
Коллекции в Java — это общее название для нескольких похожих друг на друга структур данных. Это сложные типы, в которых может храниться большое количество значений — как в таблице или в перечне.

Что представляют собой коллекции?
Более простой пример структур — массивы: в них, как в списке или в ряду, хранится сколько-то значений. Но в отличие от массивов коллекции динамические, то есть у них не фиксированная длина. Их размер может меняться, туда можно добавлять и удалять элементы с помощью методов — функций, которые реализуют поведение.
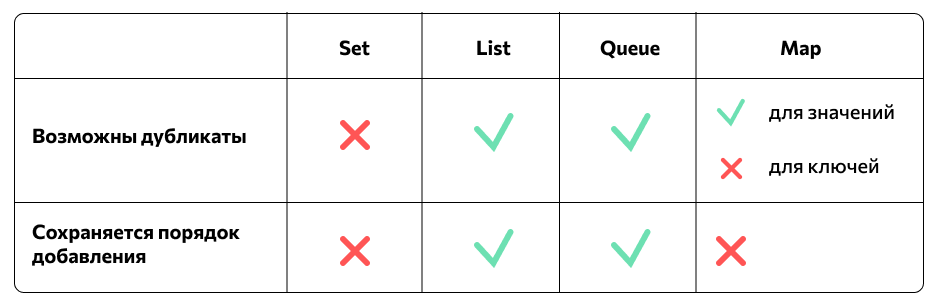
Например, возьмем список чисел: [1, 1, 2, 3, 5]. Весь список — структура данных, в которой хранится 5 элементов. Если к нему можно добавить шестой элемент, допустим 8, — это динамическая структура данных, и она вполне может относиться к коллекциям. На месте чисел могут быть строки, объекты и другие типы данных. Главное — элементы должны быть однородными, одинакового типа. Основных видов коллекций три: List, Set, Queue. Еще есть Map — не коллекция, но связанная с ними структура данных.

Кто пользуется коллекциями
Коллекции нужны каждому Java-разработчику. Динамические структуры данных — это важная и нужная часть языка. Их используют для хранения, обработки и передачи информации, с информацией работает любая программа. При трудоустройстве начинающего Java-разработчика скорее всего будут спрашивать о коллекциях и о том, что он о них знает.
Для чего нужны коллекции
Структуры данных нужны для хранения и получения информации. Но если они статические, в определенный момент пользоваться ими становится неудобно: фиксированное количество элементов не даст расширить структуру. А создавать сразу большой массив неэффективно с точки зрения памяти.
Поэтому существуют динамические структуры. Так как они меняют размер, в них можно хранить практически любое количество информации и не опасаться, что они займут больше места, чем необходимо. Это делает программирование более удобным и ускоряет работу с данными.
Разные варианты коллекций нужны, потому что для различных задач требуются свои особенности хранения и обработки данных. Где-то они должны быть структурированными, а где-то — допустим, уникальными. В одной задаче важно быстро получать элементы, в другой — быстро добавлять. Поэтому реализации разные, и для каждой задачи эффективнее своя.
Что такое Java Collections Framework
Java Collections Framework — это часть JDK, или Java Development Kit, в которой описаны и хранятся коллекции, их устройство и иерархия. Несмотря на название «фреймворк», это не отдельный инструмент, а одна из важных частей языка Java, точнее, набора инструментов для него. Там содержатся интерфейсы, которые описывают коллекции, и практические реализации. Интерфейс — это как бы «схема», теоретическое описание поведения объектов. В нем содержатся методы, которые есть у всех его реализаций. А реализация — потомок интерфейса, практическая структура: такой объект можно создать и пользоваться им.
Интерфейс по определению похож на класс, но отличается от него тем, что может хранить только поведение — методы. У него, в отличие от класса, не может быть атрибутов — внутренних переменных, хранящих состояние. Подробнее про класс как сущность можно прочитать в статье про ООП.
Подробнее об интерфейсах
У интерфейсов есть иерархия — более специфические наследуются от более общих. Это значит, что у них есть методы «предка», но есть и свои, специфичные особенности хранения и методы. А реализации — конечные наследники интерфейсов. Получается наглядная иерархическая схема, где одно вытекает из другого.
Ниже мы рассмотрим разные виды интерфейсов и их практические реализации. Сначала поговорим о базовых интерфейсах, от которых зависит работа всех остальных, а потом перейдем к более специфичным.
Iterable
Это основной, корневой интерфейс. От него наследуются все прочие. Он означает, что объект итерируемый, то есть перечислимый. Так называются сущности, элементы которых можно перечислять по очереди: по индексам, названию или расположению в структуре. То есть это практически все сложные объекты, где хранится множество значений.
У Iterable и, соответственно, у всех интерфейсов, которые от него наследуются, есть метод iterator(). Он возвращает итератор — специальную сущность-«перечислитель», своеобразный курсор, который указывает на тот или иной объект. С помощью итераторов мы получаем доступ к разным значениям коллекции.
Есть только одна сущность, которая не наследуется от Iterable, но тем не менее часто упоминается вместе с коллекциями и входит в Collections Framework. Это Map, и мы поговорим об этом типе ниже.
Iterator
У итератора тоже есть свой интерфейс. Он описывает такие курсоры и возможности, которые у них есть. Методы итератора — это next(), который возвращает следующий элемент, remove(), который удаляет текущий элемент, и hasNext() — он показывает, существует ли в коллекции следующий элемент.
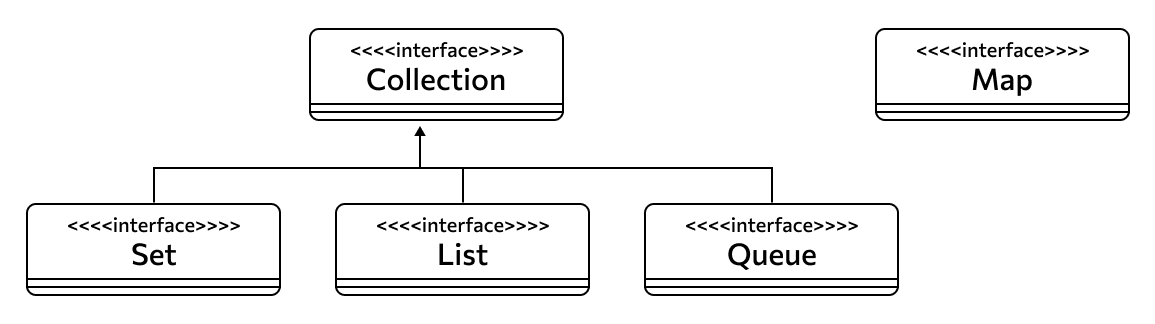
Collection
Часто пишут, что Collection — это основной и самый главный интерфейс. Технически это не совсем так, потому что он все же наследуется от Iterable, но фактически считается базовым. Он описывает понятие коллекции и тем самым расширяет возможности итерируемого объекта.
При этом абстрактного объекта Collection быть не может — реальные сущности должны относиться к одному из потомков этого интерфейса, то есть быть очередью, списком или набором.
Объекты, которые относятся к коллекциям, можно перебирать в цикле for-each. У них есть ряд общих методов, актуальных для всех видов коллекций. Исключение — только Map, который в целом выпадает из этой иерархии.
Методы Collection
- add(item) — добавляет элемент item в коллекцию;
- addAll(collection) — добавляет в коллекцию другую коллекцию, ту, что указана в скобках;
- contains(item) — возвращает true или false в зависимости от того, есть ли в коллекции элемент item;
- containsAll(collection) — работает так же, как предыдущий, но проверяет наличие в коллекции не элемента, а другой коллекции;
- remove(item) — удаляет из коллекции указанный элемент;
- retainAll(collection) — удаляет из коллекции указанную в скобках коллекцию. Обратите внимание: retainAll, не removeAll;
- clear() — очищает коллекцию, то есть удаляет из нее все элементы;
- size() — выдает количество элементов в коллекции в формате целого числа;
- isEmpty() — возвращает true или false в зависимости от того, пуста ли коллекция;
- toArray() — превращает коллекцию в массив.

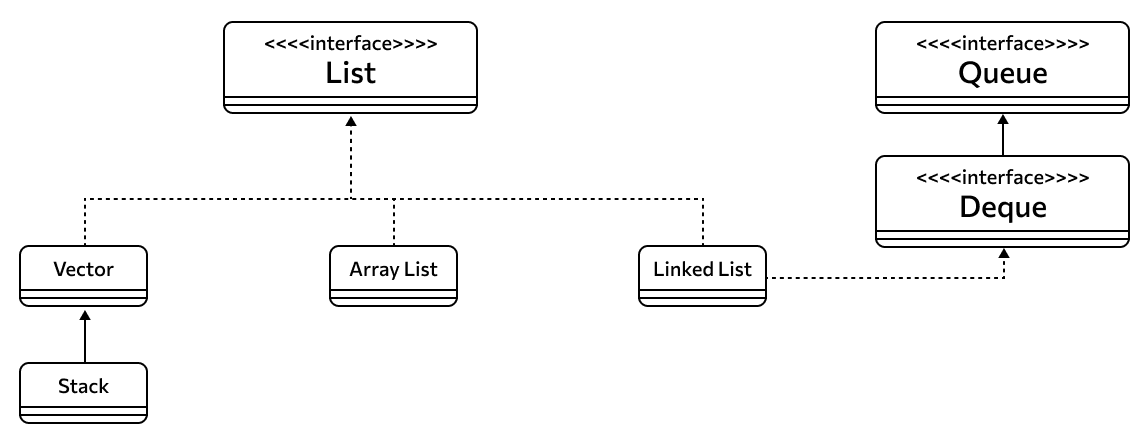
List
Перейдем к дочерним интерфейсам Collection. Их три: List, Set и Queue — правда, от них могут наследоваться другие, дополненные или расширенные интерфейсы. Но основных потомков именно три.
List — интерфейс, который традиционно рассматривают первым и которым пользуются чаще всего. Название переводится как «список»: интерфейс представляет собой упорядоченную коллекцию данных, похожую на массив. Это значит, что у его элементов есть порядковые номера, показывающие их расположение в списке, — индексы. Но, в отличие от массива, List динамический, о чем мы говорили выше, — в нем можно изменять количество элементов.
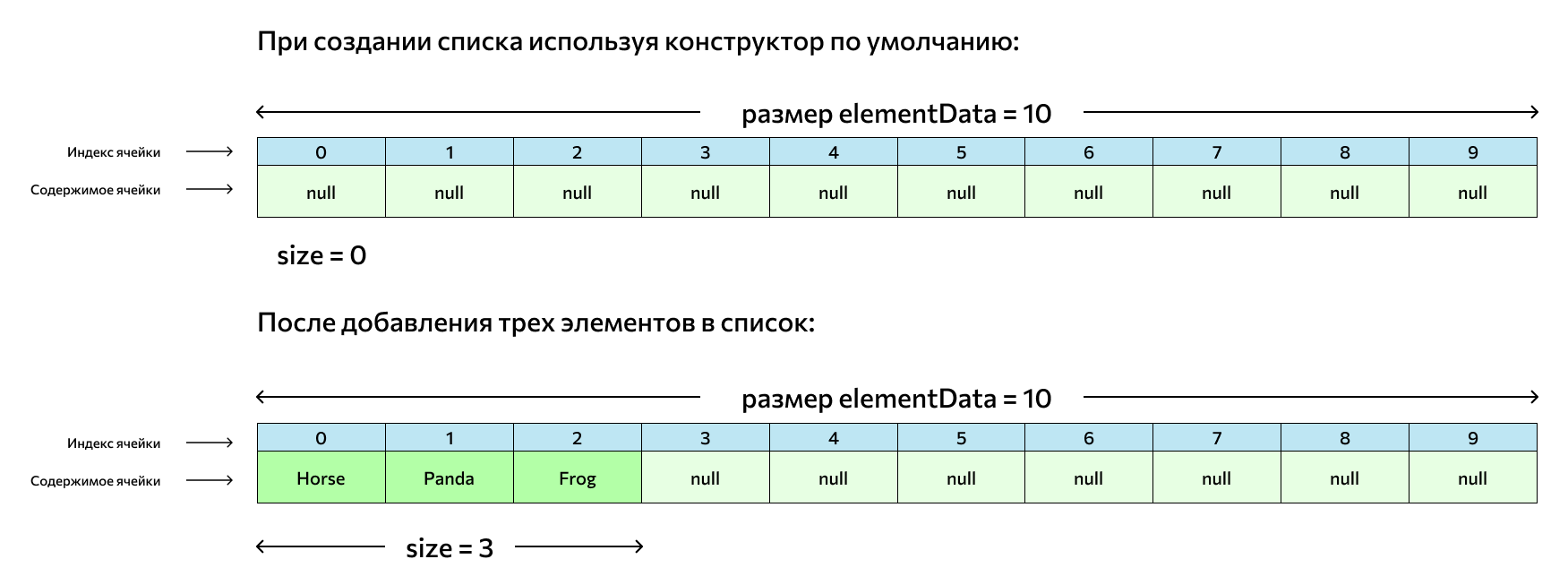
Реализации. Классический динамический массив, или ArrayList, — не единственная реализация List. Сейчас их как минимум четыре, но основной признак всех — упорядоченность элементов.
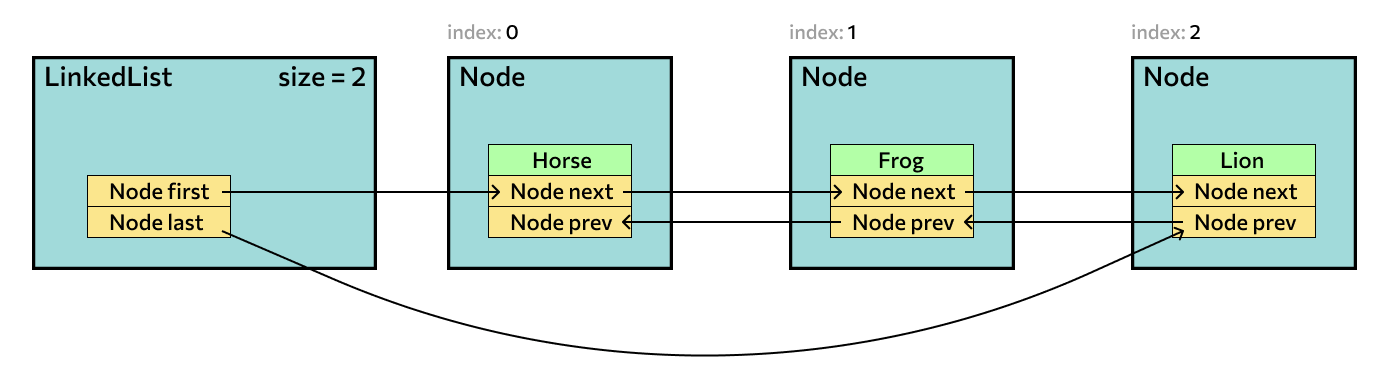
Вторая распространенная реализация — LinkedList, связанный список. Он отличается от ArrayList наличием связности: в каждом элементе есть указатели на предыдущий и следующий элемент. Методы у него такие же, как у динамического массива, но действия с таким списком различаются сложностью выполнения и скоростью. Методы add() и remove() в связанном списке имеют фиксированную скорость выполнения, поэтому оптимальнее. А вот обращение к элементу по индексу быстрее в ArrayList.
Есть еще две реализации, о которых говорят реже. Это Vector и его потомок Stack. Vector похож на ArrayList, но сейчас им не рекомендуют пользоваться — он синхронизированный, за счет этого более потокобезопасный, но менее производительный. Исключение — редкие ситуации с высокими требованиями к потоковой безопасности.
Stack — это стек, работающий по принципу LIFO (last in, first out). Доступ начинается с того элемента, который добавлен в структуру последним, как взятие верхней карты из колоды. Его же быстрее всего можно удалить. Для просмотра последнего элемента есть метод peek(), для просмотра с удалением — pop(), а для добавления элемента в конец — push().
Set
Set, или набор, — это математическое множество, реализованное в языке программирования. Если проще, это коллекция уникальных значений. Ни одно из них не повторяется в рамках одного сета. Для проверки равенства у такой коллекции есть специальный метод equals().
Коллекция не упорядочена, то есть у ее элементов нет порядковых номеров и четких позиций следования. Это может понадобиться при хранении разных структур данных, например имен пользователей сайта: никнеймы уникальны, а порядковых номеров у них нет.
У Set есть два дочерних интерфейса SortedSet и NavigableSet — соответственно, отсортированный и навигируемый сеты. Фактических реализаций три, и о них стоит поговорить подробнее.
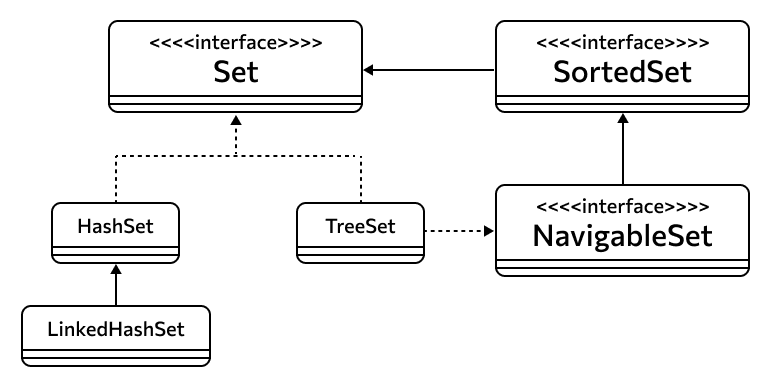
Реализации. Часто используется реализация HashSet — это сет, внутри которого, кроме объектов, находится хэш-таблица для хранения данных. Хэш-таблица реализована с помощью HashMap — одной из реализаций интерфейса Map, о котором мы частично упоминали и подробнее поговорим позже.
Похожая на предыдущую реализация LinkedHashSet — связанный сет, в котором объекты упорядочены. Они хранятся в том же порядке, в котором были добавлены в коллекцию. Внутри для хранения используется объект LinkedHashMap.
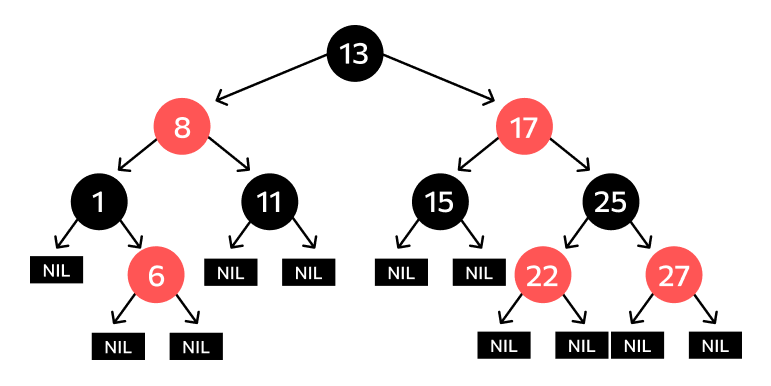
Третий вариант — TreeSet, который хранит свои элементы в виде упорядоченного красно-черного дерева. Дерево — особая структура данных, о которой подробнее можно прочитать в теоретических материалах по информатике или в наших статьях. Оно удобно для хранения разветвленных и иерархически связанных друг с другом данных, а еще в дереве быстрее выполняются операции add(), remove() и contains().
Queue
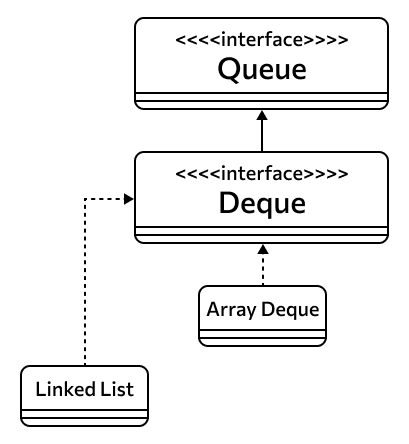
Третий прямой наследник Collection — очередь, или Queue. Очередь и стек — два похожих формата, которые различаются принципом доступа к элементам. Если в стеке мы имеем быстрый доступ к последним добавленным частям, то в очереди — к тем, которые были добавлены первыми. Такой принцип называется FIFO (first in, first out) и действительно напоминает живую очередь. Соответственно, быстро получить и удалить элемент можно из начала очереди, а добавить — только в ее конец.
Доступ к первому элементу можно получить с помощью методов element() и peek(), которые различаются реакцией на вызов для пустой очереди. Удалить первый элемент, предварительно вернув его, можно с помощью методов remove() и poll() — они различаются тем же. Добавить элемент в конец очереди можно через метод offer(item).
Реализации. У Queue две основных реализации. Одна из них — PriorityQueue, прямая реализация, которая по умолчанию сортирует элементы в порядке их появления в очереди. Но это можно переопределить в конструкторе — специальном методе для создания объекта. Там можно задать связь с интерфейсом Comparator, который будет сравнивать элементы очереди и располагать их в зависимости от значений.
Вторая реализация чуть сложнее. У Queue есть потомок под названием Deque (читается как «дек»). Он расширяет Queue и добавляет возможность создавать коллекции, работающие по принципу LIFO — мы говорили о нем выше. По сути, получается двунаправленная очередь. Так вот вторая реализация называется ArrayDeque и технически является реализацией интерфейса Deque, а не Queue. Но Deque — потомок Queue, так что ArrayDeque периодически называют реализацией Queue.
Упомянутый выше LinkedList — реализация, принадлежащая не только List, но и Deque.
Map
Мы поместили описание интерфейса вниз, потому что технически он не относится к иерархии коллекций. Он не является потомком Iterable и, соответственно, Collection, у него нет общих для коллекций методов, это другой вид объекта, и методы у него свои. Но мы решили упомянуть о нем в контексте коллекций, потому что они часто объясняются и используются вместе. При этом Map — другой вид объекта, и принцип построения у него отличается.
Map, «карта», он же «словарь» или ассоциативный массив — это список формата «ключ-значение». Представьте себе таблицу, где данные указаны, например, в таком формате:
Имя: Иван
Фамилия: Иванов
«Имя» и «Фамилия» будут ключами, а «Иван» и «Иванов» — значениями. По такому принципу данные хранятся в Map: вместо индексов у них ключи. Map не итерируется, потому что сложно сказать, какой из ключей можно назвать «первым», а какой «вторым», — это неупорядоченная структура.
Реализации. У Map три непосредственных реализации и один дочерний интерфейс, который в свою очередь имеет свою реализацию. Дочерний интерфейс называется SortedMap, от него наследуется еще один интерфейс NavigableMap, а уже у него есть реализация под названием TreeMap — карта в виде дерева. Выше мы говорили о деревьях в контексте сетов. Структурирование дерева в сете возможно благодаря наличию в объекте элемента TreeMap для хранения позиций.
Непосредственные реализации — это Hashtable, HashMap и WeakHashMap.
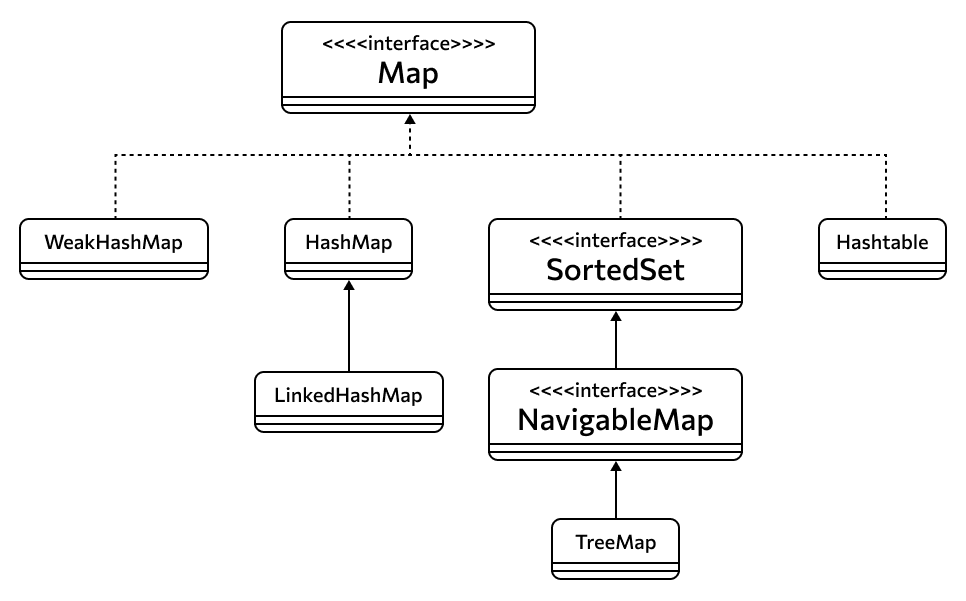
Hashtable — это хэш-таблица: о том, что это такое, мы рассказывали в статье про хэш. Но именно эта реализация сейчас не рекомендована к использованию: она синхронизированная и из-за этого работает медленнее современных методов.
HashMap — более новая альтернатива Hashtable. Она отличается от предыдущей двумя деталями: HashMap не синхронизированная, а еще в ней можно в качестве значения или ключа хранить null — «отсутствие», нулевую или пустую сущность. Эта реализация не отсортирована.
Его потомок LinkedHashMap — это отсортированный словарь. В нем элементы располагаются не случайно, в зависимости от хэша, а в порядке добавления.
Третий вариант — WeakHashMap, вариация, значения которой могут автоматически удалиться сборщиком мусора, если на них никто не ссылается.
Как разобраться с коллекциями
Все вышеперечисленное может сначала показаться сложным: слишком много похожих друг на друга сущностей, которые различаются мелкими деталями. Но это не повод переживать. Сначала запутаться действительно легко, но стоит начать применять эти сущности на практике — и вы разберетесь, чем они различаются и как с ними работать.
Практически все перечисленные структуры оптимальны для конкретных задач и используются тогда, когда их применение выгодно с точки зрения производительности. Это опыт, который нарабатывается и узнается со временем.
Как начать работать с коллекциями
Для работы с коллекциями потребуется установленный язык Java и JDK. Работать лучше в среде программирования, или IDE. Это удобнее, чем писать в консоли или «Блокноте».
Чтобы начать работать с коллекциями, нужно подключить к программе пакет java.util — именно там хранится Java Collection Framework. По умолчанию он не подключен к коду, чтобы сэкономить вычислительные ресурсы на случай, если описанные сущности не понадобятся.

0 комментариев