делят по типам нагрузки, чтобы учитывать разные сценарии:
Для throughput-клиентов (где важна общая производительность, как в поисковых системах с миллионами запросов) целью может быть «95% запросов менее, чем за 1 секунду». Это значит, что сервис должен выдерживать высокий объем трафика без значительных задержек для большинства пользователей.
Для latency-клиентов (где критична скорость, как в реал-тайм приложениях вроде онлайн-игр или торговых платформ) вероятная цель — «p99 latency < 10 мс» (99-й перцентиль задержки меньше 10 миллисекунд). Здесь сделан фокус на минимизации даже редких замедлений (фризов), так как они значительно ухудшают пользовательский опыт.
- SLA (Service Level Agreement, соглашение об уровне сервиса) — внешний контракт с клиентами, который опирается на SLO, но включает последствия за нарушения (финансовые компенсации, репутационные потери).
В отличие от SLO, SLA — юридически обязывающий документ. Для SRE-инженеров он важен как ориентир для проектирования систем. Они используют его, чтобы установить SLO и SLI, которые должны гарантировать техническую надежность согласно контрактным обязательствам.
В Google SRE отмечается, что SRE-инженеры хотя и помогают определять SLI и SLO, но не занимаются последствиями (это уже бизнес-аспект).

Error budget и откаты
Error budget — это допустимый объем сбоев, вычисляемый как 100% минус SLO (например, для 99,9% SLO бюджет = 0,1%).
Он позволяет контролировать риски. Если error budget исчерпан, релизы сервиса замораживают и фокусируются на фиксах.
В Google этот показатель закрепляют в Error Budget Policy, где прописано, когда изменения можно продолжить, а когда нужно их заморозить до возврата к SLO.
Что называют рутиной (toil)
Toil (рутина) — это такая работа, которая характеризуется как ручная, повторяемая, поддается автоматизации (можно заменить скриптами, например) и не является стратегической в долгосрочной перспективе, а решает лишь текущие проблемы.
В книге Google Site Reliability Engineering toil описывается как операции, которые растут линейно с масштабом сервиса (O(n)), но не улучшают систему. Это, например, ручной деплой или мониторинг без автоматизации.
SRE принципы призваны сократить toil до 50% времени инженера, чтобы избежать выгорания и стагнации сотрудника.
Таким образом, toil — это скорее показатель того, сколько инженерного времени тратится на утомляющую операционную работу, а не на улучшение надежности.
Observability (логи, метрики, трейсы)
Observability — это способность понимать состояние системы по данным, которые она сама отдает. В практическом смысле это три типа сигналов: метрики, логи и трейсы (данные о прохождении запроса через все компоненты системы), которые помогают быстро ответить на вопросы «что сломалось», «где» и «почему».
Severity и priority
- Severity (уровень серьезности) показывает масштаб и влияние проблемы. Из этого показателя можно узнать, сколько пользователей затронуто и насколько сильно деградировал сервис (насколько ухудшилось его качество).
На практике Google сначала оценивают влияние на пользователей и классифицируют инцидент по severity (например, по шкале 1–3, где 1 — критический, а 2–3 менее критичные).
Для sev 1 заранее фиксируют понятные критерии эскалации (передачи инцидентов и проблем более высокому уровню экспертизы) и подключают роли вроде incident manager (управление процессом), scribe (документирование) и communications lead (координация коммуникаций).
- Priority (приоритет) отвечает за то, как быстро нужно реагировать и в каком порядке разбирать несколько задач или инцидентов. В Google подчеркивают, что приоритет задает темп работ и может меняться по мере локализации проблемы (например, сначала максимальный, потом ниже после применения критического фикса), и строится на понимании severity.
Какие навыки нужны SRE-специалисту
Помимо Site Reliability Engineering, где описаны основные термины SRE и участие SRE-команды в жизненном цикле сервиса, Google предлагает еще две книги:
Практическое продолжение с примерами и кейсами. Там много прикладных тем, таких как внедрение SLO, мониторинг, алертинг на основе SLO, on-call, incident response, культура постмортемов, управление нагрузкой.
Это пособие рассказывает, как надежность связана с безопасностью и почему в продакшене они должны идти рука об руку.
Что изучить для уровня джуниор
Для уровня джуниор SRE-инженера нужно знать:
- Базовый уровень Linux и других ОС. Процессы, логи, сеть, диски, права доступа, простая диагностика.
- Сети и HTTP. DNS, TLS в общих чертах, коды ответов, таймауты, ретраи (повторные попытки отправки запроса) и почему они иногда вредны.
- Базы данных и очереди. Подключения, пулы, блокировки, узкие места и их признаки.
- Наблюдаемость. Разница между метриками и логами, роль трейсов, создание простого дашборда и 1-2 алертов.
- Инциденты. Работа по инструкциям (runbook), эскалация, фиксация таймлайна, оценка severity по правилам команды.
- Автоматизация. Простые скрипты для рутинных задач, правка конфигов, базовая проверка работоспособности сервиса.
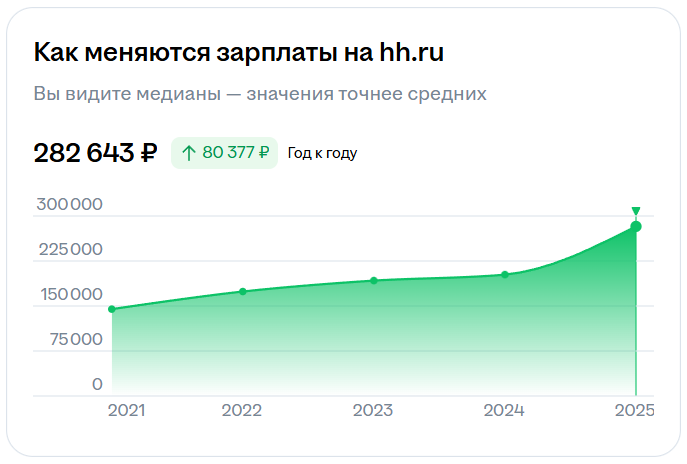
Востребованность вакансии и зарплата
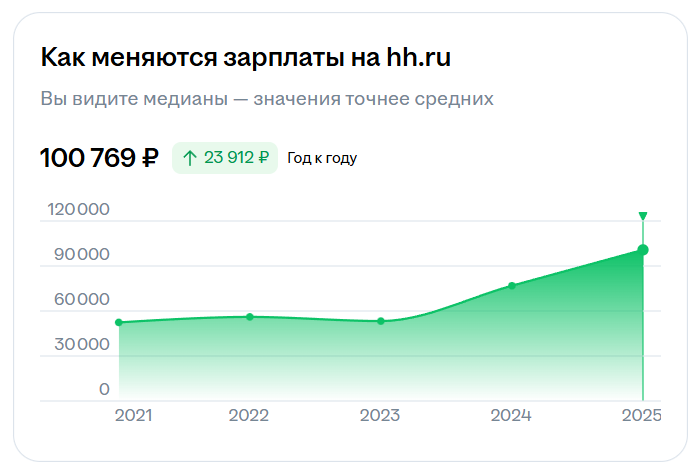
Согласно информации на HH Карьера на декабрь 2025 года, медианная зарплата джуниор SRE-инженера по России — 100 769 ₽.
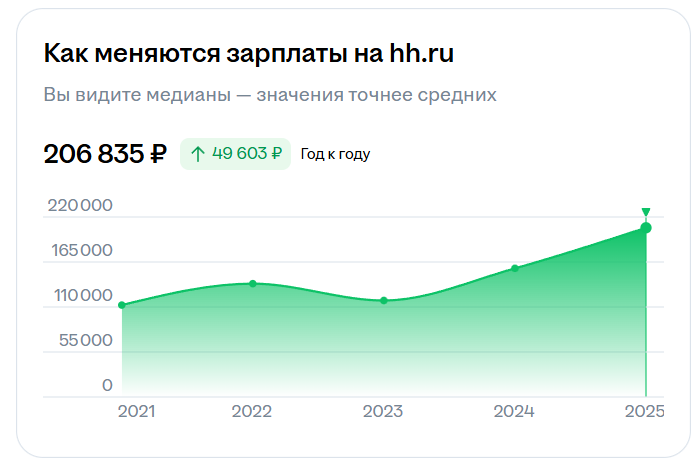
Мидлу предлагают в среднем 206 835 ₽.
Сеньор может претендовать на 282 643 ₽.