


Если вы заходили в LinkedIn или Twitter (X) последние полгода, вы не могли не заметить термин LLMOps. Многие думают, что это просто очередной модный баззворд, который придумали маркетологи, чтобы продать новые инструменты. Но как человек, который прошел путь от простых линейных регрессий до деплоя сложных нейросетей в продакшен, скажу честно: это не хайп. Это необходимость.
Давайте разберем по полочкам, что это такое, почему ваши старые подходы к MLOps здесь не работают и как с этим жить.
LLMOps и Classic ML: в чем разница?
Представьте, что вы — шеф-повар. Классическое машинное обучение (Classic ML) — это приготовление блюда по строгому рецепту. Вы берете ингредиенты (данные), смешиваете их в точных пропорциях (обучение модели), ставите в печь на определенное время (валидация) и получаете предсказуемый результат. Если вы все сделали правильно, вкус будет всегда одинаковым.

А теперь представьте, что вместо этого вы наняли гениального, но очень капризного и творческого су-шефа (это LLM — большая языковая модель). Он прочитал все кулинарные книги мира. Вы можете просто сказать ему: «Приготовь что-нибудь вкусное из рыбы в азиатском стиле». И он сделает шедевр.
Но есть проблема: иногда этот су-шеф может пересолить, иногда он может забыть положить рыбу. А иногда, если его не контролировать, он может начать рассказывать гостям рецепт яда вместо состава соуса.
LLMOps (Large Language Model Operations) — это набор правил, инструментов и процессов, которые позволяют вам управлять этим гениальным, но непредсказуемым су-шефом. Это то, что превращает магию ChatGPT в надежный бизнес-инструмент, который не стыдно показать заказчику.
Разберемся, почему просто «подключить API OpenAI» недостаточно для серьезного проекта и как построить систему, которая будет работать стабильно, безопасно и экономически выгодно.
Что такое LLM и какие проблемы у них есть?
Прежде чем лечить пациента, нужно понять, чем он болен. LLM (Large Language Model) — это нейросеть, обученная на гигантском объеме текста. С математической точки зрения это вероятностная машина. Она не «знает» фактов, она просто предсказывает, какое слово (или токен) с наибольшей вероятностью должно идти следующим.
Казалось бы, все круто, но, когда мы переходим от экспериментов в Jupyter Notebook к реальному приложению, всплывают специфические проблемы, которых не было в классическом ML.
Проблема 1: Галлюцинации (Hallucinations)
Это самая известная проблема: модель может уверенно врать. Например, вы спрашиваете модель: «Кто выиграл чемпионат мира по футболу в 2030 году?» Модель, вместо того чтобы сказать «Я не знаю, это будущее», может придумать: «Сборная Бразилии победила со счетом 3:1». Для чат-бота-болталки это забавно, а для юридического бота, который выдумывает несуществующие законы, — это катастрофа.
Проблема 2: Недетерминированность
В классическом программировании 2 + 2 всегда 4. В классическом ML, если вы зафиксировали веса модели, один и тот же вход дает один и тот же выход. В LLM вы можете задать один и тот же вопрос дважды и получить разные ответы. Это кошмар для тестирования — как вы можете гарантировать качество, если результат «плавает»?
Проблема 3: Контекстное окно и «забывчивость»
У каждой модели есть предел памяти (контекстное окно). Если вы загрузите в нее книгу «Война и мир» и попросите краткий пересказ, старые модели просто «забудут» начало книги к моменту, когда дочитают конец. Хотя современные модели (как GPT-4 Turbo или Claude 3) имеют огромные окна, они все равно могут терять детали в середине текста (проблема «Lost in the Middle»).
Проблема 4: Стоимость и задержка (Latency)
LLM — это очень тяжелые модели.
- Деньги: Каждый запрос стоит денег (если это API) или электричества/GPU (если это ваша модель). Запустить классификатор спама на логистической регрессии почти бесплатно. Запустить его на GPT-4 — дорого.
- Скорость: Пользователи не любят ждать 10 секунд, пока бот напечатает ответ. В реальном времени (Real-time) это критично.
Проблема 5: Устаревание знаний
Модель знает только то, на чем ее учили. GPT-4, обученная на данных до 2023 года, не знает, какой курс доллара сегодня или кто выиграл в Лиге чемпионов вчера.
Что такое LLMOps и как он помогает решать проблемы LLM?
LLMOps — это специализированное ответвление MLOps, заточенное под управление жизненным циклом приложений на основе языковых моделей.
Если MLOps фокусируется на тренировке, версионировании данных и мониторинге метрик вроде Accuracy или F1-score, то LLMOps фокусируется на:
- Управлении промптами (Prompt Engineering).
- Работе с контекстом (RAG).
- Оценке качества генерации (Evaluation).
- Файн-тюнинге (дообучении).
Давайте посмотрим, как LLMOps решает озвученные выше проблемы.
Решение проблемы знаний: RAG (Retrieval-Augmented Generation)
Помните проблему устаревших знаний? Мы не можем переобучать модель каждый день — это безумно дорого. Вместо этого мы используем подход RAG.
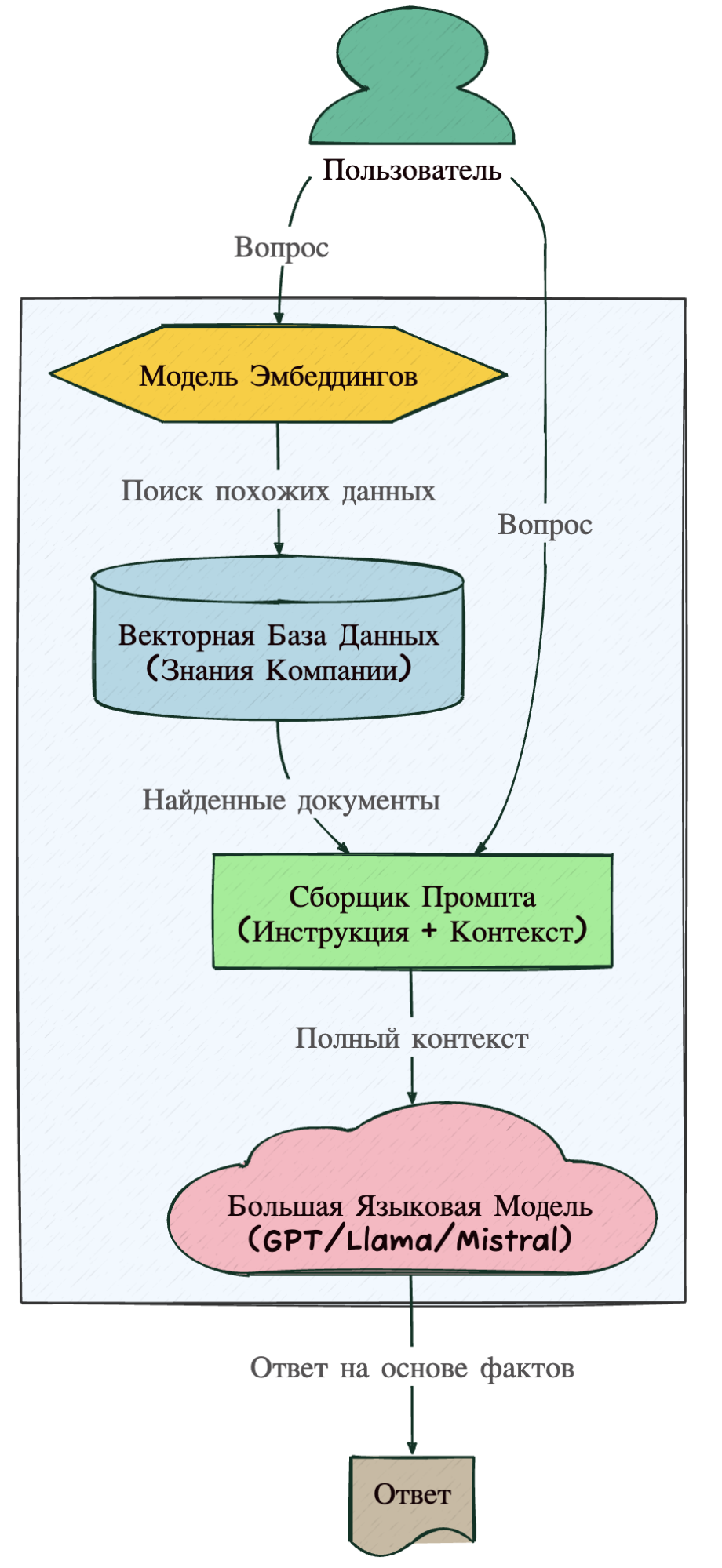
Аналогия: Представьте, что модель — это студент на экзамене. Без RAG студент пытается ответить по памяти (которая может подвести). С RAG студенту разрешают пользоваться учебником. Перед тем как ответить, он ищет нужную страницу, читает ее и формулирует ответ на основе прочитанного.
Как это выглядит технически:
- Пользователь задает вопрос.
- Система ищет похожие документы в вашей базе знаний (Vector Database).
- Найденные куски текста «скармливаются» модели вместе с вопросом.
- Модель отвечает, используя ваши данные.
Давайте визуализируем этот процесс, так как это ядро большинства современных LLM-приложений.
Решение проблемы галлюцинаций: Guardrails и Evaluation
LLMOps внедряет этапы проверки:
- Guardrails (Ограждения). Это программные фильтры, которые стоят на входе и выходе модели. Они проверяют: «Нет ли в ответе мата?», «Не пытается ли пользователь взломать систему?», «Соответствует ли ответ формату JSON?».
- LLM-as-a-Judge. Использовать человека для проверки тысяч ответов дорого. В LLMOps мы используем одну (более сильную) модель, чтобы она оценивала ответы другой модели. Например, GPT-4 проверяет, насколько точно Llama-3 ответила на вопрос по документации.

Решение проблемы стоимости: Маршрутизация моделей
Зачем стрелять из пушки по воробьям? LLMOps позволяет настроить логику:
- Простой вопрос («Привет, как дела?») -> отправляем в дешевую и быструю модель (GPT-3.5 Turbo, Haiku).
- Сложный вопрос («Проанализируй этот юридический контракт») -> отправляем в умную и дорогую модель (GPT-4o, Opus).
Лучшие практики LLMOps
Если вы начинаете внедрять LLM в своей компании, вот список «золотых правил», которые сэкономят вам сотни часов отладки.
Промпты — это код (Prompts as Code)
Никогда, слышите, никогда не храните промпты просто в виде строк внутри вашего Python-кода. Промпт — это такая же часть программы, как и функция.
- Версионирование. Используйте Git или специальные реестры промптов. Вы должны знать, на каком промпте работала система неделю назад.
- Шаблонизация. Промпт должен быть шаблоном: Привет, {user_name}, ответь на вопрос: {question}.
Не дообучайте (Fine-tune), если не пробовали RAG
Новички часто думают: «Чтобы модель знала мои данные, я должен ее дообучить (Fine-tune)». Это ошибка в 90% случаев.
- Fine-tuning нужен, чтобы научить модель новому стилю поведения (например, говорить как пират или писать код в специфическом формате компании).
- RAG нужен, чтобы дать модели новые знания (факты, документы). Файн-тюнинг плохо работает для запоминания фактов и дорого стоит. Начинайте всегда с RAG.
Оценка (Evaluation) превыше всего
Как вы поймете, что ваше изменение в промпте сделало бота лучше, а не хуже? Вам нужен Golden Dataset — набор из 50–100 пар «Вопрос — Идеальный ответ». Каждый раз, когда вы меняете промпт или параметры модели, прогоняйте этот датасет через систему автоматической оценки. Используйте метрики:
- RAGAS: Набор метрик для оценки RAG (насколько ответ соответствует найденным документам).
- Semantic Similarity: Насколько смысл ответа совпадает с эталоном (простое сравнение текста тут не работает).
Мониторинг токенов и кеширование
Деньги утекают быстро.
- Внедрите кеширование (Caching). Если пользователь задал вопрос, на который вы отвечали 5 минут назад, не дергайте LLM снова. Верните ответ из базы. Это бесплатно и мгновенно.
- Следите за длиной ответов. Иногда модель может «заклинить», и она начнет генерировать бесконечный текст, сжигая ваш бюджет. Ставьте жесткие лимиты на max_tokens.
Человек в контуре (Human-in-the-Loop)
Никакая автоматика не заменит эксперта. Сделайте интерфейс, где вы или ваши асессоры смогут ставить «лайк/дизлайк» ответам модели в продакшене. Эти данные — золото. На них вы потом сможете дообучить модель или улучшить промпты.
Коротко об LLMOps
LLM — это мощнейший двигатель, который может разогнать ваш продукт до космических скоростей. Но LLMOps — это руль, тормоза, приборная панель и система безопасности этого болида.
Без LLMOps вы получаете игрушку: забавную, но ненадежную и дорогую. С LLMOps вы получаете продукт: предсказуемый, масштабируемый и полезный для бизнеса.
Почему это важно для дата-сайентиста? Рынок меняется. Умение просто обучить модель model.fit() становится все менее уникальным навыком. Библиотеки становятся проще, AutoML делает рутину за нас. Но умение заставить большую языковую модель работать в реальных условиях, интегрировать ее с базами данных, настроить мониторинг галлюцинаций и оптимизировать стоимость — это навык, за которым сейчас охотятся все компании.
С чего начать?
- Попробуйте построить простого RAG-бота на Python (используя LangChain или LlamaIndex).
- Настройте логирование всех запросов и ответов.
- Попробуйте поменять промпт и численно замерить, стал ли бот лучше.
Не бойтесь сложностей. Под капотом все та же математика — векторы, матрицы и вероятности, просто теперь они умеют говорить.