


Получать предсказуемые результаты при обучении моделей, легко увеличивать объемы данных и адаптировать к процессам новых членов команды — для этого нужны четкая структура, последовательность действий и набор инструментов. Все вместе это называется пайплайн. Разбираемся, из чего он состоит и как его построить.
Что такое ML-пайплайн и зачем он нужен
Представьте, что вы шеф-повар на большой кухне. Чтобы приготовить сложное блюдо (скажем, вашу ML-модель), вам нужно последовательно выполнить много операций: достать ингредиенты (данные), помыть и нарезать их (предобработка), смешать в нужных пропорциях (инжиниринг признаков), поставить в духовку на определенное время (обучение модели), а потом попробовать, что получилось (валидация).

ML-пайплайн — это ваш автоматизированный кухонный конвейер. Это последовательность шагов, которые преобразуют сырые данные в готовую к использованию модель машинного обучения, а иногда и дальше — до ее развертывания и мониторинга.
Зачем он нужен?
- Воспроизводимость. Вы всегда получите тот же результат при тех же входных данных и настройках. Больше никаких «а у меня на компьютере все работало!».
- Эффективность. Автоматизация рутинных задач экономит кучу времени.
- Масштабируемость. Легче переходить от экспериментов на маленьких данных к работе с большими объемами.
- Надежность. Меньше шансов на ошибку из-за человеческого фактора.
- Командная работа. Четко определенные шаги упрощают совместную работу над проектом.
В машинном обучении автоматизация — это необходимость. Она обеспечивает:
- Скорость итераций. Хотите попробовать новую фичу? Или другой алгоритм? С пайплайном это делается изменением одного-двух блоков, а не переписыванием всего кода с нуля.
- Снижение ошибок. Ручное выполнение каждого шага — прямой путь к ошибкам. Забыли применить ту же обработку к тестовым данным, что и к тренировочным? Пайплайн этого не допустит.
- Упрощение поддержки. Когда модель уже работает в продакшене, ее нужно периодически переобучать на новых данных. Автоматизированный пайплайн делает этот процесс почти незаметным.
- Стандартизация. Пайплайны помогают внедрить единые стандарты разработки ML-решений в команде или даже целой компании.
Обзор этапов ML-пайплайна
Давайте разберем типичный ML-пайплайн на составные части. Это как рецепт нашего «блюда».
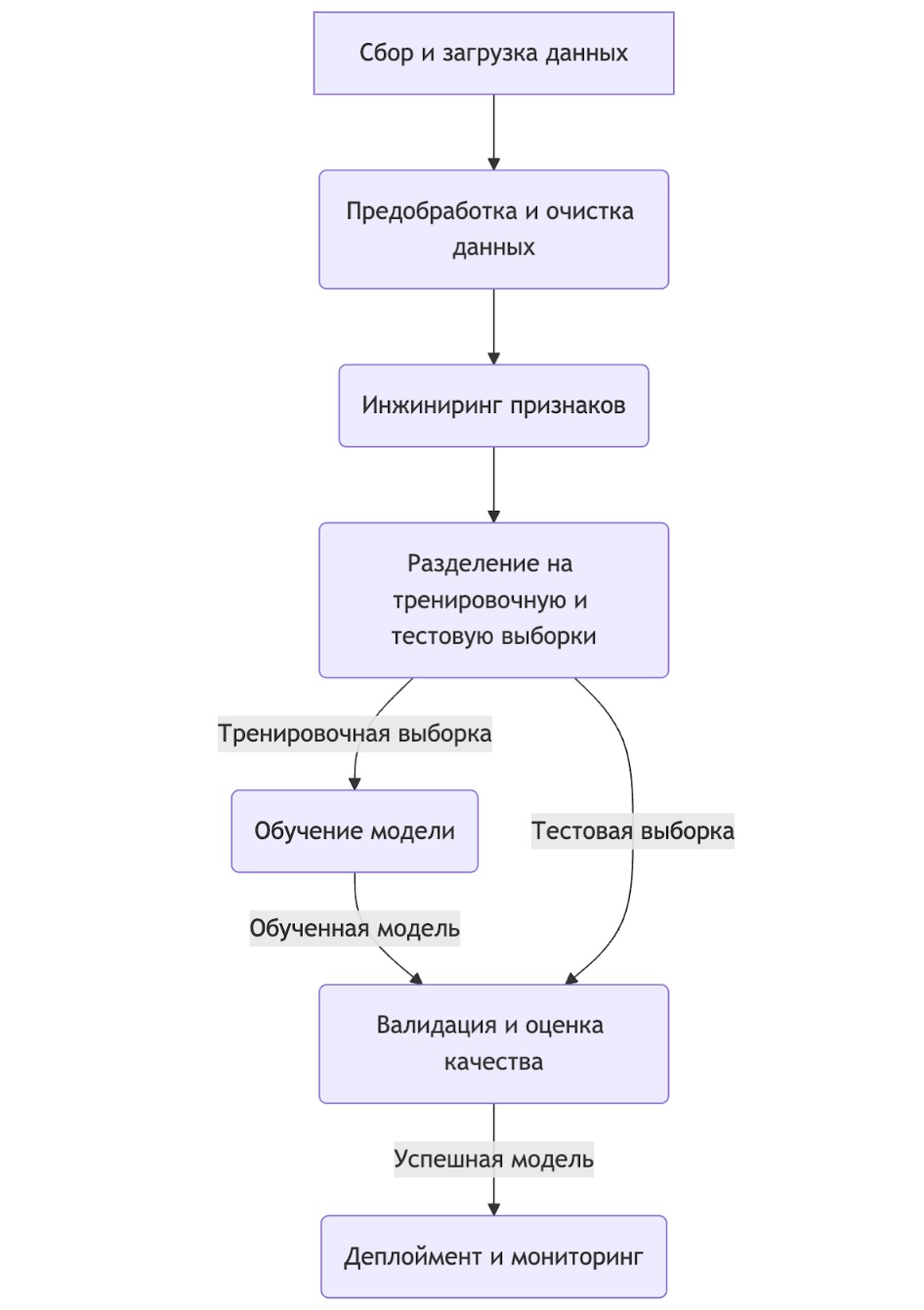
Сбор и загрузка данных
Все начинается с данных. Это могут быть CSV-файлы, базы данных, API, логи веб-серверов — что угодно. На этом этапе мы определяем источники, пишем код для извлечения (Extract) и загрузки (Load) данных в нашу рабочую среду. Часто это часть более крупного ETL- (Extract, Transform, Load) или ELT-процесса.
Предобработка и очистка данных
Сырые данные почти никогда не бывают идеальными. Они могут содержать:
- Пропуски: отсутствующие значения. Их нужно либо удалить, либо заполнить (импутировать) — средним, медианой, модой или более сложными методами.
- Выбросы: аномально большие или маленькие значения. Их нужно идентифицировать и решить, что с ними делать (удалить, скорректировать).
- Шум: случайные погрешности.
- Некорректный формат: даты в виде строк, числа как текст и т. д.
- Категориальные признаки: текстовые метки, которые модели не понимают. Их нужно преобразовать в числа (например, One-Hot Encoding, Label Encoding).
Этот этап критически важен. Как говорится, «мусор на входе — мусор на выходе» (Garbage In, Garbage Out).
Инжиниринг признаков (feature engineering)
Это настоящее искусство и наука одновременно! Нужно создать новые, более информативные признаки из существующих. Это может быть:
- комбинирование признаков (например, отношение ширины к высоте);
- извлечение информации (например, день недели из даты);
- агрегация (например, средняя сумма покупки клиента за последний месяц);
- масштабирование (например, StandardScaler, MinMaxScaler), чтобы признаки с большими значениями не «забивали» признаки с маленькими.
Хороший инжиниринг признаков часто дает больший прирост качества модели, чем выбор самого навороченного алгоритма.
Разделение на тренировочную и тестовую выборки
Прежде чем обучать модель, данные нужно разделить как минимум на две части:
- Тренировочная выборка (train set): на ней модель будет учиться.
- Тестовая выборка (test set): на ней мы будем проверять, насколько хорошо модель обобщает знания на не виденных ранее данных. Это как экзамен для студента.
Важно! Тестовую выборку откладываем в сторону и не используем ни на одном из предыдущих этапов (особенно при масштабировании или заполнении пропусков), чтобы избежать утечки данных (data leakage). Иногда еще выделяют валидационную выборку (validation set) или используют кросс-валидацию (CV) для подбора гиперпараметров модели.
Обучение модели
На этом этапе мы выбираем алгоритм машинного обучения (например, логистическую регрессию, случайный лес, градиентный бустинг, нейронную сеть) и «скармливаем» ему тренировочные данные. Модель ищет закономерности в данных, чтобы научиться делать предсказания. Сюда же входит подбор гиперпараметров модели — это настройки самого алгоритма, которые не выучиваются из данных напрямую (например, количество деревьев в случайном лесу).
Валидация и оценка качества
После обучения модель нужно оценить. Для этого мы используем тестовую выборку и специальные метрики (accuracy, precision, recall, F1-score для классификации; MSE, MAE, R² для регрессии и т. д.). Если есть валидационная выборка, она используется для подбора гиперпараметров, а финальная оценка — строго на тестовой. Часто используется кросс-валидация на тренировочных данных для более робастной оценки и подбора гиперпараметров.
Деплоймент и мониторинг
Если модель показала хорошее качество, ее можно «выкатывать в бой» — то есть разворачивать (deploy) в реальной системе, где она будет приносить пользу. Это может быть:
- REST API сервис;
- интеграция в существующее приложение;
- пакетная обработка данных по расписанию.
После деплоя работа не заканчивается! Нужен мониторинг:
- Качество предсказаний: не упало ли оно со временем (model drift)?
- Характеристики входных данных: не изменились ли они (data drift)?
- Технические метрики: нагрузка, время ответа.
При необходимости модель нужно переобучать на свежих данных.

Инструменты и фреймворки ML-пайплайна
Строить пайплайны «руками» можно — но зачем, если есть удобные инструменты?
Scikit-learn Pipeline API
Для многих задач, особенно на этапе экспериментов и когда весь процесс умещается в одном скрипте, Pipeline из scikit-learn — идеальный выбор.
Основы работы с классом Pipeline. Класс Pipeline позволяет объединить несколько шагов обработки данных и модель в единый объект. Каждый шаг, кроме последнего, должен быть трансформером (иметь методы fit и transform), а последний шаг — оценщиком (estimator, иметь метод fit и, например, predict или transform).
Комбинирование трансформеров и оценщиков.Вы просто передаете в конструктор Pipeline список кортежей (имя_шага, объект_шага). Например:
- Заполнение пропусков (SimpleImputer).
- Масштабирование (StandardScaler).
- Обучение классификатора (LogisticRegression).
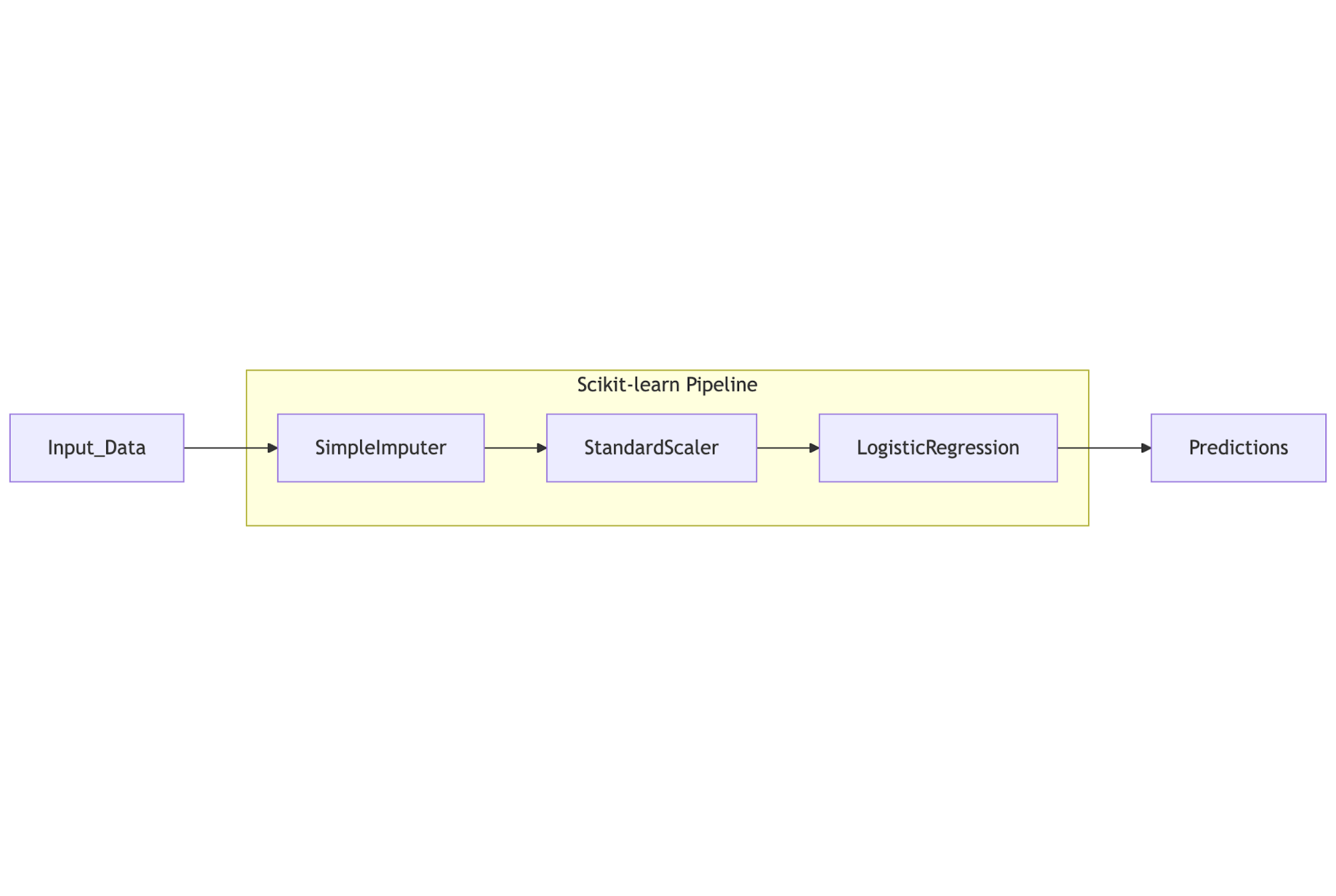
Пример простого пайплайна для классификации (псевдокод, иллюстрирующий идею)
from sklearn.pipeline import Pipeline
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.compose import ColumnTransformer
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
import pandas as pd
import numpy as np
# Допустим, у нас есть DataFrame df с числовыми и категориальными признаками
# X = df.drop('target', axis=1)
# y = df['target']
# X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# Определяем числовые и категориальные колонки (пример)
numeric_features = ['age', 'income']
categorical_features = ['gender', 'city']
# Создаем трансформеры для каждого типа колонок
numeric_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='median')),
('scaler', StandardScaler())
])
categorical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='most_frequent')),
('onehot', OneHotEncoder(handle_unknown='ignore'))
])
# Объединяем трансформеры с помощью ColumnTransformer
preprocessor = ColumnTransformer(
transformers=[
('num', numeric_transformer, numeric_features),
('cat', categorical_transformer, categorical_features)
])
# Создаем итоговый пайплайн с моделью
model_pipeline = Pipeline(steps=[
('preprocessor', preprocessor),
('classifier', LogisticRegression())
])
# Обучаем весь пайплайн
# model_pipeline.fit(X_train, y_train)
# Делаем предсказания
# predictions = model_pipeline.predict(X_test)
# Оцениваем
# score = model_pipeline.score(X_test, y_test)
Прелесть в том, что fit вызовет fit_transform для всех шагов препроцессинга и fit для модели. А predict вызовет transform для препроцессоров и predict для модели. Это защищает от утечки данных при кросс-валидации или поиске по сетке (GridSearchCV).
Apache Airflow
Когда ваш ML-проект становится сложнее, включает множество скриптов, зависит от внешних систем или требует регулярного выполнения по расписанию, на помощь приходит Apache Airflow. Это платформа для программного создания, планирования и мониторинга рабочих процессов.
Архитектура DAG. В Airflow рабочие процессы описываются как DAG (Directed Acyclic Graph) — направленный ациклический граф. Каждый узел в графе — это Task (задача), а ребра определяют зависимости между задачами (какая задача должна выполниться после какой).
Создание тасков и операторов. Задачи (Tasks) в Airflow создают с помощью операторов. Есть множество готовых операторов:
- BashOperator: для выполнения bash-команд;
- PythonOperator: для выполнения Python-функций;
- DockerOperator: для запуска задач в Docker-контейнерах;
- операторы для работы с базами данных (PostgresOperator, MySqlOperator), облачными сервисами (S3FileTransformOperator, GCSToBigQueryOperator) и многое другое.
Вы просто описываете свой DAG на Python.
Организация ETL-процессов в ML-контексте. Airflow отлично подходит для организации ETL-процессов, которые часто предшествуют обучению модели. Например:
- Task 1 (Extract): Забрать данные из продакшн-базы (используя PostgresOperator).
- Task 2 (Transform): Обработать и очистить их Python-скриптом (используя PythonOperator или DockerOperator).
- Task 3 (Load): Загрузить подготовленные данные в хранилище (например, S3, используя S3Hook внутри PythonOperator, или специальный оператор).
- Task 4 (Train): Запустить скрипт обучения модели на этих данных.
- Task 5 (Deploy): Если модель хороша, обновить ее в API.
Пример автоматизации обучения и деплоймента. Представьте DAG, который запускается каждый понедельник:
- Забирает свежие данные за неделю.
- Переобучает модель.
- Если новая модель лучше старой (по метрикам на отложенной выборке), то она автоматически загружается в сервис, который отдает предсказания.
- Отправляет отчет о результатах на почту.
Это уже полноценный MLOps!
Практическое руководство по ML-пайплайну с кодом
Давайте набросаем небольшой пример, как это могло бы выглядеть на практике. Полный код был бы слишком объемным, так что сосредоточимся на ключевых моментах.
Подготовка окружения и зависимостей
Обычно это requirements.txt или environment.yml (для Conda).
# requirements.txt pandas numpy scikit-learn flask # для простого API joblib # для сохранения модели
И создаем виртуальное окружение:
python -m venv .venv source .venv/bin/activate # для Linux/macOS # .venv\Scripts\activate # для Windows pip install -r requirements.txt
Реализация Scikit-learn Pipeline
Чтение и предварительный анализ данных
import pandas as pd
from sklearn.model_selection import train_test_split
# Загрузка данных (пример)
# df = pd.read_csv('your_data.csv')
# Простой анализ:
# print(df.head())
# print(df.info())
# print(df.describe())
# print(df.isnull().sum()) # Проверка пропусков
# Отделяем признаки и таргет
# X = df.drop('target_column', axis=1)
# y = df['target_column']
# Разделение на трейн и тест
# X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
Создание собственного трансформера. Иногда стандартных трансформеров не хватает, Scikit-learn позволяет легко создавать свои.
from sklearn.base import BaseEstimator, TransformerMixin import numpy as np class FeatureAdder(BaseEstimator, TransformerMixin): def __init__(self, feature1_col, feature2_col, new_feature_name): self.feature1_col = feature1_col self.feature2_col = feature2_col self.new_feature_name = new_feature_name def fit(self, X, y=None): return self # ничего не учим def transform(self, X): X_copy = X.copy() # Пример: создаем новый признак как сумму двух существующих X_copy[self.new_feature_name] = X_copy[self.feature1_col] + X_copy[self.feature2_col] return X_copy # Использование: # adder = FeatureAdder(feature1_col='col_A', feature2_col='col_B', new_feature_name='col_A_plus_B') # X_train_transformed = adder.transform(X_train)
Построение полного пайплайна и подбор гиперпараметров. Используем Pipeline и ColumnTransformer из примера 3.1.3, добавив наш кастомный трансформер, если нужно, и GridSearchCV для подбора гиперпараметров.
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.impute import SimpleImputer
from sklearn.compose import ColumnTransformer
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import GridSearchCV
# ... (определение numeric_features, categorical_features, X_train, y_train как раньше) ...
# Создаем препроцессор
numeric_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='median')),
('scaler', StandardScaler())])
categorical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='constant', fill_value='missing')),
('onehot', OneHotEncoder(handle_unknown='ignore'))])
preprocessor = ColumnTransformer(
transformers=[
('num', numeric_transformer, numeric_features),
('cat', categorical_transformer, categorical_features)
# Можно добавить ('custom_adder', FeatureAdder(...), ['col_A', 'col_B'])
],
remainder='passthrough' # Оставить остальные колонки как есть (если есть)
)
# Создаем пайплайн с моделью
full_pipeline = Pipeline(steps=[
('preprocessor', preprocessor),
# ('custom_features', FeatureAdder(...)) # Если трансформер работает на всех данных после препроцессора
('classifier', RandomForestClassifier(random_state=42))
])
# Задаем сетку параметров для GridSearchCV
param_grid = {
'classifier__n_estimators': [100, 200],
'classifier__max_depth': [None, 10, 20],
# 'preprocessor__num__imputer__strategy': ['mean', 'median'] # Можно тюнить и параметры препроцессоров!
}
# Ищем лучшие параметры
# grid_search = GridSearchCV(full_pipeline, param_grid, cv=5, scoring='accuracy', n_jobs=-1)
# grid_search.fit(X_train, y_train)
# print(f"Лучшие параметры: {grid_search.best_params_}")
# print(f"Лучший CV score: {grid_search.best_score_}")
# Лучшая модель уже обучена и доступна как grid_search.best_estimator_
# best_model = grid_search.best_estimator_
Деплоймент в продакшн
Сериализация модели (pickle, joblib, ONNX). Обученную модель (весь пайплайн!) нужно сохранить, чтобы потом использовать.
- pickle: стандартный модуль Python для сериализации объектов.
- joblib: оптимизирован для больших NumPy-массивов, часто используется в scikit-learn.
- import joblib
# joblib.dump(best_model, ‘my_model_pipeline.joblib’)
# loaded_model = joblib.load(‘my_model_pipeline.joblib’) - ONNX (Open Neural Network Exchange): формат для представления ML-моделей, позволяет переносить модели между разными фреймворками (например, из PyTorch в TensorFlow Lite). Более сложен в настройке для классических ML-моделей, но очень мощный.
Разворачивание как REST-сервис (Flask/FastAPI).Самый частый способ сделать модель доступной — обернуть ее в простой веб-сервис. Вот минимальный пример на Flask:
from flask import Flask, request, jsonify
import joblib
import pandas as pd # Предполагаем, что модель ожидает DataFrame
app = Flask(__name__)
# Загружаем модель при старте приложения
model = joblib.load('my_model_pipeline.joblib')
@app.route('/predict', methods=['POST'])
def predict():
try:
data = request.get_json(force=True)
# Преобразуем входные данные в формат, который ожидает модель
# Это может быть DataFrame, numpy array и т. д.
# Важно, чтобы имена колонок и их порядок соответствовали тем, на которых обучалась модель
# Пример: если на вход приходит словарь { "feature1": val1, "feature2": val2 }
df_to_predict = pd.DataFrame([data])
prediction = model.predict(df_to_predict)
# Если модель возвращает numpy array, его нужно конвертировать в list для JSON
return jsonify({'prediction': prediction.tolist()})
except Exception as e:
return jsonify({'error': str(e)}), 400
if __name__ == '__main__':
app.run(port=5000, debug=True) # debug=True только для разработки!
FastAPI — более современная альтернатива Flask, с автоматической валидацией данных (Pydantic) и генерацией документации OpenAPI (Swagger). Рекомендую присмотреться!
Настройка мониторинга и логирования
- Логирование: добавьте логи в ваш API (входящие запросы, предсказания, ошибки). Используйте стандартный модуль logging.
- Мониторинг производительности: инструменты вроде Prometheus + Grafana для отслеживания времени ответа, количества запросов, ошибок HTTP.
- Мониторинг качества модели:
- Data Drift: сохраняйте статистику входящих данных (среднее, медиана, распределение). Если они сильно меняются — модель может начать деградировать.
- Concept Drift / Model Drift: если у вас есть возможность получать истинные метки для сделанных предсказаний (пусть и с задержкой), регулярно пересчитывайте метрики качества модели.
- Специализированные инструменты: Evidently AI, WhyLabs, Arize.
Частые ошибки в ML-пайплайне и как их предотвратить
Неправильная обработка пропусков и выбросов
Ошибка: заполнять пропуски средним по всему датасету до разделения на train/test. Это утечка информации из теста в трейн.
Совет: все шаги предобработки (импутация, масштабирование) должны «обучаться» только на X_train и затем применяться к X_train и X_test. Scikit-learn Pipeline делает это автоматически.
Утечка данных (data leakage)
Ошибка: использование информации, которая не будет доступна на момент предсказания в реальных условиях. Например, использование признаков, вычисленных на основе целевой переменной, или применение PCA ко всему датасету перед разделением.
Совет: тщательно анализируйте каждый признак. Всегда откладывайте тестовую выборку и не «подглядывайте» в нее.
Неоптимальная организация DAG в Airflow
Ошибка: слишком большие, монолитные таски. Или, наоборот, слишком много мелких тасков с ненужными зависимостями.
Совет: делайте таски атомарными и идемпотентными (повторный запуск с теми же входными данными дает тот же результат). Группируйте логически связанные операции. Используйте TaskGroups для визуальной организации.
Проблемы с масштабированием и производительностью
Ошибка: пайплайн хорошо работает на 1000 строк, но «умирает» на миллионе.
Совет: продумывайте масштабирование заранее. Используйте эффективные структуры данных (Pandas DataFrame не всегда лучший выбор для очень больших данных, смотрите в сторону Dask, Spark). Оптимизируйте узкие места. Для Airflow — используйте более мощные воркеры, CeleryExecutor/KubernetesExecutor.
Отсутствие контроля версий данных и моделей:
Ошибка: «Ой, а на каких данных обучалась эта модель? А какая версия кода ее создала?»
Совет: Git — для кода. Для данных — DVC (Data Version Control) или просто четкая система именования и хранения датасетов. Для моделей — MLflow Model Registry, или опять же DVC, или просто версионирование файлов моделей с метаданными.
Лучшие практики и рекомендации
Модульность и повторное использование компонентов
- Пишите функции и классы для часто используемых операций (загрузка данных, специфическая предобработка).
- Создавайте кастомные трансформеры для scikit-learn, если это упрощает пайплайн.
- В Airflow используйте кастомные операторы или хуки для повторяющихся взаимодействий с системами.
Работа с конфигурациями и секретами
- Не хардкодьте пути к файлам, параметры моделей, креды к базам данных в коде!
- Используйте конфигурационные файлы (YAML, JSON, .env).Для секретов — Vault, переменные окружения, Airflow Connections/Variables.
CI/CD для ML-проектов
- Автоматизируйте тестирование (unit-тесты для трансформеров, интеграционные тесты для пайплайна) и деплоймент.
- Инструменты: Jenkins, GitLab CI, GitHub Actions.
- CI/CD-пайплайн может включать: linting, тесты, сборку Docker-образа, обучение модели (возможно, на небольшом датасете для проверки), деплой в staging, а затем в production.
Документация и тестирование пайплайнов
- Документируйте каждый шаг пайплайна: что он делает, какие данные ожидает на входе, что производит на выходе.
- Пишите тесты:
— для отдельных компонентов (трансформеров);
— для всего пайплайна (проверка, что он отрабатывает без ошибок, проверка размерности выхода, проверка на известных граничных случаях);
— тесты на качество модели (например, что метрика не падает ниже определенного порога).
Коротко о ML-пайплайнах
ML-пайплайны — это не роскошь, а необходимость для любого серьезного проекта. Они приносят воспроизводимость, эффективность и надежность. Мы рассмотрели основные этапы, популярные инструменты (от простого Scikit-learn Pipeline до мощных оркестраторов вроде Airflow и MLOps-платформ типа MLflow и Kubeflow) и обсудили практические аспекты их построения.
Ключевые моменты:
- Автоматизируйте все, что можно.
- Думайте о воспроизводимости с самого начала.
- Не забывайте про обработку данных — это 80% успеха.
- Версионируйте все: код, данные, модели.
- Мониторьте свои модели в продакшене.
Где можно узнать больше об ML-пайплайнах:
- Документация: Scikit-learn, Apache Airflow, MLflow, Kubeflow — официальная документация всегда лучший источник.
- Книги: “Building Machine Learning Powered Applications” (Emmanuel Ameisen), “Designing Data-Intensive Applications” (Martin Kleppmann) — хоть и не только про пайплайны, но дают фундаментальное понимание. “Introducing MLOps” (Mark Treveil et al.)
- Курсы: множество курсов на Coursera, Udemy, Udacity по MLOps и построению ML-систем.
- Практика: лучший способ научиться — делать. Возьмите свой пет-проект и попробуйте обернуть его в пайплайн.
Мир ML-пайплайнов огромен и постоянно развивается. Какие инструменты используете вы? С какими проблемами сталкивались? Делитесь своим опытом и вопросами в комментариях — буду рад обсудить!