


Большие данные часто бывает трудно обработать в рамках одного процесса. Нужны инструменты, которые умеют проводить вычисления параллельно: одновременно выполнять несколько процессов. Один из таких инструментов — Apache Spark. И его версия для Python — PySpark.
Рассказываем, как устроен модуль PySpark, для каких задач его используют и почему для его работы все еще нужен язык Java.
Что такое PySpark и зачем он нужен
Spark — это фреймворк от Apache, часть экосистемы Hadoop для управления большими данными. Он умеет быстро обрабатывать огромные объемы информации и изначально предназначен для работы с Java.

PySpark — интерфейс Apache Spark, который позволяет работать с ним на языке Python. Он интегрируется с другими возможностями языка, но при этом сохраняет все функции оригинального Spark.
С модулем работают аналитики, дата-сайентисты и дата-инженеры. Его применяют для задач, в которых нужно обработать большое количество сложной информации:
- анализ больших датасетов;
- очистка, трансформация и агрегация данных;
- машинное обучение на больших данных;
- потоковая обработка данных;
- работа с графами — структурами со множеством связей.
Такие задачи встречаются в разных сферах: финансовой, банковской, научной. Большие данные используют при планировании алгоритмов для соцсетей, для анализа логов и множества других процессов.
Как устроен PySpark
В основе фреймворка лежит кластерная архитектура. Это значит, что вычисления выполняются на нескольких независимых узлах, которые объединяются в группы — кластеры. Узлы могут находиться на разных устройствах или даже группах устройств.
Архитектура PySpark основана на двух компонентах:
- Driver — управляющий узел, который отдает команды исполнителям.
- Executors — исполнительные узлы, на которых, собственно, происходят вычисления.
Управляющий узел обычно только один, а исполнительных может быть сколько угодно. Они работают параллельно, поэтому PySpark быстро обрабатывает большие данные.
Между Driver и Executors есть еще одно промежуточное звено — менеджер кластеров. Это объект, который распределяет вычисления и балансирует нагрузку на узлы. Он решает, сколько памяти и ресурсов выделить на задачу и каким исполнителям ее поручить.
Часто в роли менеджера выступают Kubernetes, Yarn и другие современные системы для управления кластерами. Хотя в модуле есть встроенный менеджер Standalone, в продакшене его используют редко — он менее функционален.
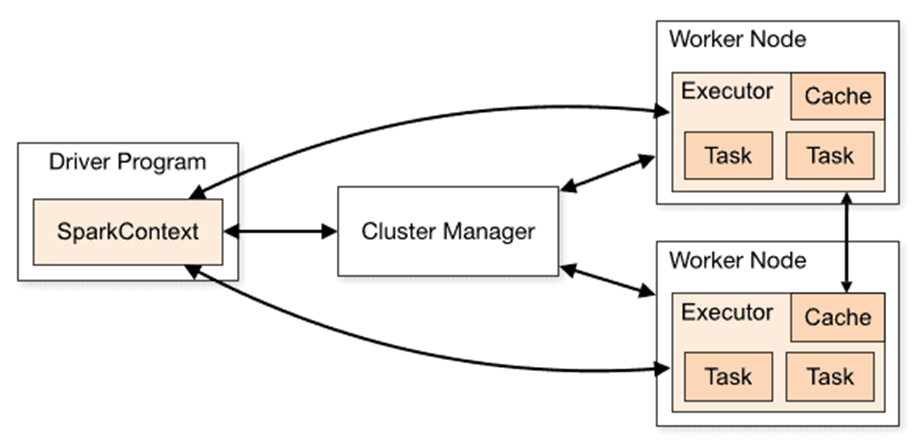
Внутри Driver находится компонент SparkSession. Он появился в версиях Spark 2.x и объединил в себе несколько управляющих подсистем, важных для работы модуля:
- SparkContext — процесс, который называют точкой входа. Он запускается при старте PySpark и устанавливает соединение с исполнителями. Именно SparkContext отвечает за «общение» управляющего узла с Cluster Manager и Executors. Он же планирует задачи и управляет структурой данных RDD.
- SQLContext — компонент, который добавляет в PySpark поддержку языка запросов SQL и DataFrame. Это табличная структура данных, которую часто используют в BigData.
- HiveContext — расширение SQLContext, которое позволяет работать с экосистемой Apache Hive.
- Catalyst Optimizer — оптимизатор для языка запросов Spark SQL. Когда разработчик пишет код, этот компонент анализирует запросы и перестраивает их более оптимальным способом. Благодаря нему запросы работают быстрее и эффективнее.
- Unified API — единый интерфейс для работы с разными видами данных. Например, в него входят DataFrame / Dataset API для одноименных структур. Этот подход помогает разработчику не переключаться между интерфейсами, а управлять всем из одной точки.
PySpark умеет работать с разными структурами данных. Исторически он использовал RDD (Resilient Distributed Datasets) — распределенную коллекцию данных. Она устойчива к сбоям, а информация в ней разделяется на блоки для параллельной обработки.
Сейчас RDD применяют реже. В PySpark появилась поддержка новых структур, таких как DataFrame и Dataset. Они быстрее работают и автоматически оптимизируются, поэтому сейчас разработчики предпочитают использовать именно их.
Какие возможности есть в PySpark
Модуль позволяет работать с разными видами больших данных: структурированными, табличными, потоковыми. Он поддерживает работу с графами и обучение ML-моделей. Разберем его возможности подробнее.
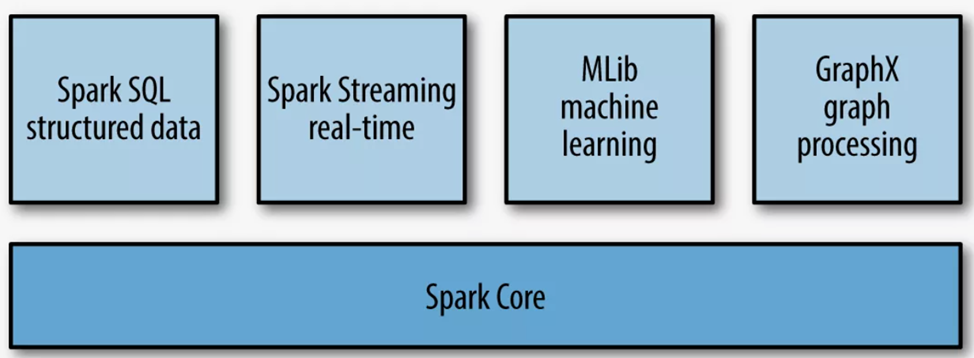
Анализ структурированных данных
Работа с PySpark в плане анализа данных немного похожа на работу с библиотекой Pandas. Разница в том, что вычисления происходят на кластере — а значит, производительнее и быстрее.
Обычно анализ и работа с информацией происходят через структуру DataFrame. В датафрейм загружаются данные — их можно добавить из разных источников:
- из классических баз данных;
- таблиц JSON, CSV и других форматов;
- специальных форматов для хранения больших данных, например ORC;
- списков и других структур.
После этого данными можно манипулировать через DataFrame API. Например, фильтровать их по какому-то принципу, вычислять по ним статистику, объединять и преобразовывать.
В PySpark встроенная оптимизация — система автоматически решает, как эффективнее провести операции. Это позволяет быстрее получить результат вычислений.
Работа с данными через SQL
В PySpark можно обрабатывать информацию с помощью языка запросов Spark SQL. Он поддерживает как базовые запросы вроде выбора или группировки, так и более сложные — объединение, оконные функции или работу с наборами данных. Можно создавать собственные функции — UDF.
SQL-запросы автоматически оптимизирует Catalyst Optimizer. Это помогает быстрее получать результат и ускорять работу с большими данными.

Машинное обучение
В экосистему Spark встроена библиотека MLlib для машинного обучения. Она позволяет создавать и обучать модели, работать с распространенными алгоритмами, такими как:
- Регрессия — линейная, логистическая, изотоническая или с помощью деревьев решений.
- Классификация — алгоритмы вроде случайного леса или градиентного бустинга.
- Кластеризация — разделение данных по кластерам с помощью метода k-средних, смешанных моделей и других подходов.
- Обработка естественного языка — преобразование слов, векторизация и другие NLP-процессы.
- Построение прогнозов и рекомендаций — алгоритмы, работающие на основе коллаборативной фильтрации.
У библиотеки два интерфейса: для работы с RDD или DataFrame. Второй сейчас используют чаще, потому что он удобнее. Сама работа основана на принципе пайплайна, или конвейера. То есть последовательность различных действий выполняется как единый процесс.
Созданную модель можно сохранить, передать ей новые данные или экспортировать в другой фреймворк для машинного обучения, например TensorFlow.
Работа с потоковыми данными
Это данные, которые обновляются в реальном времени, например информация с датчиков или логи. Для работы с ними в PySpark есть механизм Structured Streaming. Он работает поверх DataFrame API и Spark SQL.
Поток в Structured Streaming представляется как бесконечная таблица. Благодаря такому подходу работать с потоковыми данными можно так же, как с традиционными. Человек просто пишет код как обычно, а обработка потока — задача PySpark.
К потоковым данным применяют стандартные операции DataFrame. Но есть и специфические функции:
- выделение группы данных методом плавающих окон;
- настраиваемое отбрасывание слишком старой информации;
- настройка частоты обновления данных;
- сохранение состояния потока.
PySpark умеет получать потоковую информацию из разных источников. Например, из систем сообщений вроде Kafka, из баз данных, с IoT-инструментов, из файловых систем.
Результаты обработки тоже могут выводиться по-разному. Для этого в Structured Streaming есть три режима. Append mode выводит только новые данные, Update mode — только те, которые изменились, Complete mode — весь набор информации.
Обработка графов
Графы — это структуры, которые состоят из узлов и связей между ними. Так можно представить, например, дорожную карту или список контактов человека в соцсети. Для работы с такой информаций в оригинальном Spark есть два компонента:
- GraphX — графы строятся на основе структуры данных RDD;
- GraphFrames — графы строятся на основе DataFrame.
В PySpark полноценно работать можно только с GraphFrames. Но это не мешает обрабатывать графы. К тому же для версий Spark 4.x и выше компонент GraphX считается устаревшим.
GraphFrames представляет граф как две таблицы DataFrame. Одна хранит информацию о вершинах, то есть узлах, графа, вторая — о ребрах, или связях. Работа с ними происходит через DataFrame API или Spark SQL.
С помощью GraphFrames можно:
- получать информацию о вершинах и ребрах графа;
- искать маршруты от одной вершины к другой;
- измерять веса разных вершин, то есть общее количество их связей, например, для ранжирования;
- находить связанные вершины — такие, между которыми существует путь;
- проводить кластеризацию графов.
Это нужно, например, при классификации информации, построении маршрутов, работе с соцсетями и рекомендательными алгоритмами.
Как установить PySpark и начать с ним работать
Чтобы PySpark заработал, на устройстве нужно установить язык программирования Java. Это важно, потому что внутри Python-обертки — оригинальный Spark, а для его работы нужна Java Virtual Machine (JVM).
Проверить наличие Java можно с помощью команды в консоли:
java-version
Если система пишет, что такого компонента нет, нужно вручную установить JDK — Java Development Kit:
- PySpark 3.x лучше всего работает с версиями JDK 8 и 11.
- PySpark 4.x — с JDK 17 или 21.
Нужную версию JDK можно установить из репозитория через консоль или скачать вручную. Рекомендуется использовать сборки OpenJDK с открытым исходным кодом.
Установку самого PySpark проще всего провести через пакетный менеджер pip:
pip install pyspark
Установка может занять время и потребовать вашего участия. Например, согласия на загрузку каких-либо пакетов. Или ручного обновления устаревших и несовместимых компонентов.
Работать с PySpark можно через среды программирования и редакторы кода, которые поддерживают Python — например, IDE PyCharm или редактор VS Code. Или через сервисы вроде Jupyter Notebook.
Приложения, созданные на базе PySpark, можно запускать через специальную консольную утилиту spark-submit.
PySpark: коротко о главном
- PySpark — python-интерфейс модуля Spark для распределенной работы с большими данными. Изначально модуль был предназначен для Java.
- С помощью PySpark можно параллельно обрабатывать данные, в том числе потоковые, обучать ML-модели и работать с графами.
- Модуль позволяет работать со структурами данных RDD, DataFrame и Dataset, поддерживает SQL и может интегрироваться с экосистемой Apache Hive.
- Для установки PySpark потребуется Java Development Kit, а сам модуль можно установить с помощью менеджера pip.