
Apache Spark или просто Spark — это фреймворк (ПО, объединяющее готовые компоненты большого программного проекта), который используют для параллельной обработки неструктурированных или слабоструктурированных данных.

Например, если нужно обработать данные о годовых продажах одного магазина, то программисту хватит одного компьютера и кода на Python, чтобы произвести расчет. Но если обрабатываются данные от тысяч магазинов из нескольких стран, причем они поступают в реальном времени, содержат пропуски, повторы, ошибки, тогда стоит использовать мощности нескольких компьютеров и Spark. Группа компьютеров, одновременно обрабатывающая данные, называется кластером, поэтому Spark также называют фреймворком для кластерных вычислений.

Зачем нужен Spark
Области использования Spark — это Big Data и технологии машинного обучения, поэтому им пользуются специалисты, работающие с данными, например дата-инженеры, дата-сайентисты и аналитики данных.
Примеры задач, которые можно решить с помощью Spark:
- изучить потребительское поведение;
- спрогнозировать прибыль и финансовые риски;
- обработать данные сенсоров и датчиков в системе интернета вещей;
- проанализировать информацию о транзакциях, безопасности финансовых операций и утечках.
Spark поддерживает языки программирования Scala, Java, Python, R и SQL. Сначала популярными были только первые два, так как на Scala фреймворк был написан, а на Java позже была дописана часть кода. С ростом Python-сообщества этим языком тоже стали пользоваться активнее, правда обновления и новые фичи в первую очередь доступны для Scala-разработчиков. Реже всего для работы со фреймворком используют язык R.
В структуру Spark входят ядро для обработки данных и набор расширений:
- Spark Core или ядро — это как раз движок. Он отвечает за хранение данных, управление памятью, распределение и отслеживание задач в кластере;
- MLlib — набор библиотек для машинного обучения;
- SQL — компонент, который отвечает за запрос данных;
- GraphX — модуль для работы с графами (абстрактными представлениями связей между множеством объектов);
- Streaming — средство для обработки потоков Big Data в реальном времени.
Как работает Spark
Спарк интегрирован в Hadoop — экосистему инструментов с открытым доступом, в которую входят библиотеки, система управления кластером (Yet Another Resource Negotiator), технология хранения файлов на различных серверах (Hadoop Distributed File System) и система вычислений MapReduce. Классическую модель Hadoop MapReduce и Spark постоянно сравнивают, когда речь заходит об обработке больших данных.

Принципиальные отличия Spark и MapReduce
Hadoop MapReduce
Быстрый
Пакетная обработка данных
Хранит данные на диске
Написан на Java
Spark
В 100 раз быстрее, чем MapReduce
Обработка данных в реальном времени
Хранит данные в оперативной памяти
Написан на Scala
Пакетная обработка в MapReduce проходит на нескольких компьютерах (их также называют узлами) в два этапа: на первом головной узел обрабатывает данные и распределяет их между рабочими узлами, на втором рабочие узлы сворачивают данные и отправляют обратно в головной. Второй шаг пакетной обработки не начнется, пока не завершится первый.
Обработка данных в реальном времени с помощью Spark Streaming — это переход на микропакетный принцип, когда данные постоянно обрабатываются небольшими группами.
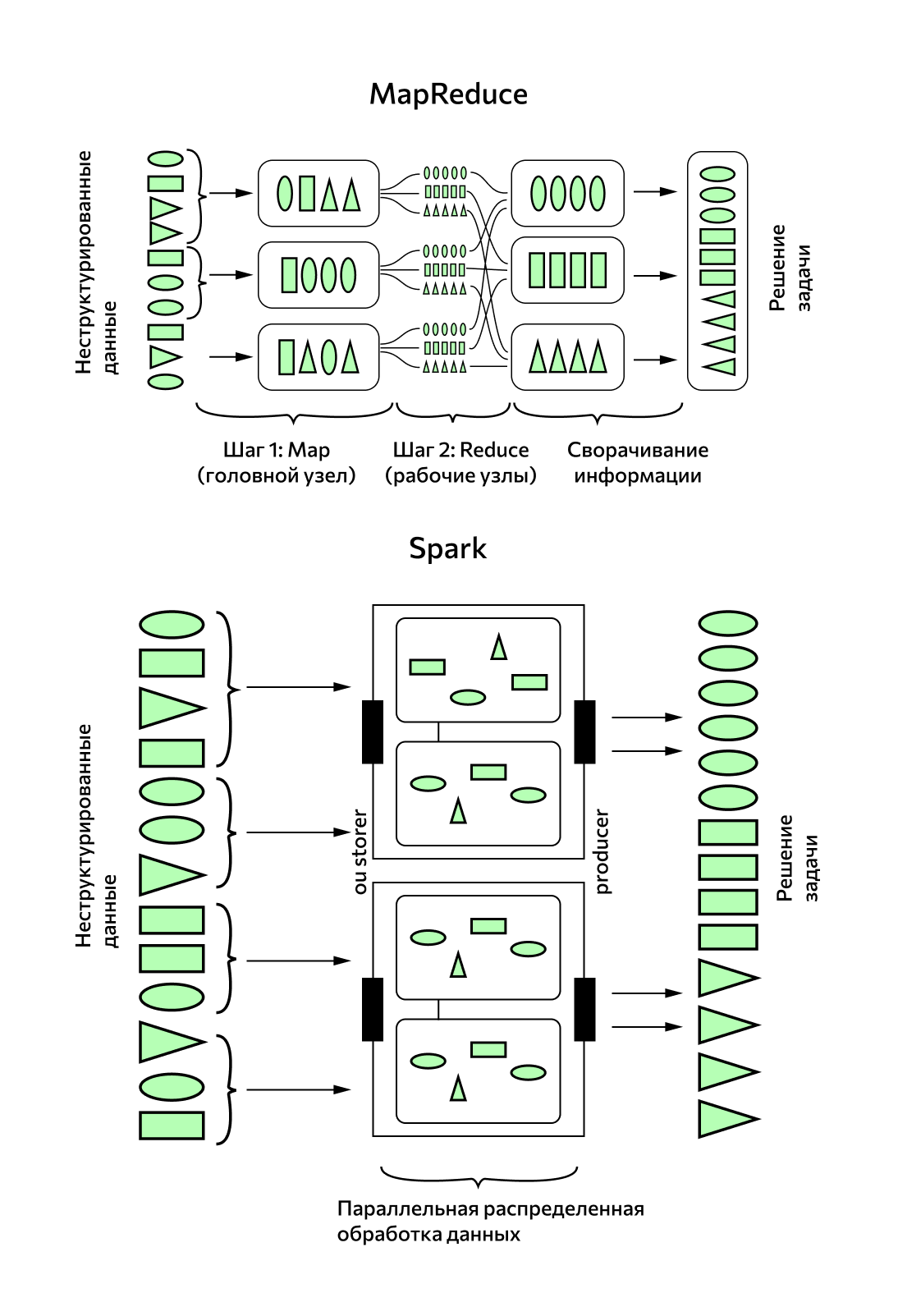
Кроме этого, вычисления MapReduce производятся на диске, а Spark производит их в оперативной памяти, и за счет этого его производительность возрастает в 100 раз. Однако специалисты предупреждают, что заявленная «молниеносная скорость работы» Spark не всегда способна решить задачу. Если потребуется обработать больше 10 Тб данных, классический MapReduce доведет вычисление до конца, а вот у Spark может не хватить памяти для такого вычисления.
Но даже сбой в работе кластера не спровоцирует потерю данных. Основу Spark составляют устойчивые распределенные наборы данных (Resilient Distributed Dataset, RDD). Это значит, что каждый датасет хранится на нескольких узлах одновременно и это защищает весь массив.
Разработчики говорят, что до выхода версии Spark 2.0 платформа работала нестабильно, постоянно падала, ей не хватало памяти, и проблемы решались многочисленными обновлениями. Но в 2021 году специалисты уже не сталкиваются с этим, а обновления в основном направлены на расширение функционала и поддержку новых языков.
Как правильно?
✅ «Наша компания использует Spark для прогнозирования финансовых рисков»
❌ «Я учусь работать в программе Spark»

0 комментариев