
Apache Kafka — распределенная система обмена сообщениями между серверными приложениями в режиме реального времени. Благодаря высокой пропускной способности, масштабируемости и надежности применяется в компаниях, работающих с большими объемами данных. Написана на языках Java и Scala.

Kafka разработана компанией LinkedIn. В 2011 году разработчик опубликовал исходный код системы. С тех пор платформа развивается и поддерживается как открытый проект в рамках фонда Apache Software Foundation. Apache Kafka используют многие крупные компании, такие как LinkedIn, Microsoft, The New York Times, Netflix и другие.


Применение Kafka Apache
Kafka Apache — эффективный инструмент для организации работы серверных проектов любого уровня. Благодаря гибкости, масштабируемости и отказоустойчивости используется в различных направлениях IT-индустрии, от сервисов потоковых видео до аналитики Big Data.
- Для связи микросервисов. Kafka — связующее звено между отдельными функциональными модулями большой системы. Например, с ее помощью можно подписать микросервис на другие компоненты для регулярного получения обновлений.
- Потоковая передача данных. Высокая пропускная способность системы позволяет поддерживать непрерывные потоки информации. За счет грамотной маршрутизации «Кафка» не только надежно передает данные, но и позволяет производить с ними различные операции.
- Ведение журнала событий. Kafka сохраняет данные в строго организованную структуру, в которой всегда можно отследить, когда произошло то или иное событие. Информация хранится в течение заданного промежутка времени, что можно использовать для разгрузки базы данных или медленно работающих систем логирования.
Как устроена и работает Kafka Apache
Кратко архитектуру системы сообщений можно охарактеризовать следующим образом:
- распределенность — отдельные узлы системы располагаются на нескольких аппаратных платформах (кластерах). Это обеспечивает ей высокую отказоустойчивость;
- масштабируемость — систему можно наращивать за счет простого добавления новых узлов (брокеров сообщений).
В архитектуре Kafka Apache ключевыми являются концепции:
- продюсер (producer) — приложение или процесс, генерирующий и посылающий данные (публикующий сообщение);
- потребитель (consumer) — приложение или процесс, который принимает сгенерированное продюсером сообщение;
- сообщение — пакет данных, необходимый для совершения какой-либо операции (например, авторизации, оформления покупки или подписки);
- брокер — узел (диспетчер) передачи сообщения от процесса-продюсера приложению-потребителю;
- топик (тема) — виртуальное хранилище сообщений (журнал записей) одинакового или похожего содержания, из которого приложение-потребитель извлекает необходимую ему информацию.
В упрощенном виде работа Kafka Apache выглядит следующим образом:
- Приложение-продюсер создает сообщение и отправляет его на узел Kafka.
- Брокер сохраняет сообщение в топике, на который подписаны приложения-потребители.
- Потребитель при необходимости делает запрос в топик и получает из него нужные данные.
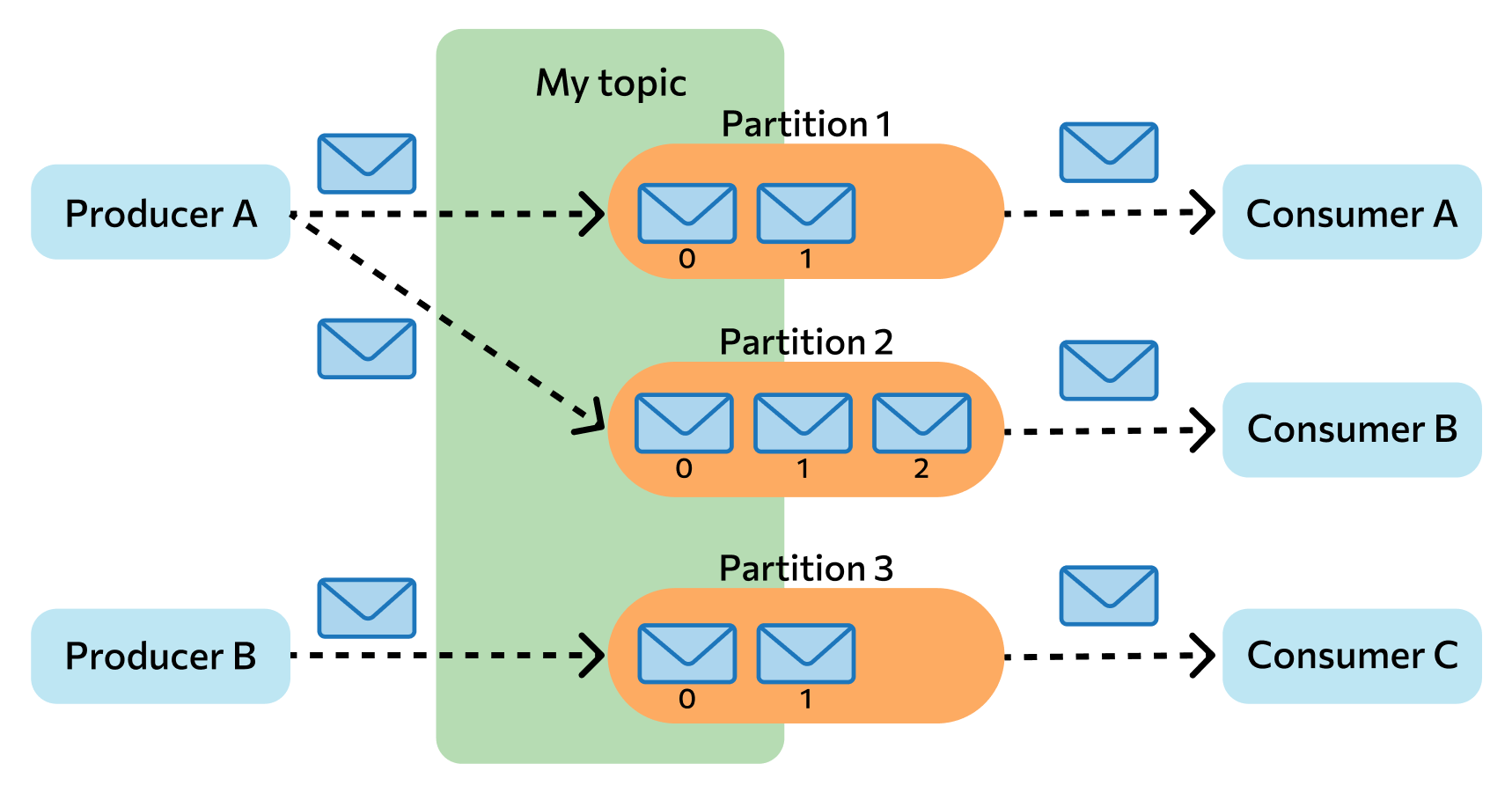
Сообщения хранятся в Kafka в виде журнала коммитов — записей, размещенных в строгой последовательности. Их можно только добавлять. Удалять или корректировать нельзя. Сообщения хранятся в той последовательности, в которой поступили, их считывание ведется слева направо, а отслеживание — по изменению порядкового номера. Брокеры Kafka не обрабатывают записи — только помещают их в тему на кластере. Хранение может длиться в течение определенного периода или до достижения заданного порога.

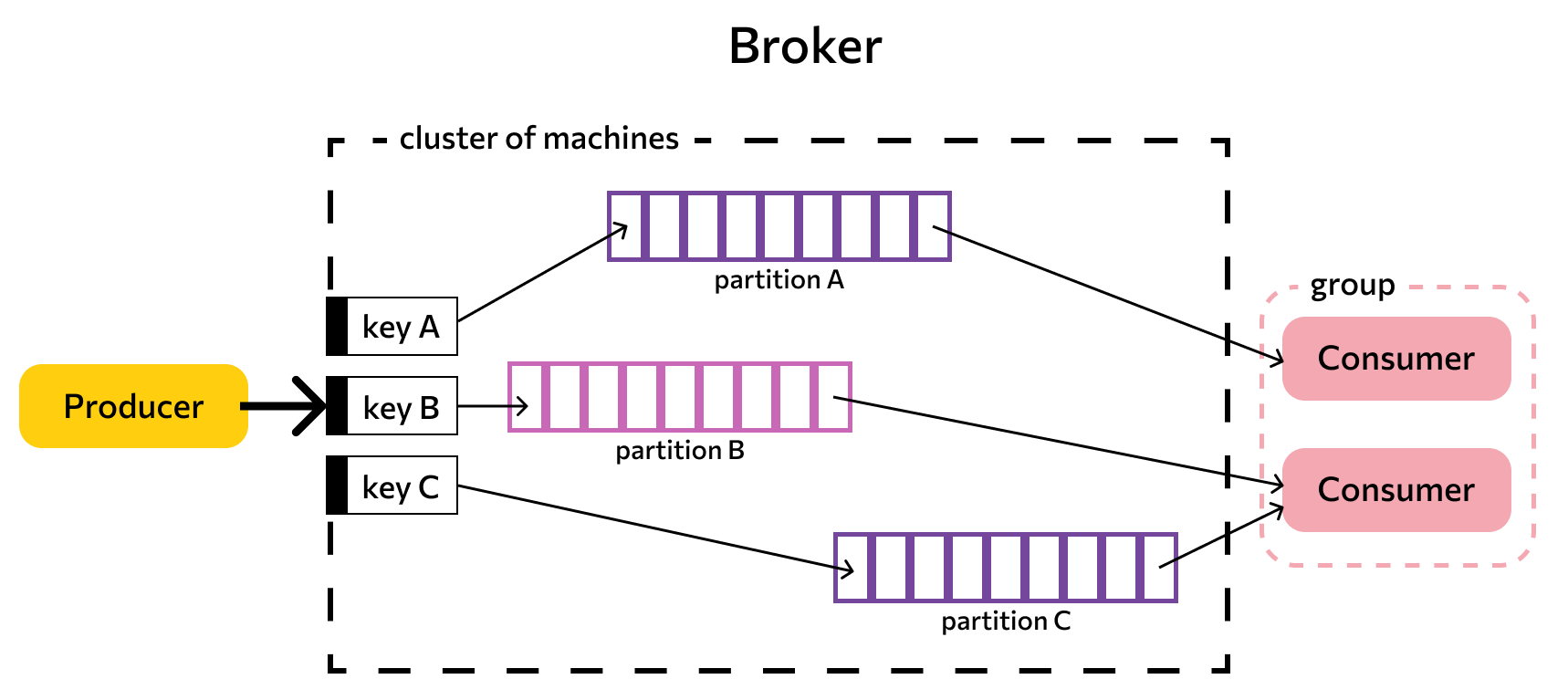
Если тема слишком разрастается, для упрощения и ускорения процесса она разделяется на секции. Каждая секция содержит сообщения, сгруппированные по объединяющему признаку. Например, массив пользовательских запросов можно сгруппировать по первой букве имени пользователей. Так приложению-потребителю не придется просматривать весь топик — только нужную тему, что ускоряет процесс обмена сообщениями.
Преимущества Kafka
Отказоустойчивость
Kafka — распределенная система обмена сообщениями, узлы которой содержатся на нескольких кластерах. Принимая сообщение от продюсера, она реплицирует (копирует) его, а копии сохраняет на разных узлах. При этом один из брокеров назначается ведущим в секции, через него потребители будут обращаться к записям. Другие брокеры остаются ведомыми, их главная задача — обеспечить сохранность сообщения (его копий) даже при выходе одного или нескольких узлов из строя. Распределенный характер и механизм репликации записей обеспечивают системе высокую устойчивость. Надежность повышает интеграция с Apache ZooKeeper, которая обеспечивает координацию компонентов друг с другом.
Масштабируемость
Apache Kafka поддерживает «горячее» расширение, то есть ее можно увеличивать с помощью простого добавления новых машин в кластеры, не отключая всю систему. Так исключаются простои, связанные с переоборудованием серверных мощностей. Принцип удобнее горизонтального масштабирования, при котором на одну серверную машину «навешиваются» дополнительные ресурсы: жесткие диски, CPU, RAM и т.д. При необходимости систему можно легко сократить, исключив лишние машины из кластера.
Производительность
В Kafka процессы генерирования/отправки и считывания сообщений организованы независимо друг от друга. Тысячи приложений, процессов могут одновременно и параллельно играть роль генераторов и потребителей сообщений. В сочетании с распределенным характером и масштабируемостью это позволяет применять «Кафка» как в небольших, так и в масштабных проектах с большими объемами данных.
Открытый исходный код
Kafka распространяется по свободной лицензии фонда Apache Software Foundation. Благодаря этому Kafka Apache имеет ряд преимуществ:
- большой объем подробной справочной информации от официальных разработчиков, а также различных мануалов, лайфхаков, инструкций и обзоров от большого числа энтузиастов-любителей и профессионалов;
- большое количество дополнительных программных пакетов, патчей от сторонних разработчиков, расширяющих и улучшающих базовый функционал системы;
- возможность самостоятельно адаптировать систему под специфику проекта за счет гибкости настроек.
Безопасность
В Kafka есть инструменты, обеспечивающие безопасную работу и достоверность данных. Например, настроив уровень изоляции для транзакций, можно исключить чтение незавершенных или отмененных сообщений. Кроме того, благодаря сохранению данных в топиках пользователь может в любой момент отследить изменения в системе. А принцип последовательной записи позволяет быстро находить нужные сообщения.
Долговечность
Данные в Kafka сохраняются в долговременные виртуальные хранилища в течение заданного периода времени (дней, недель, месяцев). За счет распределенного хранения информации она не потеряется при сбое одного или нескольких узлов, и потребитель сможет в любой момент обратиться к нужному сообщению в топике, отследив его смещение.
Интегрируемость
Благодаря собственному протоколу на базе TCP «Кафка Апач» взаимодействует с другими протоколами передачи данных (REST, HTTP, XMPP, STOMP, AMQP, MQTT). Встроенный фреймворк Kafka Connect позволяет Kafka подключаться к базам данных, файловым и облачным хранилищам.
Единственный заметный недостаток системы — ориентированность на обработку больших объемов данных. Из-за этого функционал маршрутизации потоков ограничен по сравнению с другими аналогичными платформами. По мере развития Kafka это различие становится менее заметным, а сама система — более гибкой и универсальной.

0 комментариев