


Apache Flink — это фреймворк и распределенный движок обработки данных, поддерживающий как пакетную (ограниченную), так и потоковую (неограниченную) обработку данных. Это значит, что с его помощью можно обрабатывать как статичные (неизменяемые) данные, так и данные, поступающие в реальном времени.
Он работает как в одной, так и в различных кластерных средах, когда задачи распределены между несколькими машинами. Подобным образом работает и MapReduce, который в отличие от Flink ограничен пакетной обработкой данных.
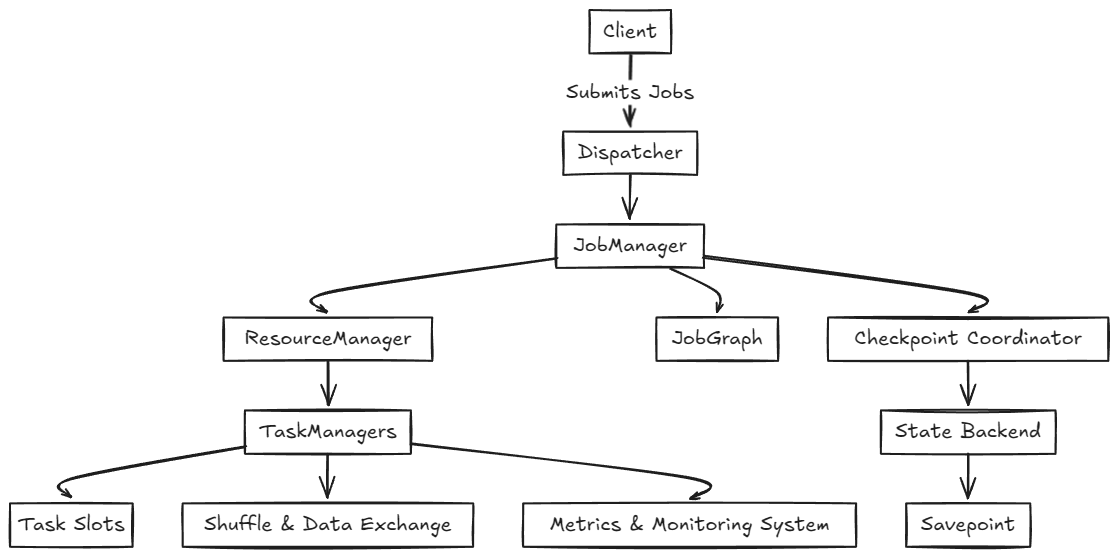
Архитектура и основные компоненты Apache Flink
Как мы уже знаем, Apache Flink может обрабатывать данные двумя способами:
- Пакетная обработка (Batch Processing) — обработка конечного набора данных, например файлов или баз данных.
- Потоковая обработка (Stream Processing) — работа с бесконечным потоком данных в реальном времени, как в случае с событиями и данными, поступающими постоянно.

Система Flink состоит из следующих компонентов:
— Dispatcher. Получает описание задачи от клиента или другого компонента системы, который хочет запустить задачу в Flink. Предоставляет REST API для запуска задач в Flink.
— Job Manager. Управляет выполнением задач, их планированием и распределением. Выполняет операции, такие как создание чекпоинтов и восстановление приложения после сбоев.
— Resource Manager. Координирует ресурсы, взаимодействует с внешними провайдерами, масштабирует приложение при необходимости.
— Task Manager. Выполняет задачи, управляет их состоянием и сообщает метрики в Job Manager.
— JobGraph. Представляет абстрактное описание вычислительного задания в Flink, которое включает последовательность этапов обработки данных и зависимости между ними. Он определяет, какие операции нужно выполнить и в какой последовательности.
— Checkpoint Coordinator. Управляет созданием чекпоинтов (автоматических точек восстановления).
— Savepoint. Точка восстановления, созданная по инициативе пользователя. Позволяет сохранить текущее состояние задачи, например перед обновлением или изменением конфигурации.
— State Backend. Хранит состояние задачи и управляет им, поддерживает различные механизмы хранения и управления состоянием. Это может быть хранение в памяти или на диске, с использованием различных технологий и систем для хранения данных.
— Task Slots. Единицы, которые определяют, сколько задач может одновременно выполнять TaskManager. Каждое задание (или его часть) назначается на слот для выполнения. Количество слотов в TaskManager ограничивает параллельность — количество задач, которые могут быть обработаны одновременно этим узлом.
— Shuffle и Data Exchange. Оптимизированный обмен данными между задачами. Включает передачу данных между различными этапами обработки.
— Client. Интерфейс для отправки и мониторинга задач через CLI, REST API или клиентскую библиотеку.
— Metrics и Monitoring System. Система для сбора и мониторинга метрик задач и ресурсов (интегрируется с инструментами по типу Prometheus и Grafana).
Какие языки программирования поддерживает Flink
Flink поддерживает несколько языков программирования:
- Java — основной язык для работы с Flink с наиболее развитым API.
- Scala — второй по популярности язык для работы с Flink.
- JVM-совместимые языки (например, Kotlin) — поддерживаются, но без официальной поддержки.
- Python — поддержка осуществляется через PyFlink.
- SQL — поддерживается для декларативной обработки данных.
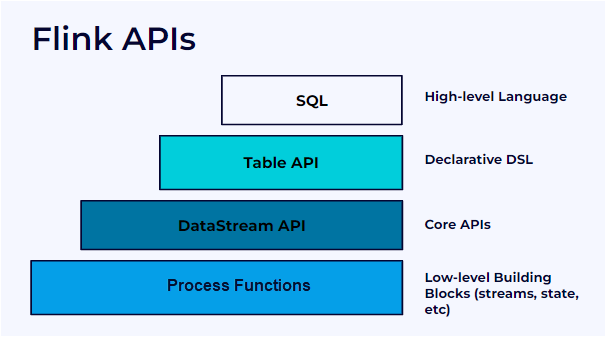
Основные API
У Apache Flink есть несколько уровней абстракции (API) для обработки данных.
- SQL API — самый высокий уровень абстракции, позволяющий выполнять SQL-запросы над потоками данных. Подходит для тех, кто привык работать с SQL и не нуждается в тонкой настройке.
- Table API — декларативный API для работы с таблицами, похож на SQL, но поддерживает динамическую обработку потоков данных.
- DataStream API — низкоуровневый API для потоковой обработки, есть операции для манипулирования потоками данных в реальном времени.
- Process Function API — самый низкоуровневый API, который дает полный контроль над обработкой событий, их порядком и состоянием.
SQL API и Table API
Flink SQL API и Table API — это два API для аналитической обработки данных в Flink, интегрированные в одно общее API. Они позволяют выполнять SQL-запросы или работать с таблицами в потоковых приложениях.
Как работают SQL API и Table API
Table API и SQL API работают со StreamTableEnvironment. Это абстрактный класс для обработки таблиц в потоках данных в Apache Flink. Он расширяет интерфейс TableEnvironment и нужен для работы с таблицами и SQL-запросами в потоке.
Table API — это декларативный интерфейс для работы с таблицами. Позволяет выполнять операции, похожие на SQL (select, filter, join), но с использованием методов API. Поддерживает потоковые и пакетные данные.
SQL API — это интерфейс для работы с Flink с помощью SQL. Основан на Apache Calcite, который обрабатывает SQL-запросы. Семантика SQL одинакова для потоков и пакетных данных.
Пример на Java
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
EnvironmentSettings settings = EnvironmentSettings.newInstance().useBlinkPlanner().inStreamingMode().build();
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env, settings);
tableEnv.executeSql("CREATE TABLE MyTable (id INT, name STRING)");
Table result = tableEnv.sqlQuery("SELECT * FROM MyTable WHERE id > 10");
DataStream<Row> stream = tableEnv.toDataStream(result);
Пример на Scala
val env = StreamExecutionEnvironment.getExecutionEnvironment
val settings = EnvironmentSettings.newInstance().useBlinkPlanner().inStreamingMode().build()
val tableEnv = StreamTableEnvironment.create(env, settings)
tableEnv.executeSql("CREATE TABLE MyTable (id INT, name STRING)")
val result = tableEnv.sqlQuery("SELECT * FROM MyTable WHERE id > 10")
val stream = tableEnv.toDataStream(result)
Примечание: SQL и Table API работают в тесной связи с DataStream API, так как используют его для создания таблиц из потоков, выполнения вычислений, оптимизации и интеграции потоковой и декларативной обработки.
Datastream API
Datastream API нужен для потоковой обработки данных. Он позволяет выполнять операции над потоками данных: фильтрацию, обновление состояний, агрегации, оконные операции и другие трансформации.
Потоки данных могут быть созданы из различных источников (очередей сообщений, сокетов, файлов) и выводиться в различные хранилища.
Как работает DataStream API
DataStream API работает с классом DataStream (Java или Scala) — коллекцией данных, которые могут быть как конечными, так и неограниченными (непрерывными потоками). Эти данные можно обрабатывать с помощью различных операторов и трансформаций, например:
- map — применяет функцию к каждому элементу;
- flatMap — преобразует элемент в 0, 1 или несколько новых элементов;
- filter — отбирает элементы по условию;
- keyBy — группирует поток по ключу;
- reduce — агрегирует элементы внутри группы;
- window — разделяет поток на окна (временные или по количеству элементов);
- process — проводит низкоуровневую обработку с доступом к состоянию.
Пример на Java
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<String> text = env.readTextFile("input.txt");
DataStream<String> filtered = text.filter(line -> line.startsWith("Error"));
filtered.print();
Пример на Scala
val env = StreamExecutionEnvironment.getExecutionEnvironment
val text = env.readTextFile("input.txt")
val filtered = text.filter(_.startsWith("Error"))
filtered.print()
В обоих случаях создаем потоки и фильтруем данные:
readTextFile — создает поток данных из файла;
filter — фильтрует строки, которые начинаются с Error.

Process Function API
Process Function API предоставляет низкоуровневые функции для обработки потоковых данных, в том числе управление состоянием, временем и окнами. Этот API позволяет работать с событиями, состоянием и таймерами.
Работа с временем
Flink поддерживает обработку с учетом Event Time с помощью watermarks (assignTimestampsAndWatermarks) и оконных функций (window, trigger).
Основные механизмы:
- Watermarks указывают границу обработанных событий (WatermarkStrategy.forBoundedOutOfOrderness(Duration.ofSeconds(5))).
- Timers в KeyedProcessFunction (ctx.timerService().registerEventTimeTimer(timestamp)) выполняют отложенные действия при достижении временного порога.
- Windows
(.window(TumblingEventTimeWindows.of(Time.seconds(10)))) группирует события по времени.
- Triggers (EventTimeTrigger.create()) определяют момент срабатывания окна.
Также Flink поддерживает низкоуровневые джойны между потоками с помощью функций CoProcessFunction и KeyedCoProcessFunction.
Джойны (CoProcessFunction, KeyedCoProcessFunction) позволяют объединять события из разных потоков.
Работа с состоянием
Flink поддерживает состояния (Stateful Processing), которые можно сохранить с помощью Checkpoints и Savepoints.
Состояние (например, ValueState, ListState, MapState) хранит промежуточные данные (getRuntimeContext().getState(…)).
ProcessFunction и KeyedProcessFunction позволяют работать с состоянием и таймерами для ключевых потоков. С помощью RuntimeContext можно управлять состоянием и регистрировать таймеры для работы как с временем событий, так и с временем обработки.
Основные моменты:
- processElement() — обработка каждого события;
- onTimer() — обработка по таймеру;
- ctx.timerService().registerEventTimeTimer() — регистрация таймера.
Пример на Java
stream.keyBy(value -> value)
.process(new KeyedProcessFunction<String, String, String>() {
private transient ValueState<Integer> countState;
@Override
public void open(Configuration parameters) {
countState = getRuntimeContext().getState(new ValueStateDescriptor<>("countState", Integer.class, 0));
}
@Override
public void processElement(String value, Context ctx, Collector<String> out) {
int currentCount = countState.value();
countState.update(currentCount + 1);
// Устанавливаем таймер на 1 минуту ctx.timerService().registerEventTimeTimer(ctx.timestamp() + 60000);
out.collect(value + " processed: " + (currentCount + 1));
}
@Override
public void onTimer(long timestamp, OnTimerContext ctx, Collector<String> out) {
out.collect("Timer triggered for key: " + ctx.getCurrentKey());
}
})
.print();
Пример на Scala
stream.keyBy(value => value)
.process(new KeyedProcessFunction[String, String, String] {
@transient var countState: ValueState[Int] = _
override def open(parameters: Configuration): Unit = {
val descriptor = new ValueStateDescriptor[Int]("countState", classOf[Int], 0)
countState = getRuntimeContext.getState(descriptor)
}
override def processElement(value: String, ctx: KeyedProcessFunction[String, String, String]#Context, out: Collector[String]): Unit = {
val currentCount = countState.value()
countState.update(currentCount + 1)
ctx.timerService().registerEventTimeTimer(ctx.timestamp() + 60000) // Устанавливаем таймер на 1 минуту
out.collect(s"$value processed: ${currentCount + 1}")
}
override def onTimer(timestamp: Long, ctx: KeyedProcessFunction[String, String, String]#OnTimerContext, out: Collector[String]): Unit = {
out.collect(s"Timer triggered for key: ${ctx.getCurrentKey}")
}
})
.print()
Здесь:
keyBy() разбивает поток на ключи;
process() применяет обработку для каждого ключа;
ValueState хранит состояние для каждого ключа;
таймеры ожидают определенное время для срабатывания, например для расчетов или сбора данных.
Коннекторы (источники данных)
Flink может работать с различными источниками данных и отправлять результаты в хранилища с помощью коннекторов.
Источник (Source). Функция источника получает данные и передает их в поток обработки. Пример источника — Kafka, откуда Flink может получать сообщения в реальном времени.
Синк (Sink). Функция синка принимает данные из потока и отправляет их в выбранное хранилище, например в базу данных или файл.
Часто используемые коннекторы:
- Apache Kafka для получения данных в реальном времени.
- HDFS для работы с распределенными файловыми системами.
- JDBC-совместимые базы данных для работы с реляционными базами данных. Например, MySQL, PostgreSQL, H2 Database.
- Elasticsearch для индексации и поиска данных.
Приложение Flink и окружение
Flink-приложение — это программа, которая включает Flink-задачу и необходимую для ее выполнения конфигурацию.
Окружение (Environment) — это среда, в которой выполняется Flink-приложение. В окружении содержатся настройки, параметры и ресурсы для выполнения задач. Окружение для Flink может быть локальным или кластерным.
- Local Environment — локальная среда для тестирования и отладки приложений на одном компьютере.
- Cluster Environment — окружение, настроенное для работы в распределенном кластере (например, в YARN или Kubernetes), где Flink-задача выполняется на нескольких машинах.
Как настроить окружение и начать пользоваться Flink
Рассмотрим, как создать рабочее окружение Flink для работы на Java, настроить StreamTableEnvironment для обработки данных и подключить источники, такие как Kafka, для работы с реальными потоками данных.
Настройка окружения для Flink
- Установите Java (JDK 8 или выше). Как установить Java, рассказывали в этой статье.
- Установите Apache Flink
Скачайте Flink с официального сайта и распакуйте архив в удобную директорию. Рекомендуется выбрать актуальную стабильную версию, если нет особых требований. При этом она должна быть совместима с версией Java.
- Настройте зависимости
Убедитесь, что у вас установлен Maven или Gradle для работы с зависимостями.
Для Maven добавьте зависимость в файл pom.xml:
<dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-streaming-java</artifactId> <version> версия </version> </dependency>
Для Gradle добавьте зависимость в build.gradle:
dependencies {
implementation 'org.apache.flink:flink-streaming-java:версия'
}
Создание StreamTableEnvironment
В Flink для работы с потоковыми данными через таблицы используют StreamTableEnvironment. Он позволяет выполнять SQL-запросы и работать с таблицами в потоке данных.
Перед работой также нужно дополнить список зависимостей Table API и SQL API.
Для Maven:
<dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-table-api-java</artifactId> <version> версия </version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-table-planner</artifactId> <version> версия </version> </dependency>
Для Gradle:
dependencies {
implementation 'org.apache.flink:flink-table-api-java:версия'
implementation 'org.apache.flink:flink-table-planner:версия'
}
Пример на Java
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.TableEnvironment;
import org.apache.flink.table.api.Table;
public class FlinkTableExample {
public static void main(String[] args) throws Exception {
// Создаем потоковое окружение
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// Создаем StreamTableEnvironment для работы с таблицами
TableEnvironment tableEnv = TableEnvironment.create(env);
// Пример SQL-запроса
String query = "SELECT * FROM my_table WHERE my_column > 100";
// Выполняем запрос и преобразуем результат в таблицу
Table result = tableEnv.sqlQuery(query);
// Трансформируем данные
result.execute().print();
}
}
В этом примере создаем StreamTableEnvironment, с помощью которого выполняем SQL-запрос для фильтрации данных из таблицы.
Подключение источников данных
Для обработки данных в Flink также необходимо подключить источники, такие как Kafka, файлы, базы данных и другие, с помощью соответствующих коннекторов.
Пример подключения Kafka
Для Maven:
<dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-connector-kafka</artifactId> <version>версия</version> </dependency>
Для Gradle:
dependencies {
implementation 'org.apache.flink:flink-connector-kafka:версия'
}
Конфигурация Kafka
Теперь, когда зависимости добавлены, можно подключить Kafka в вашем коде через SQL-запрос с использованием Flink SQL API.
tableEnv.executeSql(
"CREATE TABLE my_table (" +
" id INT," +
" name STRING," +
" value DOUBLE" +
") WITH (" +
" 'connector' = 'kafka'," +
" 'topic' = 'my-topic'," +
" 'properties.bootstrap.servers' = 'localhost:9092'," +
" 'format' = 'json'" +
")");
Здесь:
properties.bootstrap.servers — это адрес сервера Kafka, с которого Flink будет читать данные;
format указывает формат данных (например, JSON).
Обработка данных через SQL API и Table API
В StreamTableEnvironment можно использовать как SQL-запросы, так и операторы Table API для работы с потоками данных.
Пример обработки данных с помощью SQL API
Table result = tableEnv.sqlQuery("SELECT id, name FROM my_table WHERE value > 50");
result.execute().print();
Эта команда выведет строки данных, где каждый элемент таблицы будет в виде строки, а именно: значения столбцов id и name для всех записей, удовлетворяющих условию value > 50.
Запуск Flink-задачи
После настройки окружения и выполнения SQL-запросов или операций с Table API вы можете запустить задачу Flink.
Пример запуска задачи:
bin/flink run -c my.package.FlinkTableExample my-flink-job.jar
Коротко об Apache Flink
- Apache Flink — это фреймворк для обработки данных, поддерживающий как потоковую, так и пакетную обработку.
- Архитектура Flink включает компоненты: Dispatcher для запуска задач, Job Manager для планирования задач и управления ими, Resource Manager для распределения ресурсов, Task Manager для выполнения задач, JobGraph для описания вычислительных задач, а также механизмы checkpointing и savepoints для восстановления состояния задач.
- Flink поддерживает языки программирования Java, Scala, Python (через PyFlink) и SQL для обработки данных.
- API Flink включает SQL API для работы с потоками данных через SQL-запросы, Table API для декларативной обработки данных, DataStream API для низкоуровневой потоковой обработки и Process Function API для сложной обработки событий и состояния.
- StreamTableEnvironment используется для работы с потоковыми данными через таблицы и выполнение SQL-запросов.
- Flink поддерживает подключение различных источников данных через коннекторы, например Kafka, с возможностью обработки данных через SQL-запросы или Table API.
- Для работы с Flink с Java нужно установить JDK, настроить Flink и зависимости для Maven или Gradle, а также настроить StreamTableEnvironment.
- Запуск задачи Flink осуществляется с помощью команды bin/flink run.