


Искусственный интеллект становится умнее с каждым днем, но вместе с этим растет и число этических вопросов. Нейросети постоянно вводят нас в заблуждение, нарушают нашу приватность и даже влияют на политические процессы. Вместе с Александром Немальцевым, руководителем группы машинного обучения в VK, разбираемся, как возникают эти проблемы и как их можно решить.
Предвзятость алгоритмов
Нейросети пока не научились мыслить полностью автономно, и собственного «мнения» по каким-либо вопросам у них нет. ИИ обучается на большой базе данных, отобранных специалистом или выгруженных из интернета. Иногда это приводит к тому, что у нейросетей появляются предубеждения и стереотипы.

Попросим ИИ нарисовать нам «профессионала своего дела в офисе». ChatGPT сгенерировал несколько картинок, и на каждой нарисован мужчина — хотя из запроса неочевидно, какого пола должен быть человек.

Такие казусы происходят из-за перекосов в данных, на которых обучается искусственный интеллект. Если в базе данных о профессиях, например, 90% инженеров — это мужчины, а женщины встречаются лишь в 10% случаев, модель начнет «думать», что инженер — это в основном мужчина. В 2018 году исследование показало, что системы распознавания лиц на базе ИИ намного чаще ошибались при распознавании темнокожих женщин — ошибки были в 34,7% случаев, хотя для светлокожих мужчин этот показатель составлял всего 0,8%.
Важно понимать, что разработчики не всегда специально закладывают определенные стереотипы и точки зрения в свои нейросети: часто ИИ самостоятельно учится им на основе тех данных, которые ему «скормили». В конце концов, основная задача языковых моделей (LLM) — максимизировать точность предсказаний, а не учитывать этические вопросы.
Иногда нейросети учат искусственно балансировать данные, чтобы сгенерированный контент не был чересчур стереотипным. Но и тут могут возникнуть проблемы: не так давно Google раскритиковали за то, что их нейросеть Gemini генерировала картинки с чернокожими людьми в нацистской форме.
Чтобы решить проблему предвзятости, разработчики могут пополнять базы данных, корректировать алгоритмы и тестировать модели на стереотипы. Помимо этого, компании могут выкладывать свои базы данных в открытый доступ. Так разработчики смогут завоевать доверие пользователей и получать постоянный фидбэк. Именно это сделали создатели Eleuther AI — их публичный датасет The Pile пользуется большой популярностью.
Ошибки и дезинформация
Еще одна проблема — ИИ зачастую выдают ложную, неполную или противоречивую информацию. Дело в том, что, когда вы задаете нейросети вопрос, она не думает, что «правда», а что «ложь». Она ищет статистически наиболее вероятный ответ, основываясь на всех примерах, которые видела.
Иногда это выливается в неожиданные и даже потенциально вредные результаты. В прошлом году девушка решила пошутить и погуглить, сколько камней в день ей стоит есть. Встроенная в Google нейросеть ответила, что человеку следует есть хотя бы один камень в день. Важно понимать принципы работы ИИ: он не проверяет, съедобен ли камень (такого запроса не было!) — вместо этого он угадывает, каким может быть типичный ответ на поставленный вопрос, и «галлюцинирует» его.
Помимо «галлюцинаций», бывает так, что модель обучают на недостоверных данных и она выдает ошибочные ответы. При этом мониторинг и исправление фейков — небыстрый процесс.

Хотя чаще всего речь идет о случайных ошибках, иногда в нейросети все-таки специально закладывают цензуру — как раз в виде этих «надстроек». Например, недавно пользователи DeepSeek заметили, что чат-бот в моменте редактирует собственные ответы о событиях на площади Тяньаньмэнь.
Профилактика дезинформации все та же: пополнение базы данных, дообучение и открытость. Но вместе с этим пользователь должен знать, как работают нейросети, самостоятельно проверять информацию и решать, что с ней делать. В 2023 году адвокат из Нью-Йорка чуть не лишился карьеры, когда в суде обнаружили, что в его юридическом расследовании были несуществующие ссылки и цитаты от ChatGPT.
Как ИИ влияет на экологию
Искусственный интеллект — это не только миллионы строк кода, но и тонны углекислого газа. Обучение одной крупной языковой модели (LLM) вроде GPT-4 требует столько же энергии, сколько потребляет небольшой город за несколько месяцев. Дата-центрам, которые обслуживают нейросети, нужно огромное количество воды для охлаждения серверов.
В 2023 году исследование показало, что всего один запрос в ChatGPT тратит примерно 500 мл воды. Если сложить миллионы запросов пользователей, то получится огромная нагрузка на водные ресурсы. Например, дата-центры Microsoft, где работают модели OpenAI, за год потребили на 34% больше воды, чем годом ранее.
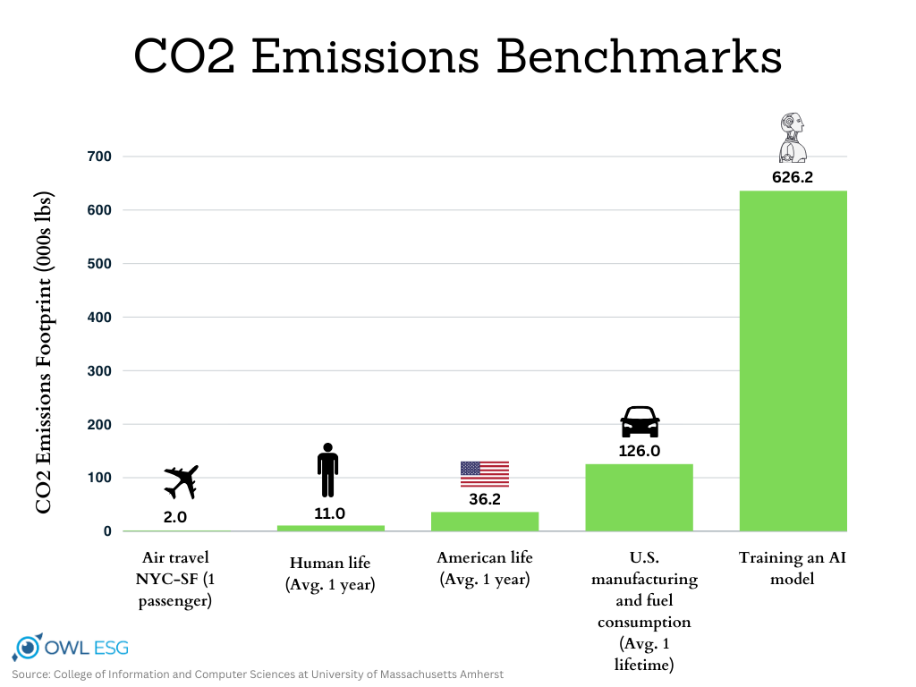
Сейчас Google разрабатывает системы охлаждения, которые требуют меньше воды, а эксперты обсуждают выбросы CO₂ дата-центров и налоги на их энергоемкость. Однако спрос на ИИ растет быстрее, чем появляются экологичные решения, — в конечном счете все решает экономическая выгода.
Конфиденциальность данных
Искусственный интеллект зачастую работает на данных людей, которые им пользуются. Проблема в том, что не всегда понятно, как и где эти данные хранятся, кто имеет к ним доступ и для каких целей они могут быть использованы.
Один из самых громких скандалов произошел в 2019 году, когда Amazon признался, что их умная колонка Alexa записывала разговоры пользователей и хранила их на своих серверах. Более того, компания нанимала сотрудников для анализа этих записей. Подобные случаи были и у других технологических гигантов вроде Google и Apple.
Не обходится и без сливов данных. В 2023 у ChatGPT произошел сбой, из-за которого некоторые пользователи могли просматривать чужие личные данные и переписки с чат-ботом.
Компании должны честно рассказывать, какие данные они собирают и зачем. Прозрачность — это открытые отчеты, аудиты и строгие меры защиты от утечек. Помогают и законодательные меры: в Европе действует регламент GDPR, который требует согласия пользователей на любую обработку данных.
Помимо этого, в мире существует много «теневых ИИ», которые используются в незаконных целях: например, для создания дипфейков. Бороться с ними пока что сложно.
Важно понимать, что защита данных — задача не только компаний. Пользователи тоже должны быть внимательными: читайте, что собирает приложение, отключайте ненужные функции и уж точно не скидывайте чат-ботам скан своего паспорта.

ИИ в политике
Искусственный интеллект все чаще применяют в политике — и не всегда в позитивном ключе. Вот лишь несколько примеров:
- Во время праймериз в одном из американских штатов избиратели получили звонки с голосом, имитирующим Джо Байдена. AI призывал их не голосовать, что привело к расследованию и крупному штрафу для организаторов.
- В Индии партия BJP активно использовала дипфейки для предвыборной агитации. Хотя крупные соцсети обязывают авторов предупреждать о дипфейках в постах, часто люди просто не обращают внимание на эти плашки — а контент становится все реалистичнее.
- Исследователи постоянно находят политические наклонности у всех чат-ботов — потенциально это может даже повлиять на исход выборов.
С другой стороны, ИИ может помочь политикам эффективнее следить за общественным мнением и прогнозировать его. Уже сейчас партии используют AI, чтобы быстро менять предвыборные стратегии, а в будущем технологии могут помочь бороться с фейками и сделать выборы прозрачнее. Но остается вопрос о том, кто будет контролировать эти системы и насколько общество будет доверять им.
ИИ и искусство
Генеративные модели обучаются на огромных массивах данных, включая музыку, тексты, изображения. Однако не всегда ясно, нарушают ли они авторское право — и можно ли считать AI-контент искусством.
В 2023 году три художницы — Сара Андерсен, Келли МакКернан и Карла Ортис — подали коллективный иск против Stability AI, Midjourney и DeviantArt. Они утверждают, что компании обучали нейросети на пяти миллиардах изображений без разрешения авторов, и считают ИИ угрозой для сферы искусства.

Судебный процесс все еще идет, и его исход может стать важным прецедентом. Дело в том, что в большинстве стран пока нет законов, регулирующих ИИ. В США разработчики ссылаются на доктрину о «добросовестном использовании»: она позволяет в некоторых случаях использовать материалы, защищенные авторским правом, без ведома создателя. Например, в целях образования или критики.
Многие деятели искусства жалуются на то, что генеративные нейросети обесценивают их труд. Впрочем, исследователи считают, что нейросети могут автоматизировать только 26% задач профессиональных художников и дизайнеров. А вопрос о том, можно ли считать AI-контент искусством, остается дискуссионным: пока что он очень однотипный и неточный. Ну и как такового «креатива» у ИИ нет: он просто комбинирует уже существующие стили и образы из базы данных.
ИИ и юридическая ответственность
Сейчас технологии AI развиваются быстрее, чем законы и нормы, которые могли бы их контролировать. В итоге мы получаем правовой вакуум, где компании всячески экспериментируют с нейросетями без учета последствий.
Например, нейросеть может отказать человеку в кредите или визе без видимой причины, и обжаловать такое решение почти невозможно из-за отсутствия четких правил. А в некоторых случаях цена ошибки может быть слишком высока: например, в медицине или в военной сфере.
Слепое доверие ИИ уже приводило к фатальным случаям. В 2018 году семья Уолтера Хуана подала в суд на компанию Tesla: Уолтер насмерть разбился в ДТП, пока машина ехала в режиме автопилота. Семья настаивает на том, что авария произошла из-за ошибок в алгоритме, а представители Tesla утверждают, что их система неоднократно предупреждала водителя об опасности.
Эта история подняла вопрос о том, кто в таких случаях должен нести ответственность: пользователь или разработчики алгоритма. Именно поэтому компании стали писать четкие пользовательские соглашения и внутренние рабочие регламенты, а многие страны начали думать о разработке специальных законов, связанных с ИИ.
Коротко о главном
Сам по себе искусственный интеллект — нейтральный инструмент, который можно обучать и использовать по-разному. Чаще всего этические проблемы возникают там, где появляется человеческий фактор: например, человек недостаточно контролировал ИИ или обучил его на неправильных данных. Помимо этого, мы пока что не научились регулировать ИИ на уровне закона — поэтому возникают юридически и морально спорные моменты.