

Что отличает успешный ML-проект от ноутбука в Jupyter, который пылится на GitHub и никому не нужен? Если вы только начинаете свой путь в Data Science, вам может показаться, что главное – это крутой алгоритм. Но опытные инженеры знают: главное – это процесс. Давайте разберем, как превратить хаос экспериментов в работающий бизнес-инструмент.
Рассказываем, что такое CRISP-DM и почему он важен для Data Science.
Почему модели умирают, не родившись?
Представьте ситуацию: вы — талантливый джуниор, к вам приходит менеджер и говорит: «У нас падают продажи. Сделай нам Искусственный Интеллект, чтобы все стало хорошо». Вы, полный энтузиазма, берете данные, чистите их неделю, потом две недели тюните нейросеть, получаете точность 98%… Приносите модель менеджеру, а он смотрит на вас и спрашивает: «А как это поможет нам продавать больше йогуртов в Саратове? И как мы внедрим этот Python-скрипт в нашу кассу 2005 года выпуска?»

Проект провалился. Почему? Не потому, что вы плохой математик, а потому что не было системы. В индустрии существует печальная статистика: по разным оценкам (например, от Gartner или VentureBeat), от 60% до 85% Data Science проектов никогда не доходят до продакшена и остаются «игрушками».
Главная проблема новичков — фокус на коде, а не на решении задачи. Хаотичный перебор алгоритмов без понимания конечной цели — это путь в никуда. Чтобы этого избежать, в конце 90-х годов (да, это древняя, но все еще золотая классика) гиганты индустрии придумали стандарт CRISP-DM (Cross-Industry Standard Process for Data Mining).
Это не про код, а про жизненный цикл проекта. Это карта, которая не даст вам заблудиться в лесу данных.
Что такое CRISP-DM и из каких этапов она состоит?
CRISP-DM — это методология, описывающая процесс работы с данными как цикл из шести этапов. Важно понимать: это не водопад (сделал шаг 1, перешел к шагу 2 и забыл про первый). Это итеративный процесс. Вы постоянно будете возвращаться назад.
Давайте визуализируем этот процесс, чтобы понять связи между этапами.
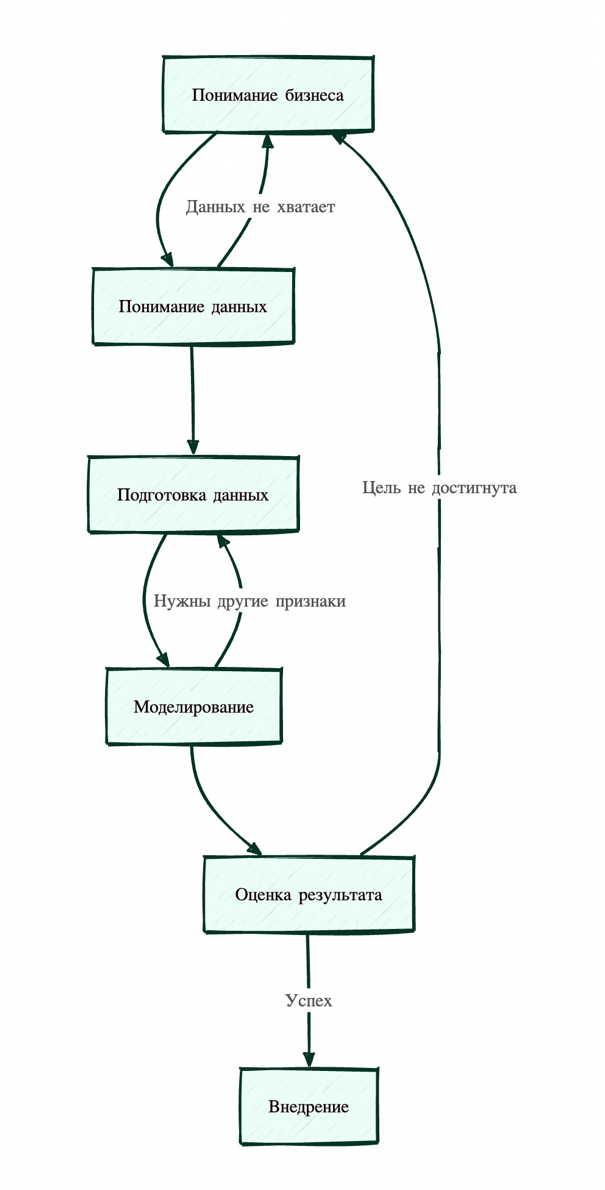
Разберем каждый этап подробно, простым языком.
Этап 1: Business Understanding (Понимание бизнеса)
Самый важный этап, который технари любят пропускать.
- Задача: понять, что на самом деле нужно заказчику.
- Вопросы: какую проблему мы решаем? Как мы будем измерять успех в деньгах/клиентах, а не в метриках ошибки?
- Пример: заказчик просит «предсказать отток». На самом деле ему нужно «сократить потерю денег от ухода VIP-клиентов». Это разные задачи. В первом случае важна точность, во втором – прибыль от удержания минус затраты на удержание.
Этап 2: Data Understanding (Понимание данных)
Разведка боем. Мы смотрим, что у нас есть.
- Задача: сбор первичных данных, описание, поиск закономерностей (EDA – Exploratory Data Analysis), проверка качества.
- Действия: строим гистограммы, ищем пропуски, понимаем, что данные из CRM-системы не стыкуются с данными из Google Analytics.
Этап 3: Data Preparation (Подготовка данных)
Добро пожаловать в ад… шучу (нет). Это этап, который занимает 80% времени любого дата-сайентиста.
- Задача: превратить «грязные» сырые данные в табличку, которую «съест» модель.
- Действия:
- Очистка (удаление дублей, исправление опечаток).
- Заполнение пропусков (Imputation).
- Feature Engineering (создание признаков). Например, превращение даты рождения в возраст.
- Отбор признаков (Feature Selection).
Этап 4: Modeling (Моделирование)
Тот самый этап, ради которого все идут в профессию. Магия ML.
- Задача: выбор алгоритмов, обучение, настройка гиперпараметров.
- Нюанс: часто мы возвращаемся отсюда на этап подготовки. Например, запустили «Случайный лес», поняли, что модель переобучилась, вернулись назад, чтобы удалить шумные признаки.
Этап 5: Evaluation (Оценка результата)
Момент истины. Но не путайте его с model.score().
- Задача: оценить модель не с точки зрения математики, а с точки зрения бизнеса (см. Этап 1).
- Вопрос: решили ли мы проблему? Модель точная, но, если она ошибается, насколько это дорого для бизнеса? Готовы ли мы к внедрению? Если модель предсказывает рак с точностью 90%, но пропускает 10% больных – это может быть неприемлемо. Мы возвращаемся к началу.
Этап 6: Deployment (Внедрение)
Код превращается в продукт.
- Задача: интеграция модели в существующие системы, создание API, дашбордов.
- Финал: модель начинает приносить пользу реальным людям.

Плюсы и минусы использования CRISP-DM в рабочих задачах
Ничто не идеально, даже CRISP-DM. Как опытный специалист, я должен предупредить вас о подводных камнях.
Плюсы
- Универсальность. Неважно, предсказываете вы погоду, курсы акций или поломку станка на заводе – структура одна и та же.
- Фокус на бизнесе. Методология заставляет вас сначала думать «ЗАЧЕМ», а потом «КАК». Это лечит «синдром программиста», который пишет код ради кода.
- Гибкость (Итеративность). CRISP-DM официально разрешает вам делать шаг назад. Если на этапе моделирования вы поняли, что данные плохие – вы легально возвращаетесь к сбору данных, и никто вас за это не уволит. Это часть процесса.
- Понятно менеджерам. Эту схему легко объяснить заказчику, который далек от IT. «Мы сейчас на этапе 3, готовим данные».
Минусы
- Тяжеловесность. Для быстрых экспериментов или маленьких пет-проектов это может быть overkill (избыточно). Если вам нужно за вечер набросать бейзлайн, расписывать бизнес-цели не обязательно.
- Устаревание в эпоху Big Data и MLOps. Оригинальный CRISP-DM был создан в 1999 году. Он мало говорит о том, как поддерживать модель после внедрения (мониторинг, переобучение). Он заканчивается на внедрении, но в современном ML жизнь модели там только начинается.
- Не про управление командой. Это описание процесса работы с данными, а не процесса управления проектом. CRISP-DM не заменит вам Agile, Scrum или Kanban.
Пример использования CRISP-DM на практике
Давайте разберем абстракцию на конкретном живом примере. Допустим, мы работаем в онлайн-кинотеатре (назовем его «КиноПлюс»).
Задача: Пользователи отписываются после бесплатного пробного периода.
1. Business Understanding
- Проблема: высокий отток (Churn) после триала.
- Цель: снизить отток на 5% за квартал.
- Критерий успеха: если мы предложим скидку тем, кто собирается уйти, и они останутся, прибыль должна перекрыть стоимость скидки.
2. Data Understanding
Мы идем к дата-инженерам и просим выгрузки.
- Смотрим логи: кто что смотрел, когда ставил на паузу.
- Смотрим профили: возраст, город, устройство (iPhone или старый Android).
- Инсайт: обнаруживаем, что у нас нет данных о том, обращался ли пользователь в техподдержку. Понимаем, что это важно. Возвращаемся к бизнесу, просим доступ к логам Zendesk.
3. Data Preparation
Самая «грязная» работа.
- У пользователей из разных часовых поясов время просмотра записано по-разному – приводим к UTC.
- Создаем фичи (Feature Engineering):
- days_since_last_login (дней с последнего входа).
- avg_watch_time (среднее время просмотра).
- finished_trial (флаг окончания триала).
- Балансируем классы (ушедших меньше, чем оставшихся).
4. Modeling
Пробуем разные подходы.
- Логистическая регрессия (как базовый уровень).
- CatBoost (потому что хорошо работает с категориями).
- Обучаем, валидируем на отложенной выборке. CatBoost показывает ROC-AUC 0.85.
5. Evaluation
Смотрим на матрицу ошибок.
- Модель часто путает лояльных клиентов с теми, кто хочет уйти (False Positive).
- Бизнес-риск: если мы дадим скидку лояльному клиенту, мы просто потеряем деньги (он бы и так заплатил).
- Решение: настраиваем порог вероятности (Threshold) так, чтобы минимизировать False Positive, даже если немного упадет общий охват. Утверждаем модель с финансистами.
6. Deployment
- Оборачиваем модель в Docker-контейнер.
- Настраиваем процесс: каждое утро модель скорит пользователей, у которых завтра заканчивается триал.
- Те, у кого вероятность ухода > 70%, получают пуш-уведомление: «Останься с нами за полцены!».
Что остается за скобками методологии CRISP-DM?
Как я уже упоминал, CRISP-DM – это дитя 90-х. В современном ML есть огромный пласт задач, который эта методология не покрывает. Если вы хотите быть сеньором, вы должны знать о Post-Deployment проблемах.
- Data Drift и Concept Drift (Дрейф данных и концепций). Мир меняется. Модель для «КиноПлюса», обученная в 2019 году, сломается в 2020-м, когда началась пандемия и паттерны поведения людей изменились. CRISP-DM считает внедрение финалом, но на деле нам нужен мониторинг. Нам нужно постоянно следить, не «протухла» ли модель.
- Этика и Bias (Предвзятость). Методология не говорит о том, этична ли ваша модель. Не дискриминирует ли она пользователей по полу или возрасту? В современных реалиях это критически важный этап аудита.
- Инфраструктура (MLOps). CRISP-DM говорит «Внедрение», но не говорит «Как». CI/CD пайплайны, версионирование данных (DVC), оркестрация (Airflow/Kubeflow) – все это техническая «обвязка», без которой процесс не поедет.
Поэтому сейчас часто говорят о расширении методологии до CRISP-ML(Q), где добавляются этапы мониторинга и контроля качества.
Коротко о CRISP-DM
Друзья, математика и алгоритмы – это сердце Data Science. Но CRISP-DM – это скелет, на котором все держится.
Без четкой структуры даже самая гениальная нейросеть останется бесполезным куском кода. Если вы хотите расти в профессии:
- Всегда начинайте с вопроса «Зачем это бизнесу?».
- Не бойтесь возвращаться на предыдущие этапы – это нормально.
- Помните, что 80% успеха – это чистые данные, а не сложная модель.
Используйте CRISP-DM как чек-лист в своих проектах, будь то хакатон, курсовая или реальная работа – это покажет ваш профессионализм и зрелость.